
前邊我們介紹了Hadoop項目的兩大基礎(chǔ)支柱HDFS和MapReduce,隨后又介紹了子項目Pig:1種用類似于SQL的、面向數(shù)據(jù)流的語言對HDFS下的數(shù)據(jù)進行處理的MapReduce上層客戶端,這大大滿足了那些不會Java,不會寫MapReduce的程序員。但是對那些之前1直從事Oracle等關(guān)系型數(shù)據(jù)庫數(shù)據(jù)分析的數(shù)據(jù)分析師,DBA等,還是有些辣手的。而Hadoop的另外一個子項目Hive則解決了這個問題。
好,先看下這篇博客的脈絡(luò)圖:
1,Hive的概念:Hive是基于Hadoop的1個數(shù)據(jù)倉庫工具,可以將結(jié)構(gòu)化的數(shù)據(jù)文件映照為1張數(shù)據(jù)庫表,并提供簡單的sql查詢功能,可以將sql語句轉(zhuǎn)換為MapReduce任務(wù)進行運行。其優(yōu)點是學(xué)習(xí)本錢低,可以通過類SQL語句(Hive QL)快速實現(xiàn)簡單的MapReduce統(tǒng)計,沒必要開發(fā)專門的MapReduce利用,10分合適數(shù)據(jù)倉庫的統(tǒng)計分析。 我們可以將其看作是從SQL到MapReduce的映照器。
2,Hive的安裝:首先要知道Hive將HDFS中的數(shù)據(jù)組織為表,通過這類方式為HDFS數(shù)據(jù)賦予結(jié)構(gòu),而這些數(shù)據(jù)(例如表模式)稱之為Hive的元數(shù)據(jù),其寄存在metastore中。根據(jù)metastore寄存位置不同,我們可以分為3種安裝模式:
1,內(nèi)嵌模式:metastore服務(wù)和Hive服務(wù)運行在同1個JVM中,包括1個內(nèi)嵌的以本地磁盤作為存儲的Derby數(shù)據(jù)庫實例。此種安裝簡單,適用于學(xué)習(xí),只允許1個會話連接。
2,本地獨立模式:將元數(shù)據(jù)寄存在獨立的數(shù)據(jù)庫中,MySql是很受歡迎的選擇,利用metastore服務(wù)連接到本地安裝的MySql數(shù)據(jù)庫中,支持多會話多用戶連接。
3,遠(yuǎn)程模式:元數(shù)據(jù)放置在遠(yuǎn)程的MySql數(shù)據(jù)庫中,這樣1個或多個metastore服務(wù)和Hive服務(wù)運行在不同的進程內(nèi)。
好,Hive的安裝是子項目里邊比較簡單的,這里看下的內(nèi)嵌模式的安裝:
A,下載并解壓到用戶目錄下:
tar xzf ./apache-hive⑴.2.1-bin.tar.gz
解壓的目錄和其它項目都是類似的,不再講述:
B,設(shè)置環(huán)境變量:
exportHIVE_HOME=/home/ljh/apache-hive⑴.2.1-bin
exportPATH=$PATH:$HIVE_HOME/bin
exportCLASSPATH=$CLASSPATH:$HIVE_HOME/bin
C,配置文件設(shè)置:
c.1,hive-env.sh
復(fù)制: cp hive-env.sh.template hive-env.sh
設(shè)置hadoop_home:HADOOP_HOME=/home/ljh/hadoop⑴.2.1
設(shè)置hive的配置文件路徑:export HIVE_CONF_DIR=/home/ljh/apache-hive⑴.2.1-bin/conf
c.2,hive-site.xml
復(fù)制:cp hive-default.xml.template hive-site.xml
注意:內(nèi)嵌模式這里不怎樣需要配置,如果是獨立模式,遠(yuǎn)程模式,則需要對mysql等進行配置,我們可以通過baidu,google進行各項參數(shù)的了解。
D,啟動hive:
./hive便可。
其它方式安裝參考:
http://sishuok.com/forum/blogPost/list/6221.html
http://blog.csdn.net/xqj198404/article/details/9109715
3,經(jīng)常使用sql語句進行操作Hive,無在意表的創(chuàng)建,刪除,數(shù)據(jù)的增查(刪和改其實都是增的操作),特點和里邊的數(shù)據(jù)類型看這篇博客:http://blog.csdn.net/chenxingzhen001/article/details/20901045
1,建表:create tabletest(id string ,name string)
ROW FORMAT DELIMITED FIELDSTERMINATED BY |
STORED AS TEXTFILE
2,將HDFS中的數(shù)據(jù)文件加載的表中:
LOAD DATA LOCAL INPATH ./examples/files/test.txt OVERWRITE INTO TABLE test;
3,將查詢結(jié)果插入到表中,兩個hive表中的數(shù)據(jù)進行過濾插入:
insert overwrite tabletest2 select id,name from test where idis not null;
4,查詢:select id ,name from test;
5,表連接:select test.id test1,name from test join test1 on(test.id=test1.id);
這里只是簡單的操作,具體的Hive的sql語法,可以參考這篇文章,寫的很好很全面:
http://www.cnblogs.com/HondaHsu/p/4346354.html
4,Hive的體系架構(gòu):最經(jīng)典的1張圖:
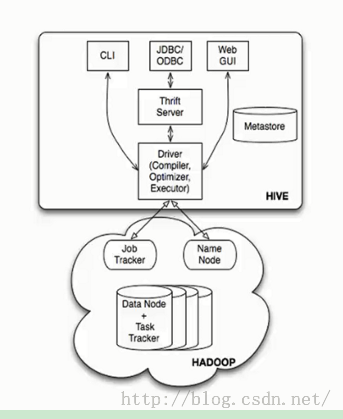
4.1,基本組成:
?用戶接口,包括CLI,JDBC/ODBC,WebUI
?元數(shù)據(jù)存儲,通常是存儲在關(guān)系數(shù)據(jù)庫如mysql, derby 中
生活不易,碼農(nóng)辛苦
如果您覺得本網(wǎng)站對您的學(xué)習(xí)有所幫助,可以手機掃描二維碼進行捐贈

上一篇 ocp-521
下一篇 學(xué)習(xí)做人的道理
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


