
終究進入我們的主題了ConvNets或CNNs,它的結構和普通神經網絡都1樣,之前我們學習的各種技能方法都適用,其主要不同的地方在于:
ConvNet假定輸入的是圖片,我們根據圖片的特性對網絡進行設定以到達提高效力,減少計算參數量的目的。
首先我們分析下傳統神經網絡對圖片的處理,如果還是用CIFAR⑴0上的圖片,共3072個特點,如果普通網絡結構輸入那末第1層的每個神經單元都會有3072個權重,如果更大的像素的圖片進入后參數更多,而且用于圖片處理的網絡1般深度達10層之上,加在1起參數的量實在太大,參數過量也會造成過擬合,而且圖片也有本身的特點,我們需要利用這些特點,將傳統網絡改革,加快處理速度和精確度。
我們注意到圖片的像素是由3個通道構成的,我們就利用了這個特點將其神經元安置到了3維空間(width, height, depth),分別對應著圖片的32x32x3(以CIFAR為例)以下圖:
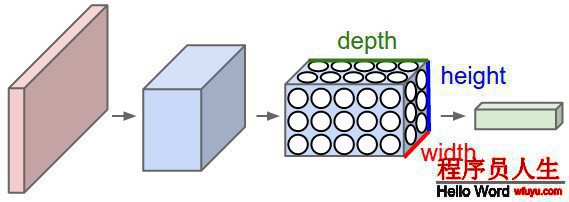
紅色是輸入層這里的深度是3,輸出層是1x1x10的結構。其他幾層的含義后面會介紹,現在先知道每層都是height × width × depth結構。
卷積神經網絡有3種層:卷積層、池化層和全連接層(Convolutional Layer, Pooling Layer, 及 Fully-Connected Layer)。
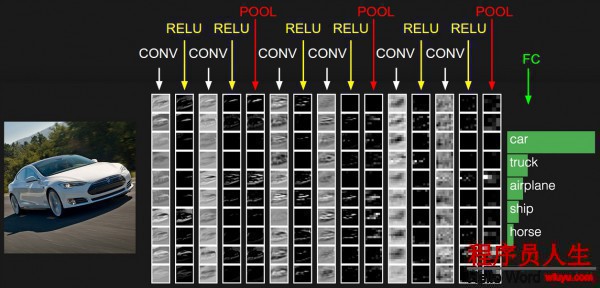
以處理CIFAR⑴0的卷積神經網絡為例,簡單的網絡應包括這幾層:
[INPUT - CONV - RELU - POOL - FC]也就是[輸入-卷積-激活-池化-分類得分],各層分述以下:
注意:
1. 卷及神經網絡包括不同的層 (e.g. CONV/FC/RELU/POOL 也是最受歡迎的)
2. 每層都輸入輸出3d結構的數據,除最后1層
3. 有些層可能沒有參數,有些層可能有參數 (e.g. CONV/FC do, RELU/POOL don’t)
4. 有些層可能有超參數有些層也可能沒有超參數(e.g. CONV/FC/POOL do, RELU doesn’t)
下圖是1個例子,沒法用3維表示只能展成1列的情勢了。
下面展開討論各層具體細節:
卷積層是卷積神經網絡的核心層,大大提高了計算效力。
卷積層由很多過濾器組成,每一個過濾器都只有1小部份,每次只與原圖象上的1小部份連接,UFLDL上的圖:
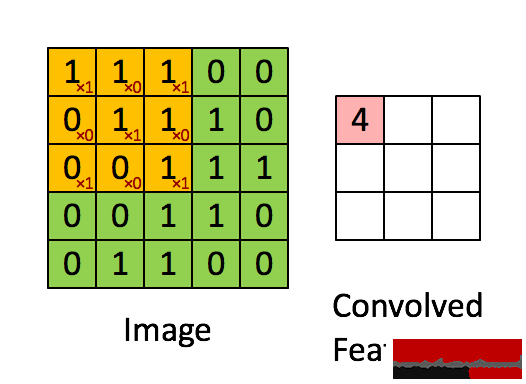
這是1個過濾器不停滑動的結果,
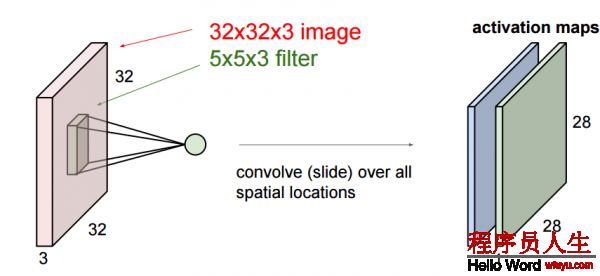
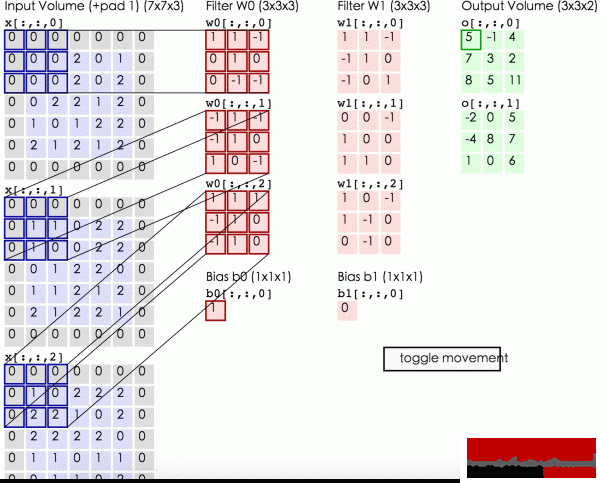
我們這里要更深入些,我們輸入的圖象是1個3維的,那末每一個過濾器也是有3個維度,假定我們的過濾器是5x5x3的那末我們也會得到1個類似于上圖的激活值的映照也就是convolved feature 下圖中叫作 activion map,其計算方法是
我們可以有多個過濾器:
更深入1些,當我們滑動的時候有3個超參數:
1. 深度,depth,這是過濾器的數量決定的。
2. 步長,stride,每次滑動的間隔,上面的動畫每次只滑動1個數,也就是步長為1.
3. 補零數, zero-padding,有時候根據需要,會用零來拓展圖象的面積,如果補零數為1,變長就+2,以下圖中灰色的部份就是補的0
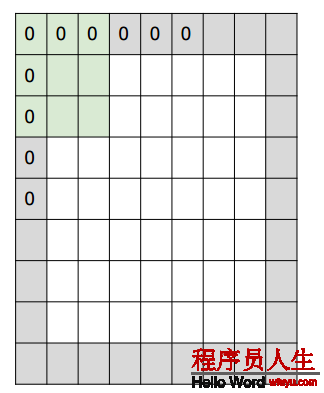
下面是1個1維的例子:
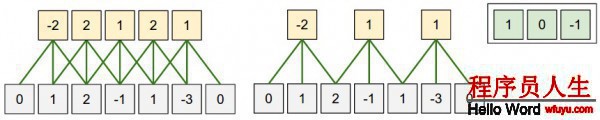
其輸出的空間維度計算公式是

上面可以知道在卷積層以后得到的結果還是挺多,而且由于滑動窗口的存在,很多信息也有重合,因而有了池化pooling 層,他是將卷積層得到的結果無重合的分來幾部份,然后選擇每部份的最大值,或平均值,或2范數,或其他你喜歡的值,我們以取最大值的max pool為例:
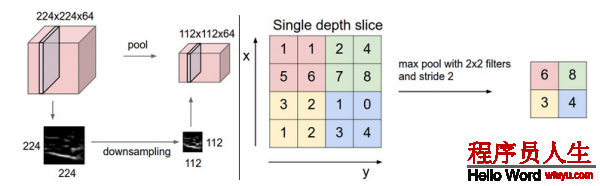
- 反向傳播:最大值的梯度我們之前在反向傳播的時候就已學習過了,這里1般都跟蹤最大的激活值,這樣在反向傳播的時候會提高效力.
- Getting rid of pooling. 1些人認為pooling是沒有必要的,如The All Convolutional Net ,很多人認為沒有池層對生成式模型(generative models)很重要,仿佛以后的發展中,池層可能會逐步減少或消失。
全連接層和卷積層除連接方式不1樣,其計算方式都是內積,可以相互轉換:
1. FC如果做CONV layer 的工作就相當于其矩陣的多數位置都是0(稀疏矩陣)。
2. FC layer 如果被轉變成 CONV layer. 相當于每層的局部連接變成了全部鏈接如FC layer with K=4096的輸入是7×7×512那末對應的卷積層為 F=7,P=0,S=1,K=4096輸出為1×1×4096。
例子:
假定1個cnn輸入 224x224x3圖象,經過若干變化以后某1層輸出 7x7x512 到這里以后使用兩4096的FC layer及最后1個1000的FC計算分類得分下面是把這3層fc轉化為Conv 的進程:
1. 使用 F=7的conv layer 輸出為 [1x1x4096];
2. 使用F=1的過濾器,輸出為 [1x1x4096];
3. 使用F=1的卷積層,輸出為 [1x1x1000]。
每次轉化都會將FC的參數轉變成conv的參數情勢. 如果在轉變后的系統中傳入更大的圖片,也會非常快速的向前運算。例如將384x384的圖象輸入上面的系統,會在最后3層之前得到[12x12x512]的輸出, 經過上面轉化的conv 層會得到 [6x6x1000], ((12 - 7)/1 + 1 = 6). 我們1下就得出了6x6的分類結果。
這樣1次得到的比原來使用迭代36次得到的要快。這是實際利用中的技能。
另外我們可以用兩次步長16的卷積層代替1次步長為32的卷積層來輸入上面的圖片,提高效力。
下面我們就用CONV, POOL,FC ,RELU 搭建1個卷積神經網絡:
我們依照以下結構搭建
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC其中N >= 0 (1般N <= 3), M >= 0, K >= 0 (1般K < 3).
這里要注意:我們更偏向于使用多層小size的CONV。
為何呢?
比如3個3x3的和1個7x7的conv層,他們都可以 得到7x7的receptive fields.但是3x3的有以下優點:
1. 3層的非線性組合要比1層線性組合表達能力強;
2. 3層小尺寸的卷積層的參數數量要少,3x3x3<7x7;
3. 反向傳播中我們需要使用更多的內存來貯存中間層結果。
值得注意的是Google’s Inception architectures 及Residual Networks from Microsoft Research Asia. Both 等創造了相比以上結構更加復雜的連接結構。
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters注意到內存使用最多的時候在開始幾個CONV layers, 參數基本都在最后幾個FC層第1個FC有100M個!
內存主要在以下幾個方面消耗較多
1. 大量的激活值和梯度值。測試時可以只貯存當前的激活值拋棄之前的在下方幾層激活值會大大減少激活值的貯存量。
2. 參數的貯存,在反向傳播時的梯度及使用 momentum, Adagrad, or RMSProp時的緩存都會占用貯存,所以估計參數使用的內存時1般最少要乘以3倍
3. 每次網絡運行都要記住各種信息比如圖形數據的批量等
如果估計網絡需要的內存太大,可以適當減小圖片的batch,畢竟激活值占用了大量的內存空間。
總結

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


