
FISTA(A fast iterative shrinkage-thresholding algorithm)是1種快速的迭代閾值收縮算法(ISTA)。FISTA和ISTA都是基于梯度降落的思想,在迭代進程中進行了更加聰明(smarter)的選擇,從而到達(dá)更快的迭代速度。理論證明:FISTA和ISTA的迭代收斂速度分別為O(1/k2)和O(1/k)。
本篇博文先從解決優(yōu)化問題的傳統(tǒng)方法“梯度降落”開始,然后引入ISTA,再上升為FISTA,最后在到其利用(主要在圖象的去模糊方面和特點匹配)。文章主要參考資料以下:
[1] A
Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems。
[2] Proximal Gradient Descent for L1 Regularization
[3] 線性回歸及梯度下
-------------------------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------我是分割線--------------------------------------------------------
斟酌以下線性轉(zhuǎn)換問題:b = Ax + w (1)
例如在圖象模糊問題中,A為模糊模板(由未模糊圖象通過轉(zhuǎn)換而來),b為模糊圖象,w為噪聲。并且,A和b已知,x為待求的系數(shù)。
求解該問題的的傳統(tǒng)方法為最小2乘法,思想很簡單粗魯:使得重構(gòu)誤差||Ax-b||2最小。即:
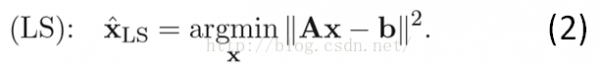
對f(x) = ||Ax-b||2求導(dǎo),可得其導(dǎo)數(shù)為:f'(x) = 2AT(Ax-b)。對該問題,令導(dǎo)數(shù)為零便可以獲得最小值(函數(shù)f(x)為凸函數(shù),其極小值即為最小值)。
1)如果A為非奇特矩陣,即A可逆的話,那末可得該問題的精確解為x=A⑴b。
2)如果A為奇特矩陣,即A不可逆,則該問題沒有精確解。退而求其次,我們求1個近似解就好,||Ax-b||2<=?。
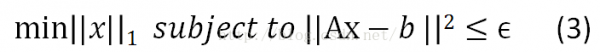
其中,||x||_1為懲罰項,用以規(guī)范化參數(shù)x。該例子使用L1范數(shù)作為懲罰項,是希望x盡可能稀疏(非零元素個數(shù)盡量少),即b是A的1個稀疏表示。||Ax-b||2<=?則為束縛條件,即重構(gòu)誤差最小。問題(3)也能夠描寫為:
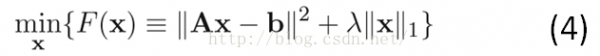
式子(4)即為1般稀疏表示的優(yōu)化問題。希望重構(gòu)誤差盡量小,同時參數(shù)的個數(shù)盡量少。
注:懲罰項也能夠是L2或其他范數(shù)。
斟酌更加1般的情況,我們來討論梯度降落法。有沒有束縛的優(yōu)化問題以下:
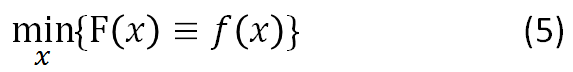
梯度降落法基于這樣的視察:如果實值函數(shù)F(x)在點a處可微且有定義,那末函數(shù)F(x)在點a沿著梯度相反的方向-?F(a)降落最快。
基于此,我們假定f(x)連續(xù)可微(continuously differentiable)。如果存在1個足夠小的數(shù)值t>0使得x2 = x1 - t?F(a),那末:
F(x1) >= F(x2)
梯度降落法的核心就是通過式子(6)找到序列{xk},使得F(xk) >= F(xk⑴)。
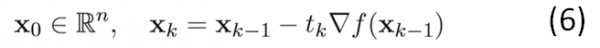
下圖詳細(xì)說明了梯度降落的進程:
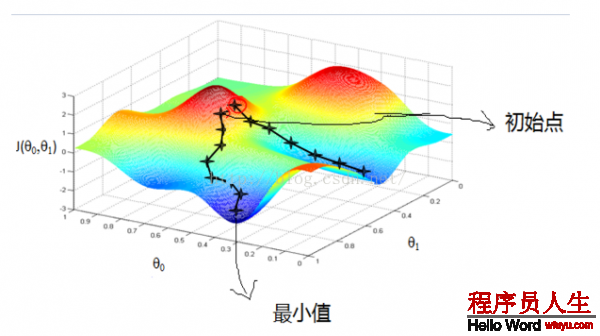
從上圖可以看出:初始點不同,取得的最小值也不同。由于梯度降落法求解的是局部最小值,受初值的影響較大。如果函數(shù)f(x)為凸函數(shù)的話,則局部最小值亦為全局最小值。這時候,初始點只對迭代速度有影響。
再回頭看1下式子(6),我們使用步長tk和導(dǎo)數(shù)?F(xk)來控制每次迭代時x的變化量。再看1下上面那張圖,彩色繽紛那張。對每次迭代,我們固然希望F(x)的值降得越快越好,這樣我們就可以更快速得取得函數(shù)的最小值。因此,步長tk的選擇很重要。
如果步長tk太小,則找到最小值的迭代次數(shù)非常多,即迭代速度非常慢,或說迭代的收斂速度很慢;而步長太大的話,則會出現(xiàn)overshoot the minimum的現(xiàn)象,即不斷在最小值左右徘徊,跳來跳去的,以下圖所示:

但是,tk最后還是作用在xk⑴上,得到xk。因此,更加樸素的思想應(yīng)當(dāng)是:序列{xk}的個數(shù)盡量小,即每次迭代步伐盡量大,函數(shù)值減少得盡量多。那末就是關(guān)于序列{xk}的選擇了,如何更好的選擇每個點xk,使得函數(shù)值更快的趨近其最小值。
-----------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------我是分割線--------------------------------------------------------
ISTA和FISTA求解最小化問題的思想就是基于梯度降落法的,它們的優(yōu)化在于對{xk}的選擇上。這里我們不講證明,只講思想。想看證明的話,請看參考資料[1]。
ISTA(Iterative shrinkage-thresholding algorithm),即迭代閾值收縮算法。
先從無束縛的優(yōu)化問題開始,即上面的式子(5):
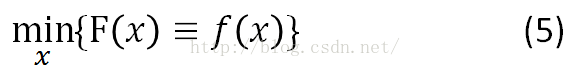
這時候候,我們還假定了f(x)滿足Lipschitz連續(xù)條件,即f(x)的導(dǎo)數(shù)有下界,其最小下界稱為Lipschitz常數(shù)L(f)。這時候,對任意的L>=L(f),有:
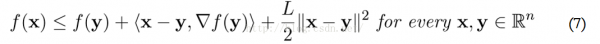
基于此,在點xk附近可以把函數(shù)值近似為:
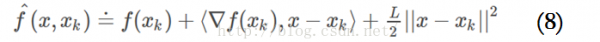
在梯度降落的每步迭代中,將點xk⑴處的近似函數(shù)獲得最小值的點作為下1次迭代的起始點xk,這就是所謂的proximal regularization算法(其中,tk=1/L)。
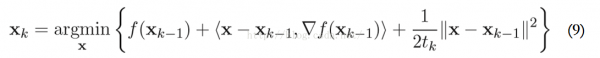
上面的方法只合適解決非束縛問題。而ISTA要解決的可是帶懲罰項的優(yōu)化問題,引入范數(shù)規(guī)范化函數(shù)g(x)對參數(shù)x進行束縛,以下:
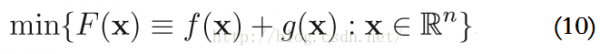
使用更加1般的2次近似模型來求解上述的優(yōu)化問題,在點y,F(xiàn)(x) := f(x) + g(x)的2次近似函數(shù)為:
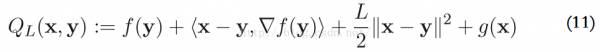
該函數(shù)的最小值表示為,P_L是proximal(近端算子)的簡寫情勢:
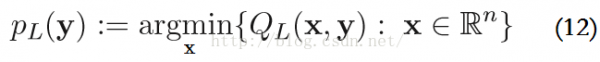
疏忽其常數(shù)項f(y)和?F(y),這些有和沒有對結(jié)果沒有影響。再結(jié)合式子(11)和(12),PL(y)可以寫成:
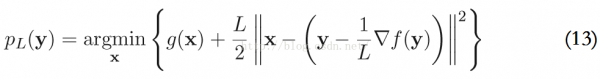
明顯,使用ISTA解決帶束縛的優(yōu)化問題時的基本迭代步驟為:
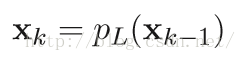
固定步長的ISTA的基本迭代步驟以下(步長t = 1/L(f)):

但是,固定步長的ISTA的缺點是:Lipschitz常數(shù)L(f)不1定可知或可計算。例如,L1范數(shù)束縛的優(yōu)化問題,其Lipschitz常數(shù)依賴于ATA的最大特點值。而對大范圍的問題,非常難計算。因此,使用以下帶回溯(backtracking)的ISTA:

理論證明:ISTA的收斂速度為O(1/k);而FISTA的收斂速度為O(1/k2)。實際利用中,F(xiàn)ISTA亦明顯快于ISTA。其證明進程還是看這篇文章:[1]。
FISTA(A fast iterative shrinkage-thresholding algorithm)是1種快速的迭代閾值收縮算法(ISTA)。
FISTA與ISTA的區(qū)分在于迭代步驟中近似函數(shù)起始點y的選擇。ISTA使用前1次迭代求得的近似函數(shù)最小值點xk⑴,而FISTA則使用另外一種方法來計算y的位置。理論證明,其收斂速度能夠到達(dá)O(1/k2)。固定步長的FISTA的基本迭代步驟以下:
固然,斟酌到與ISTA一樣的問題:問題范圍大的時候,決定步長的Lipschitz常數(shù)計算復(fù)雜。FISTA與ISTA1樣,亦有其回溯算法。在這個問題上,F(xiàn)ISTA與ISTA并沒有區(qū)分,上面也說了,F(xiàn)ISTA與ISTA的區(qū)分僅僅在于每步迭代時近似函數(shù)起始點的選擇。更加簡明的說:FISTA用1種更加聰明的辦法選擇序列{xk},使得其基于梯度降落思想的迭代進程更加快速地趨近問題函數(shù)F(x)的最小值。
帶回溯的FISTA算法基本迭代步驟以下:

值得注意的是,在每步迭代中,計算近似函數(shù)的起止點時,F(xiàn)ISTA使用前兩次迭代進程的結(jié)果xk⑴,xk⑴,對其進行簡單的線性組合生成下1次迭代的近似函數(shù)起始點yk。方法很簡單,但效果卻非常好。固然,這也是有理論支持的。
-----------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------我是分割線--------------------------------------------------------
LASSO是1個圖象處理中經(jīng)典的目標(biāo)方程
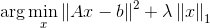
第2項的1范數(shù)限制了x的稀疏性,前文已說過,在此不再敘述。

比如在圖象去模糊的問題中,已知模糊的圖象b,和模糊函數(shù)R,我們想恢復(fù)去模糊的圖象I。這些變量的關(guān)系可以表達(dá)成I*R=b,其中*為卷積。在理想狀態(tài)下,b沒有任何噪音,那末這個問題就很簡單。基于卷積定理,兩個函數(shù)在時域的卷積相當(dāng)于頻域的相乘,那末我們只需要求出b和R的傅里葉變換,然后相除得到I的傅里葉變換,再將其恢復(fù)到時域。但是1般來講模糊圖象b含有噪聲,這使得頻域中的操作異常不穩(wěn)定,所以更多時候,我們希望通過以下方程求得I
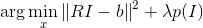
其中模糊算子R表現(xiàn)成矩陣情勢,I和b表示為1維向量,函數(shù)p作為規(guī)范項。我們將I小波分解,I=Wx,其中W為小波基,x為小波基系數(shù)。我們知道圖象的小波表示是稀疏的,那末目標(biāo)方程就變成了LASSO的情勢
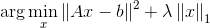
其中A=RW。現(xiàn)在的問題是,這個方程由于L1范數(shù)的存在,不是處處可微的,如果用subgradient的方法,收斂的速度會很慢。
因此我們用ISTA(Iterative Shrinkage-Thresholding Algorithm)。這個算法可以解決以上f+g情勢的最小化問題,但I(xiàn)STA適用于以下情勢問題的求解:
1.目標(biāo)方程是f+g的情勢
2.f和g是凸的,f是可導(dǎo)的,g無所謂
3.g需要足夠簡單(可拆分的,可以做坐標(biāo)降落的coordinate descent)
因而,我們首先看對f做1般的遞歸降落。我們可以參照(13)式,即可以得到:
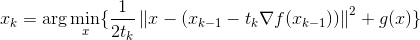
這時候我們可以看到,假設(shè)g是1個開拆分的函數(shù)(比如L1范數(shù)),我們就能夠?qū)γ烤S分別進行坐標(biāo)降落,也就是將N維的最小值問題,轉(zhuǎn)化成N個1D的最小值問題。我們發(fā)現(xiàn),如果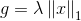 的話,那末這個問題有解析解,即每步的迭代可以寫成:
的話,那末這個問題有解析解,即每步的迭代可以寫成:
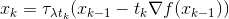
其中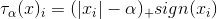 稱作shrinkage operator。
稱作shrinkage operator。
FISTA其實就是對ISTA利用Nestrerov加速。1個普通的Nestrerov加速遞歸降落的迭代步驟是:

利用到FISTA上的話,就是把第3步換成ISTA的迭代步驟。可以證明FISTA可以到達(dá)1/(t^2)的收斂速度。(t是迭代次數(shù))通過下面的實驗可以看到,一樣迭代了300次,左圖(ISTA)仍未收斂,圖象依然模糊。而右圖(FISTA)已基本還原了去模糊的原圖。


-----------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------我是分割線--------------------------------------------------------
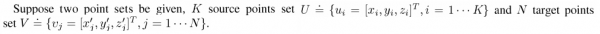
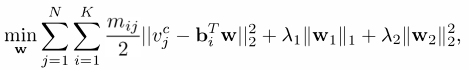
f is the transformation function between U and V. Then we can see that:

through the above function. We can get:
=========================
參考自:
1、Junhao_wu: http://www.cnblogs.com/JunhaoWu/p/Fista.html
2、Beyond Algorithm is Math : http://blog.csdn.net/iverson_49/article/details/38354961

上一篇 C#三十五 三層架構(gòu)企業(yè)應(yīng)用
下一篇 CS231n 卷積神經(jīng)網(wǎng)絡(luò)與計算機視覺 9 卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)分析
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


