
最近用其svmlight進行movie review文本分類的問題。查閱了1些svmlight軟件的使用方法,在此整理以下:
1)下載svm_light軟件,分別為svm_classify.exe和svm_learn.exe
2)下載它的訓練數(shù)據(jù)的example,以下面的圖所示:
train.dat
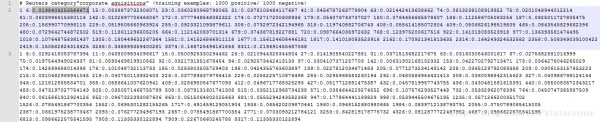
model
test.dat與train.dat格式相似
3)下面了解1些訓練數(shù)據(jù)的格式
文件格式
文件格式要先交代1下. 你可以參考 libsvm 里面附的 “heart_scale”: 這是SVM 的輸入文件格式.
[label] [index1]:[value1] [index2]:[value2] …
[label] [index1]:[value1] [index2]:[value2] …
1行1條記錄數(shù)據(jù),如:
+1 1:0.708 2:1 3:1 4:-0.320 5:-0.105 6:⑴
label
或說是class, 就是你要分類的種類,通常是1些整數(shù)。
index
是有順序的索引,通常是連續(xù)的整數(shù)。
value
就是用來 train 的數(shù)據(jù),通常是1堆實數(shù)。
每行都是如上的結(jié)構(gòu), 意思就是: 我有1排數(shù)據(jù), 分別是 value1, value2, …. value, (而且它們的順序已由 index 分別指定),這排數(shù)據(jù)的分類結(jié)果就是label。
也許你會不太懂,為何會是 value1,value2,…. 這樣1排呢? 這牽涉到 SVM 的原理。你可以這樣想(我沒說這是正確的), 它的名字就叫 Support “Vector” Machine,所以輸入的訓練數(shù)據(jù)是 “Vector”(向量), 也就是1排的 x1, x2, x3, … 這些值就是 value,而 x[n] 的n就是由index 指定。這些東西又稱為 “(屬性)attribute”。
真實的情況是,大部分時候我們給定的數(shù)據(jù)可能有很多 “特點(feature)” 或說 “屬性(attribute)”,所以輸入會是1組的。舉例來講,之前面點分區(qū)的例子 來講,我們不是每一個點都有 X 跟 Y 的坐標嗎?所以它就有兩種屬性。假定我有兩個點: (0,3) 跟 (5,8) 分別在 label(class) 1 跟 2 ,那就會寫成
1 1:0 2:3
2 1:5 2:8
同理,空間中的3維坐標就等于有3組屬性。這類文件格式最大的好處就是可使用稀疏矩陣(sparse matrix),或說有些數(shù)據(jù)的屬性可以有缺失。
4)Dos進入訓練、測試數(shù)據(jù)所在的文件夾,進行測試
>svm_learn -c 0.5 -g 3.2 train.dat model
>svm_classify test.txt model predict_result.txt
其中有1些參數(shù),我以后用到時會再發(fā)博客講授。

上一篇 通用網(wǎng)址升級為“.網(wǎng)址”域名意味著什么?
下一篇 基于dropwizard/metrics ,kafka,zabbix構(gòu)建應用統(tǒng)計數(shù)據(jù)收集展示系統(tǒng)
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學習,原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


