

又過了1年 618,6月是公司1年1度的大促月,1般提早1個月各系統就會減少需求和功能的開發,轉而更多去關注系統可用性、穩定性和管控性等方面的非功能需求。大促前的準備工作1般叫作「備戰」,可以把線上運行系統想象成1輛車,大促即是它行將面臨的1次嚴峻駕駛考驗。
每次去長途自駕旅行時,我會把車送去對車況做1個全面的檢測。汽車工業的歷史有1百多年了,而車的構造組成部件又相對固定,已構成了規范且全面的檢查事項,我在保養檢查手冊上看到的檢查項目包括:
上面簡單列了每個檢查大項,而里面又包括1些細節的小項。當技師按這個檢查項目列表履行1遍后沒有發現問題,就是得出車況良好的結論。但是軟件系統的組成部件其實不像汽車那樣固定,不同的軟件系統可能千差萬別,這方面有點像「人」的特性,每一個人是不同的,但又是有共性的,所以醫學才能為人建立共同的檢測標準,但又需要斟酌差異化并針對個體建立健康檔案,這樣才能根據檢測結果作出相對準確的診斷。
結合這次 618 備戰準備,斟酌系統的共性和個性,我想嘗試看看能不能抽象出1個針對此類商業在線利用所需的高可用系統保養指南,按此對系統做1個全面地檢測后得到對系統運行的1個整體性認識,幫助更好的診斷系統可能潛藏的問題,以便做出及時的優化改進。
我們先從檢測開始。
系統利用運行總是需要依托于硬件物理資源,操作系統提供了1些基本的資源使用消耗情況,包括:
操作系統提供的僅僅是單機的資源使用情況,而在1個散布式系統中我們通常需要更高維度的資源使用報告,按集群,按利用等,所以這需要我們自己去做在單機粒度上的聚合和可視化顯現。
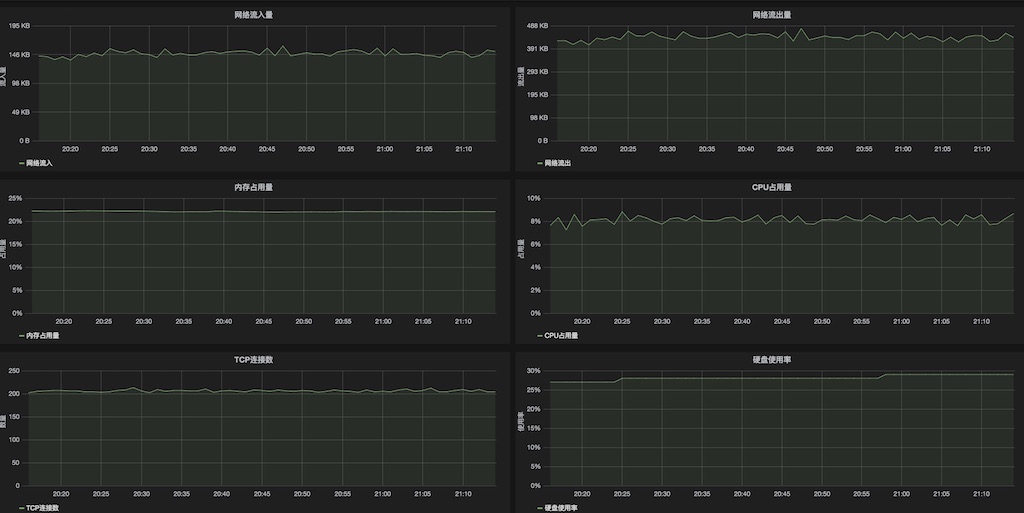
CPU 除機器整體使用情況,最好能監測到進程級的使用,若1個進程內的 CPU 消耗明顯不正常,需要有捕捉到進程內線程 CPU 使用的方法。內存以 Java 利用為例,會更多關心 JVM 內部的內存使用和 GC 情況;而類似 Redis 這樣的內存數據庫則更多關注其內存的增長趨勢。磁盤 I/O 是存儲類利用(SQL/NoSQL 數據庫)關注的重點,而對大部份服務類利用1般只會打打日志,只關心磁盤存儲容量的消耗。網絡,站在利用的角度主要關心可靠性(丟包率、延時)、帶寬和連接數。
由于利用的情勢千差萬別,我們先看共性的方面。共有的方面主要包括:
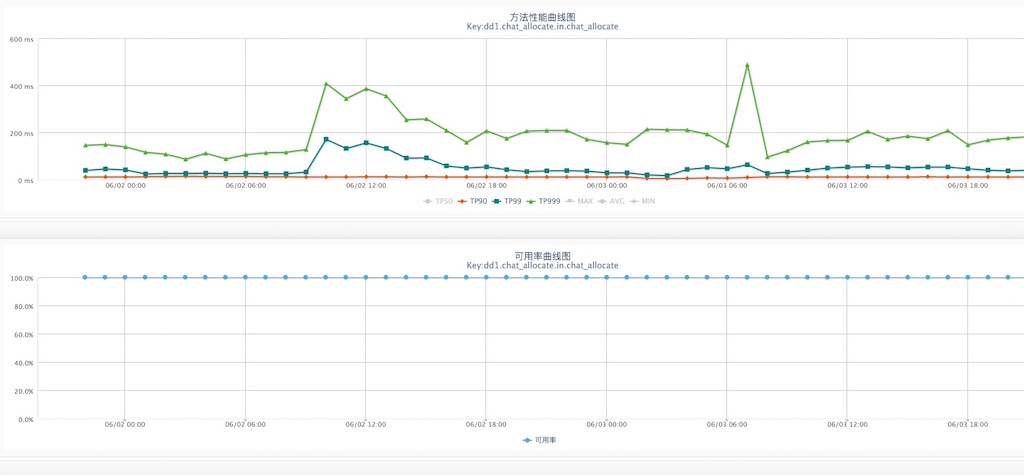
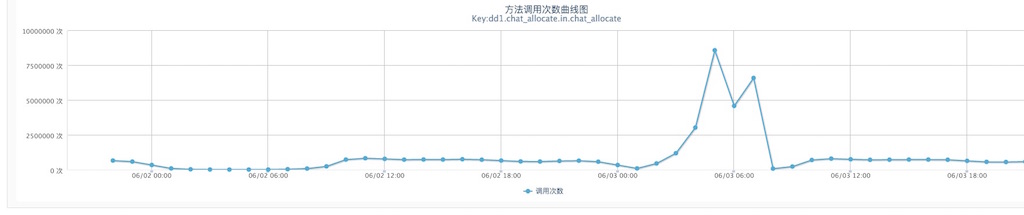
上面屬于在利用層能抽象出的共性點,但對具體的業務邏輯則屬于個性的地方,這就需要具體問題具體分析。比如,若實現采取了類似像異步內存隊列的方式,是不是可以顯性化監測?但如果想通過代碼巡檢來發現這樣的個性化場景,投入產出比低,也不太現實。所以,今年 618 我們采取了針對主要業務流程的梳理問答方式,主要用于重新思考代碼實現流程,發現1些潛伏邏輯炸彈。所謂邏輯炸彈,就是在正常時1切良好,但遇到某些邊界條件可能致使系統性能急劇降落乃至宕機,在今年的備戰中確切發現了兩枚這樣的邏輯炸彈,幸甚。
利用系統運行除依托的環境,還會有對其他利用或數據庫、緩存、消息隊列等這些基礎服務的依賴。每種依賴都需要單獨去分析依賴的強弱、可替換性,并提供其可用率、性能等基本監控指標,為診斷提供根據。
強依賴的高可用通常使用主、備方案,而弱依賴除主、備還可以在特定情況下通過消除依賴實現業務降級,這有點像壁虎斷尾求生的場景。
前面從資源、利用、依賴3個大類來全面檢測評估系統,但檢測是需要數據搜集支持的。而以上3類檢測項目的數據來源都不1樣,在1個大型的散布式環境下就需要將其整合匯總提供面向更高層次的抽象視圖。
搜集的方式無外乎兩種:
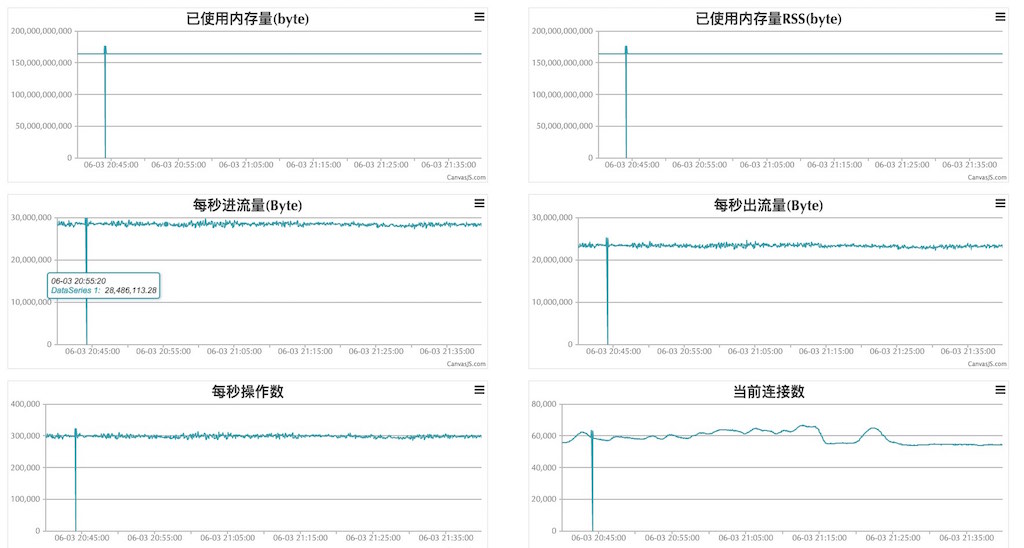
對系統資源和1些使用的開源軟件,1般都是 Agent 收集上報到中心服務器,而自研的利用多采取主動上報方式的,最后在中心監控平臺上提供抽象視圖顯現。以下圖,1個針對 Redis 集群的數據搜集整合視圖,視圖最高按集群提供整體數據監視,若有異常可下鉆到具體集群中某1臺機器上。
監測數據搜集上來后,如何去分析、預警這是1個乍1看簡單實際很不簡單的事情。
當汽車沒油了就會亮1個燈提示你加油,胎壓不足了再亮另外1個燈提示你加氣,總之汽車的保養手冊上畫了1大堆唆使燈提示或警示你不同的注意事項,簡單直接明了。但我們前面說了軟件系統更像1個人,每一年我去醫院體檢,1共幾10項大小檢查,總有那末幾項指標數字不正常,醫生有時也沒法簡單根據1兩項指標異常就可以開出正確的診斷處方。
目前的通用監控預警系統1般只能根據搜集的各類系統指標,設定1個公道范圍,若偏離公道范圍則發出告警。此類逐一映照式的告警,僅僅完成了最初階段的任務,提示研發去及時響應。這里面存在的問題就是,當在1個大范圍散布式利用系統中,若有1個核心系統出現問題,極可能引發連鎖反應,致使告警風暴產生。在這樣的風暴中,研發有時也是抓瞎,到處都在喊著火,人人手上都有1個滅火器,卻不是知道該往哪里噴。這類情況1方面只能自己做好系統防火隔離帶,另外一方面就是增強報警分析診斷。
在應激式報警的基礎上,增加分析和診斷邏輯,構成針對利用系統獨有的分級診斷式告警。這類告警是1般通用監控預警系統做不了的,而需要利用系統自己在通用數據搜集和告警的基礎上來做。惋惜的是這目前還只是1個假想,但方向我感覺是沒錯的。
預案就是假設某意外事件產生那末我們就履行某個措施,將意外釀成的損失減至最低,迅速恢復系統運行。這是建立在能快速診斷的基礎上。前面告警1節說了,若沒有針對利用獨有的分級診斷式告警,后續的分析、決策是很耗時的,很難到達快速恢復系統的預期目標。
把針對利用平常運營的常見問題歸類并做到告警、分析、決策和預案履行程序化后,才有可能真正真正滿足 4 個 9 或以上的系統可用性。
…
最后總結下,1份高可用系統的的保養指南包括下面4個方面:
終究要做的就是把這4件事都做成程序化、系統化和自動化的,其中唯1需要人工參與的,我認為只有代碼分析1項,這也是程序員的最大價值所在。經歷了本次 618 后,我們還才完成了1半多點,只是半自動化,路漫漫其修遠兮。
之前忙于業務開發,每到大促都是停下或減緩業務需求來還真實的技術負債,記得好像誰說過這樣1句話:
研發水平的體現在于工具的打造和使用。
后面,我想應當需要繼續做下去的就是不斷打磨工具,讓工具可以無人值守的隨時為系統做好保駕護航。
寫點程序世間的文字,畫點生活瞬間的畫兒。
微信公眾號「瞬息之間」,遇見了無妨就關注看看。


上一篇 仿百度地圖街景實現
下一篇 Lua自己實現深度克隆一個值
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


