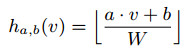針對高維數據的相似性索引非常適于構建內容相干的檢索系統,特別對音頻、圖象、視頻等內容豐富的數據。最近幾年來,位置敏感哈希及其變種算法以近似相似性搜索的索引技術被提出,這些方法的1個顯著缺點是需要很多的哈希表來保證良好的搜索效果。該文章提出了1個新的索引策略來克服上述缺點,稱作多探頭LSH。
多探頭LSH建立在LSH技術基礎上,它可以智能地探測哈希表中可能包括查詢結果的多個桶(buckets),該方法受基于熵的LSh方法(設計用于下降基本LSH方法對空間的要求)的啟發。根據評估顯示,多探頭LSH比起之條件出的方法在空間和時間效力上都有了顯著的提高。
對高維空間的相似性搜索在數據庫、數據發掘、搜索引擎,特別是對像音頻錄音、數字照片、數字影片和其他傳感器數據這些基于內容的搜索方面日趨重要。由于這些特點豐富的數據常被表示為高維特點向量,相似性搜索1般利用在K近鄰(K-Nearest Neighbor,KNN)和近似近鄰(Approximate Nearest Neighbors,ANN)搜索中。
1個針對相似性搜索的理想索引策略需滿足以下特性:
- 準確性,1個查詢操作應當得到接近于暴力線性搜索的理想返回結果。
- 時間效力,1個查詢操作的時間復雜度應當是O(1)或O(logN),其中N是數據集的數據數量。
- 空間效力,索引應當需要較少的內存空間,最好是和數據集數量差不多,不能比原始數據還要多。對大數據集,索引結構應在主存的可容范圍以內。
- 高維度,索引策略應在高維空間中工作良好。
用于KNN搜索的樹索引方法,如R樹、KD樹、SR樹、導航網(navigating nets)、覆蓋樹(cover tree),雖然能返回準確的結果,但是在高維空間中難有快速的時間效力。當維度大于10以后,這些索引結構比暴力線性掃描的方法還要慢。
針對高維相似性檢索算法,最著名的索引方法就是位置敏感哈希了。其基本方法是使用1組位置敏感哈希函數將在高維空間中相鄰的數據映照到相同的桶當中。
這里我將不再介紹基本的LSH原理,而只是大體的說明LSH的索引方法的框架結構,以保證與后面介紹的變種LSH方法的聯貫性。
關于這1部份的詳細內容可以參見:
LSH的基本思路是使用哈希函數依高幾率將相似的數據映照到同1哈希桶中。
根據LSH索引,履行1次相似查詢需要兩個步驟:
(1)使用LSH函數對給定的查詢數據q選取候選數據集。
(2)根據這些候選數據與q的距離進行排序,然后返回Top-K個數據。
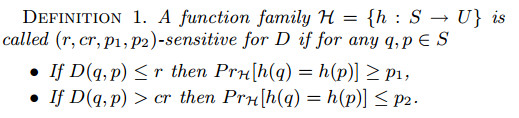
由于這樣的幾率特性保證,可使得兩個距離較遠的數據點碰撞的幾率是p2^M(其中M是LSH函數的個數),但同時也是的相鄰的數據碰撞的幾率是p1^M。
這樣的基本的LSH索引方法需要很多哈希表來保證涵蓋大部份近鄰數據,這對空間要求是很大的,1旦哈希表的空間要求超過了主存的容量,我們不能不將哈希表寄存在磁盤中,那末磁盤I/O的速度來查詢必定大大下降了查詢速度。
Entopy-based LSH構造索引和基本的LSH策略相似,但是使用了1種不同的查詢進程,該方法通過隨機生成若干個與查詢數據鄰近的擾動查詢數據(perturbing query objects),將這些數據和待查詢數據1同進行哈希,將所有的結果匯總得到候選集。
Entopy-based LSH提出的對哈希桶進行采樣的方法是,每次將與查詢數據q距離為Rp的隨機數據p'進行哈希,得到p'所對應的哈希桶;屢次進行這樣的采樣動作以較高幾率保證所有可能的桶都被探測(probe)到。
首先,該方法的采樣進程效力不足,擾動數據的生成和其哈希值計算速度慢,并且不可避免地得到重復的哈希桶。這樣,高幾率被映照的桶會屢次計算得到,這類計算是浪費的。
另外一個缺點是,采樣進程需要對近鄰距離Rp有1定了解,這對數據相互以來的情形是困難的。如果Rp太小,擾動查詢數據可能沒法產生足夠的候選集合;如果Rp過大,就需要更多的擾動查詢數據來保證更好的查詢質量。
Multi-Probe LSH方法的關鍵點是,使用1個經過仔細推導出的探測序列(carefully derived probing sequence),得到和查詢數據近似的多個哈希桶。
根據LSH的性質,我們可知如果與查詢數據q相近的數據沒有和q被映照到同1個桶中,它很有可能被映照到周圍的桶中(即兩個桶的哈希值只有些許差別),所以該方法的目標是定位這些鄰近的桶,以便增加查找近鄰數據的機會。
- 首先,我們定義1個哈希微擾向量(hash perturbation vector)Δ=(δ1,...,δM),給定1個查詢數據q,基本LSH方法得到的哈希桶是g(q)=(h1(q),...,hM(q)),我們定義微擾Δ,我們可以探測到哈希桶g(q)+Δ。
- 回想LSH函數
如果我們選擇公道的W,那末相似的數據應當映照到相同或鄰近的哈希值上(較大的W使得這個值相差最多1個單位),因此,我們關注微擾向量Δ在δi={⑴,0,1}。
- 微擾向量直接作用于查詢數據的哈希值上,避免了Entopy-based LSH方法中擾動數據計算和哈希值計算的天花板問題(overhead)。該方法設計的微擾向量序列(a sequence of pertubation vectors)中,每一個向量都映照成1個唯1的哈希值集合,這樣就不會重復探測1個哈希桶了。
下面的圖片演示了Multi-Probe LSH方法:
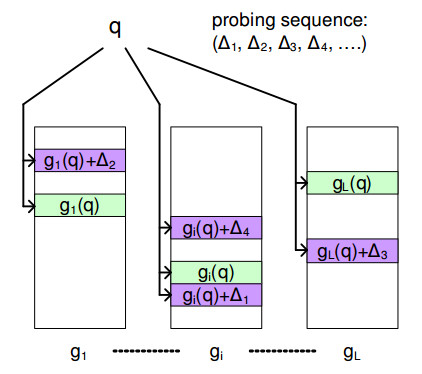
其中,gi(q)是第i個哈希表中查詢數據q的哈希值;(Δ1,Δ2,...)是探測序列(probing sequence);gi(q)+Δ1是使用Δ1附加到gi(q)的新的哈希值,它指向了該哈希表中其他的哈希桶。
通過使用多個微擾向量,我們可以定位多個哈希桶,以便取得查詢值q的更多的近鄰候選項。
轉載請注明作者Jason Ding及其出處
Github博客主頁(http://jasonding1354.github.io/)
CSDN博客(http://blog.csdn.net/jasonding1354)
簡書主頁(http://www.jianshu.com/users/2bd9b48f6ea8/latest_articles)
百度搜索jasonding1354進入我的博客主頁

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有