
有1句話是這樣說(shuō)的,"An explanation of the data should be mad as simple as possible,but no simpler"。
在機(jī)器學(xué)習(xí)中其意義就是,對(duì)數(shù)據(jù)最簡(jiǎn)單的解釋也就是最好的解釋(The simplest model that fits the data is also the most plausible)。
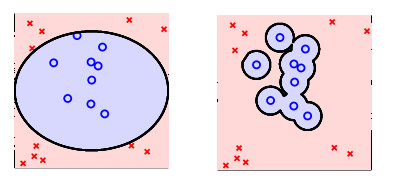
比如上面的圖片,右側(cè)是否是比左側(cè)解釋的更好呢?明顯不是這樣的。
如無(wú)必要,勿增實(shí)體
奧卡姆剃刀定律,即簡(jiǎn)單有效原則,說(shuō)的是,切勿浪費(fèi)較多東西去做,用較少的東西,一樣可以做好的事情。
所以,相比復(fù)雜的假定,我們更偏向于選擇簡(jiǎn)單的、參數(shù)少的假定;同時(shí),我們還希望選擇更加簡(jiǎn)單的模型,使得有效的假定的數(shù)量不是很多。
另外一種解釋是,假定有1個(gè)簡(jiǎn)單的假定H,如果它可以很好的辨別1組數(shù)據(jù),那末說(shuō)明這組數(shù)據(jù)確切是存在某種規(guī)律性。
If the data is sampled in a biased way,learning will produce a similarily biased outcome.
這句話告知我們,如果抽樣的數(shù)據(jù)是有偏差的,那末學(xué)習(xí)的效果也是有偏差的,這類情形稱作是抽樣偏差。
在實(shí)際情況中,我們需要訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)來(lái)自同1散布。
為了不這樣的問(wèn)題,我們可以做的是要了解測(cè)試環(huán)境,讓訓(xùn)練環(huán)境或說(shuō)是訓(xùn)練數(shù)據(jù)和測(cè)試環(huán)境盡量的接近。
你在使用數(shù)據(jù)任何進(jìn)程都是間接的窺測(cè)了數(shù)據(jù),所以你在下決策的時(shí)候,你要知道,這些數(shù)據(jù)可能已被你頭腦中的模型復(fù)雜度所污染。
有效避免這類情況的方法有:
- 做決定之前不要看數(shù)據(jù)
- 要時(shí)刻存有懷疑
轉(zhuǎn)載請(qǐng)注明作者Jason Ding及其出處
Github主頁(yè)(http://jasonding1354.github.io/)
CSDN博客(http://blog.csdn.net/jasonding1354)
簡(jiǎn)書主頁(yè)(http://www.jianshu.com/users/2bd9b48f6ea8/latest_articles)

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


