
英文原文:What and where are the stack and heap?
問題描述
編程語言書籍中經常解釋值類型被創建在棧上,引用類型被創建在堆上,但是并沒有本質上解釋這堆和棧是什么。我僅有高級語言編程經驗,沒有看過對此更清晰的解釋。我的意思是我理解什么是棧,但是它們到底是什么,在哪兒呢(站在實際的計算機物理內存的角度上看)?
棧是為執行線程留出的內存空間。當函數被調用的時候,棧頂為局部變量和一些 bookkeeping 數據預留塊。當函數執行完畢,塊就沒有用了,可能在下次的函數調用的時候再被使用。棧通常用后進先出(LIFO)的方式預留空間;因此最近的保留塊(reserved block)通常最先被釋放。這么做可以使跟蹤堆棧變的簡單;從棧中釋放塊(free block)只不過是指針的偏移而已。
堆(heap)是為動態分配預留的內存空間。和棧不一樣,從堆上分配和重新分配塊沒有固定模式;你可以在任何時候分配和釋放它。這樣使得跟蹤哪部分堆已經被分配和被釋放變的異常復雜;有許多定制的堆分配策略用來為不同的使用模式下調整堆的性能。
每一個線程都有一個棧,但是每一個應用程序通常都只有一個堆(盡管為不同類型分配內存使用多個堆的情況也是有的)。
直接回答你的問題: 1. 當線程創建的時候,操作系統(OS)為每一個系統級(system-level)的線程分配棧。通常情況下,操作系統通過調用語言的運行時(runtime)去為應用程序分配堆。 2. 棧附屬于線程,因此當線程結束時棧被回收。堆通常通過運行時在應用程序啟動時被分配,當應用程序(進程)退出時被回收。 3. 當線程被創建的時候,設置棧的大小。在應用程序啟動的時候,設置堆的大小,但是可以在需要的時候擴展(分配器向操作系統申請更多的內存)。 4. 棧比堆要快,因為它存取模式使它可以輕松的分配和重新分配內存(指針/整型只是進行簡單的遞增或者遞減運算),然而堆在分配和釋放的時候有更多的復雜的 bookkeeping 參與。另外,在棧上的每個字節頻繁的被復用也就意味著它可能映射到處理器緩存中,所以很快(譯者注:局部性原理)。
Stack:
Heap:
舉例:
int foo() { char *pBuffer; //<--nothing allocated yet (excluding the pointer itself, which is allocated here on the stack). bool b = true; // Allocated on the stack. if(b) { //Create 500 bytes on the stack char buffer[500]; //Create 500 bytes on the heap pBuffer = new char[500]; }//<-- buffer is deallocated here, pBuffer is not }//<--- oops there's a memory leak, I should have called delete[] pBuffer;
堆和棧是兩種內存分配的兩個統稱。可能有很多種不同的實現方式,但是實現要符合幾個基本的概念:
1.對棧而言,棧中的新加數據項放在其他數據的頂部,移除時你也只能移除最頂部的數據(不能越位獲取)。

2.對堆而言,數據項位置沒有固定的順序。你可以以任何順序插入和刪除,因為他們沒有“頂部”數據這一概念。

上面上個圖片很好的描述了堆和棧分配內存的方式。
在通常情況下由操作系統(OS)和語言的運行時(runtime)控制嗎?
如前所述,堆和棧是一個統稱,可以有很多的實現方式。計算機程序通常有一個棧叫做調用棧,用來存儲當前函數調用相關的信息(比如:主調函數的地址,局部變量),因為函數調用之后需要返回給主調函數。棧通過擴展和收縮來承載信息。實際上,程序不是由運行時來控制的,它由編程語言、操作系統甚至是系統架構來決定。
堆是在任何內存中動態和隨機分配的(內存的)統稱;也就是無序的。內存通常由操作系統分配,通過應用程序調用 API 接口去實現分配。在管理動態分配內存上會有一些額外的開銷,不過這由操作系統來處理。
它們的作用范圍是什么?
調用棧是一個低層次的概念,就程序而言,它和“作用范圍”沒什么關系。如果你反匯編一些代碼,你就會看到指針引用堆棧部分。就高級語言而言,語言有它自己的范圍規則。一旦函數返回,函數中的局部變量會直接直接釋放。你的編程語言就是依據這個工作的。
在堆中,也很難去定義。作用范圍是由操作系統限定的,但是你的編程語言可能增加它自己的一些規則,去限定堆在應用程序中的范圍。體系架構和操作系統是使用虛擬地址的,然后由處理器翻譯到實際的物理地址中,還有頁面錯誤等等。它們記錄那個頁面屬于那個應用程序。不過你不用關心這些,因為你僅僅在你的編程語言中分配和釋放內存,和一些錯誤檢查(出現分配失敗和釋放失敗的原因)。
它們的大小由什么決定?
依舊,依賴于語言,編譯器,操作系統和架構。棧通常提前分配好了,因為棧必須是連續的內存塊。語言的編譯器或者操作系統決定它的大小。不要在棧上存儲大塊數據,這樣可以保證有足夠的空間不會溢出,除非出現了無限遞歸的情況(額,棧溢出了)或者其它不常見了編程決議。
堆是任何可以動態分配的內存的統稱。這要看你怎么看待它了,它的大小是變動的。在現代處理器中和操作系統的工作方式是高度抽象的,因此你在正常情況下不需要擔心它實際的大小,除非你必須要使用你還沒有分配的內存或者已經釋放了的內存。
哪個更快一些?
棧更快因為所有的空閑內存都是連續的,因此不需要對空閑內存塊通過列表來維護。只是一個簡單的指向當前棧頂的指針。編譯器通常用一個專門的、快速的寄存器來實現。更重要的一點事是,隨后的棧上操作通常集中在一個內存塊的附近,這樣的話有利于處理器的高速訪問(譯者注:局部性原理)。
你問題的答案是依賴于實現的,根據不同的編譯器和處理器架構而不同。下面簡單的解釋一下:
堆:
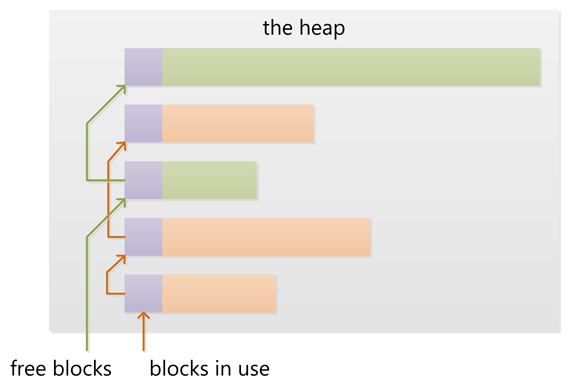
棧:
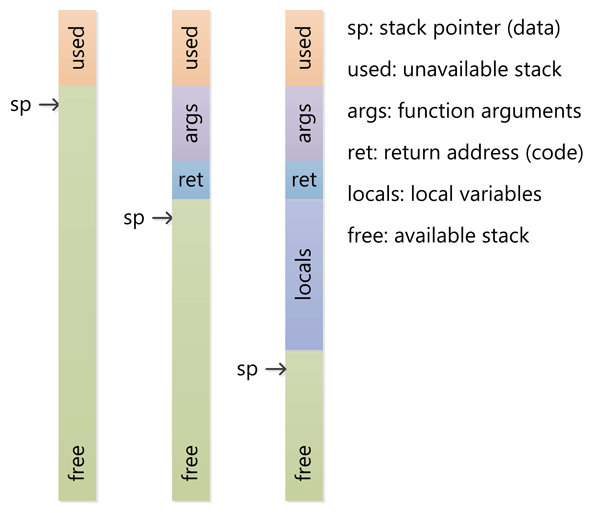
*函數的分配可以用堆來代替棧嗎?
不可以的,函數的活動記錄(即局部或者自動變量)被分配在棧上, 這樣做不但存儲了這些變量,而且可以用來嵌套函數的追蹤。
堆的管理依賴于運行時環境,C 使用 malloc ,C++ 使用 new ,但是很多語言有垃圾回收機制。
棧是更低層次的特性與處理器架構緊密的結合到一起。當堆不夠時可以擴展空間,這不難做到,因為可以有庫函數可以調用。但是,擴展棧通常來說是不可能的,因為在棧溢出的時候,執行線程就被操作系統關閉了,這已經太晚了。
關于堆棧的這個帖子,對我來說,收獲非常多。我之前看過一些資料,自己寫代碼的時候也常常思考。就這方面,也和祥子(我的大學舍友,現在北京郵電讀研,技術牛人)探討過多次了。但是終究是一個一個的知識點,這個帖子看完之后,豁然開朗,把知識點終于連接成了一個網。這種感覺,經歷過的一定懂得,期間的興奮不言而喻。
這個帖子跟帖者不少,我選了評分最高的四個。這四個之間也有一些是重復的觀點。個人鐘愛第四個回答者,我看的時候,瞬間高潮了,有木有?不過需要一些匯編語言、操作系統、計算機組成原理的的基礎,知道那幾個寄存器是干什么的,要知道計算機的流水線指令工作機制,保護/恢復現場等概念。三個回復者都涉及到了操作系統中虛擬內存;在比較速度的時候,大家一定要在腦中對“局部性原理”和計算機高速緩存有一個概念。
如果你把這篇文章看懂了,我相信你收獲的不只是堆和棧,你會理解的更多!
興奮之余,有幾點還是要強調的,翻譯沒有逐字逐詞翻譯,大部分是通過我個人的知識積累和對回帖者的意圖揣測而來的。請大家不要咬文嚼字,逐個推敲,我們的目的在于技術交流,不是么?達到這一目的就夠了。
下面是一些不確定點:
以上,送給大家,本文結束。

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


