
內存分配從本質上來講是1種空間管理算法,給你1塊連續的空間,提供存儲服務,那末你的空間管理跟分配要采取甚么樣的算法才會比較高效?
Bump-the-Pointer是最簡單的算法。HotSpot的MM白皮書是這么描寫btp的,
That is, the end of the previously allocated object is always kept track of. When a new allocation request needs to be satisfied, all that needs to be done is to check whether the object will fit in the remaining part of the generation and, if so, to update the pointer and initialize the object.
我們只需要1個指針來記錄可用空間的起始地址,收到分配要求,先檢查可用空間是不是足夠分配給這次要求,如果足夠,則分配空間,并且更新指針;如果不夠就需要進行垃圾回收了。我們再來看看HotSpot的SerialCollector是怎樣使用btp的。
SerialCollector使用Mark-Sweep-Compact算法來對OldGen進行GC,對OldGen的分配,簡單的bump the pointer,如果這時候候剩余的可用空間已不夠,SerialCollector需要Stop-the-World,然后履行Mark-Sweep-Compact,即標記活著的對象,清除死去的對象,最后做sliding compaction,將活著的對象全部緊縮到1邊,這樣剩余的可用空間就能夠繼續簡單的使用btp算法來分配空間了。
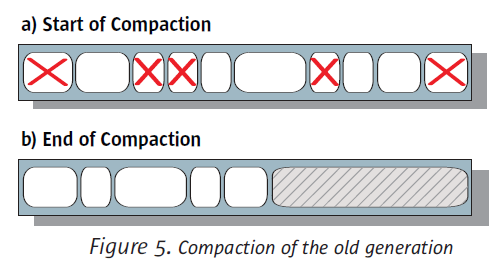
btp還有幾個點說下,
現在讓我們來看另外1種采取分治策略的管理方法。我們可以將連續空間劃分成1個個的組,每一個組內又包括若干個坑位,同組內每一個坑位的空間大小都是1樣的,至于坑位的大小是可以根據使用情況來進行調優的。
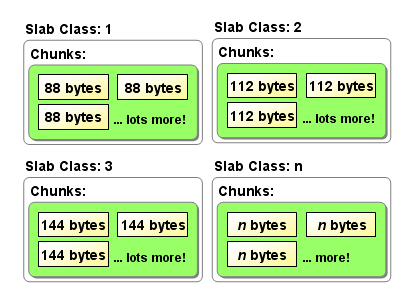
只需要再保護每一個組的metadata,這樣每次1有分配要求,先查看metadata就可以做到Best Fit。
Slab Allocator便是以上述方式工作的。與Bumb-the-Pointer相比,Slab不需要Stop-the-World來做GC,但是會造成1定的空間浪費,由于我們只能做到Best Fit。
Talk is cheap,下面來看看Memcached中的Slab實現。先看SlabClass的定義和初始化的方法,
typedef struct {
unsigned int size; /* sizes of items */
unsigned int perslab; /* how many items per slab */
void *slots; /* list of item ptrs */
unsigned int sl_curr; /* total free items in list */
unsigned int slabs; /* how many slabs were allocated for this class */
void **slab_list; /* array of slab pointers */
unsigned int list_size; /* size of prev array */
unsigned int killing; /* index+1 of dying slab, or zero if none */
size_t requested; /* The number of requested bytes */
} slabclass_t;void slabs_init(const size_t limit, const double factor, const bool prealloc) {
int i = POWER_SMALLEST - 1;
unsigned int size = sizeof(item) + settings.chunk_size;
mem_limit = limit;
if (prealloc) {
/* Allocate everything in a big chunk with malloc */
mem_base = malloc(mem_limit);
if (mem_base != NULL) {
mem_current = mem_base;
mem_avail = mem_limit;
} else {
fprintf(stderr, "Warning: Failed to allocate requested memory in"
" one large chunk.
Will allocate in smaller chunks
");
}
}
memset(slabclass, 0, sizeof(slabclass));
while (++i < POWER_LARGEST && size <= settings.item_size_max / factor) {
/* Make sure items are always n-byte aligned */
if (size % CHUNK_ALIGN_BYTES)
size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES);
slabclass[i].size = size;
slabclass[i].perslab = settings.item_size_max / slabclass[i].size;
size *= factor;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u
",
i, slabclass[i].size, slabclass[i].perslab);
}
}
power_largest = i;
slabclass[power_largest].size = settings.item_size_max;
slabclass[power_largest].perslab = 1;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u
",
i, slabclass[i].size, slabclass[i].perslab);
}
/* for the test suite: faking of how much we've already malloc'd */
{
char *t_initial_malloc = getenv("T_MEMD_INITIAL_MALLOC");
if (t_initial_malloc) {
mem_malloced = (size_t)atol(t_initial_malloc);
}
}
if (prealloc) {
slabs_preallocate(power_largest);
}
}slabs_init方法中可以看到我們上面所說的坑位大小的調優,Memcached是通過配置1個factor來實現,坑位的大小是按factor倍增長的。
需要注意這里的size是sizeof(item) + settings.chunk_size,item是Memcached所存儲的數據,在memcache.h中定義。存儲系統的數據結構設計又是另外一個可以深究的話題,后面再探討。
typedef struct _stritem {
struct _stritem *next;
struct _stritem *prev;
struct _stritem *h_next; /* hash chain next */
rel_time_t time; /* least recent access */
rel_time_t exptime; /* expire time */
int nbytes; /* size of data */
unsigned short refcount;
uint8_t nsuffix; /* length of flags-and-length string */
uint8_t it_flags; /* ITEM_* above */
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey; /* key length, w/terminating null and padding */
/* this odd type prevents type-punning issues when we do
* the little shuffle to save space when not using CAS. */
union {
uint64_t cas;
char end;
} data[];
/* if it_flags & ITEM_CAS we have 8 bytes CAS */
/* then null-terminated key */
/* then " flags length
" (no terminating null) */
/* then data with terminating
(no terminating null; it's binary!) */
} item;每個SlabClass里面有1組Slab,每一個Slab又拆分為slabclass.perslab個大小為slabclass.size的坑位。
static int grow_slab_list (const unsigned int id) {
slabclass_t *p = &slabclass[id];
if (p->slabs == p->list_size) {
size_t new_size = (p->list_size != 0) ? p->list_size * 2 : 16;
void *new_list = realloc(p->slab_list, new_size * sizeof(void *));
if (new_list == 0) return 0;
p->list_size = new_size;
p->slab_list = new_list;
}
return 1;
}
static void split_slab_page_into_freelist(char *ptr, const unsigned int id) {
slabclass_t *p = &slabclass[id];
int x;
for (x = 0; x < p->perslab; x++) {
do_slabs_free(ptr, 0, id);
ptr += p->size;
}
}
static int do_slabs_newslab(const unsigned int id) {
slabclass_t *p = &slabclass[id];
int len = settings.slab_reassign ? settings.item_size_max
: p->size * p->perslab;
char *ptr;
if ((mem_limit && mem_malloced + len > mem_limit && p->slabs > 0) ||
(grow_slab_list(id) == 0) ||
((ptr = memory_allocate((size_t)len)) == 0)) {
MEMCACHED_SLABS_SLABCLASS_ALLOCATE_FAILED(id);
return 0;
}
memset(ptr, 0, (size_t)len);
split_slab_page_into_freelist(ptr, id);
p->slab_list[p->slabs++] = ptr;
mem_malloced += len;
MEMCACHED_SLABS_SLABCLASS_ALLOCATE(id);
return 1;
}使用FreeList,也就是slabclass.slots來管理這些可用的坑位,
static void do_slabs_free(void *ptr, const size_t size, unsigned int id) {
slabclass_t *p;
item *it;
assert(((item *)ptr)->slabs_clsid == 0);
assert(id >= POWER_SMALLEST && id <= power_largest);
if (id < POWER_SMALLEST || id > power_largest)
return;
MEMCACHED_SLABS_FREE(size, id, ptr);
p = &slabclass[id];
it = (item *)ptr;
it->it_flags |= ITEM_SLABBED;
it->prev = 0;
it->next = p->slots;
if (it->next) it->next->prev = it;
p->slots = it;
p->sl_curr++;
p->requested -= size;
return;
}使用簡單的互斥鎖來應對并發情況。(為何不是鎖SlabClass而是需要直接鎖住全部Slab Allocator?)
void *slabs_alloc(size_t size, unsigned int id) {
void *ret;
pthread_mutex_lock(&slabs_lock);
ret = do_slabs_alloc(size, id);
pthread_mutex_unlock(&slabs_lock);
return ret;
}最后,上面說的都是邏輯結構,下面貼1下我整理的物理結構便于理解,其中slabclass[0].perslab=3。
mem_base slabclass[0].slots
| |
+---+---+---+---+---+---+---+---+---+---+
| X | X | X | X | | | | X | | |
+---+---+---+---+---+---+---+---+---+---+
| | |
slabclass[0] slabclass[1] slabclass[0]
.slab_list[0] .slab_list[0] .slab_list[1]Buddy Allocator采取的策略與Slab類似,在我理解它只是1種特殊的Slab Allocator,坑位的大小是2的次冪,這樣就致使了Buddy的空間浪費要比Slab嚴重很多,例如1個33K的分配要求會被分配到64K的空間。說到底其實還是要根據實際使用情況來調劑坑位大小,減少空間的浪費。

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


