
本文以TensorFlow源碼中自帶的手寫數字辨認Example為例,引出TensorFlow中的幾個主要概念。并結合Example源碼1步步分析該模型的實現進程。
在這里,引入TensorFlow中文社區首頁中的兩段描寫。
關于 TensorFlow
TensorFlow? 是1個采取數據流圖(data flow
graphs),用于數值計算的開源軟件庫。節點(Nodes)在圖中表示數學操作,圖中的線(edges)則表示在節點間相互聯系的多維數據數組,即張量(tensor)。它靈活的架構讓你可以在多種平臺上展開計算,例如臺式計算機中的1個或多個CPU(或GPU),服務器,移動裝備等等。TensorFlow
最初由Google大腦小組(隸屬于Google機器智能研究機構)的研究員和工程師們開發出來,用于機器學習和深度神經網絡方面的研究,但這個系統的通用性使其也可廣泛用于其他計算領域。甚么是數據流圖(Data Flow Graph)?
數據流圖用“結點”(nodes)和“線”(edges)的有向圖來描寫數學計算。“節點”
1般用來表示施加的數學操作,但也能夠表示數據輸入(feed in)的出發點/輸出(push
out)的終點,或是讀取/寫入持久變量(persistent
variable)的終點。“線”表示“節點”之間的輸入/輸出關系。這些數據“線”可以輸運“size可動態調劑”的多維數據數組,即“張量”(tensor)。張量從圖中流過的直觀圖象是這個工具取名為“Tensorflow”的緣由。1旦輸入真個所有張量準備好,節點將被分配到各種計算裝備完成異步并行地履行運算。
接下來的示例中,主要使用到以下兩個文件。
mnist.py
fully_connected_feed.py 該示例的目的是建立1個手寫圖象辨認模型,通過該模型,可以準確辨認輸入的28 * 28像素的手寫圖片是0~9這10個數字中的哪個。
需要下載好tensorflow源代碼,注意這里的源代碼版本需要與安裝的TensorFlow版本保持1致。
在/home/mlusr/files/tensorflow/下解緊縮該文件。進入示例文件路徑中,運行
cd ~/files/tensorflow/tensorflow-r0.11/tensorflow/examples/tutorials/mnist
python fully_connected_feed.py 運行進程中,需要聯網下載訓練數據,數據文件保存到~/files/tensorflow/tensorflow-r0.11/tensorflow/examples/tutorials/mnist/data路徑下,如果不能聯網的話,可以手動到http://yann.lecun.com/exdb/mnist/,下載好以下4個文件,放入data目錄。
t10k-images-idx3-ubyte.gz
t10k-labels-idx1-ubyte.gz
train-images-idx3-ubyte.gz
train-labels-idx1-ubyte.gz 直接運行fully_connected_feed.py文件。
python fully_connected_feed.py輸出信息以下:
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
Step 0: loss = 2.30 (0.007 sec)
Step 100: loss = 2.13 (0.005 sec)
Step 200: loss = 1.87 (0.004 sec)
Step 300: loss = 1.55 (0.004 sec)
Step 400: loss = 1.26 (0.004 sec)
Step 500: loss = 0.87 (0.004 sec)
Step 600: loss = 0.87 (0.004 sec)
Step 700: loss = 0.65 (0.005 sec)
Step 800: loss = 0.43 (0.004 sec)
Step 900: loss = 0.65 (0.005 sec)
Training Data Eval:
Num examples: 55000 Num correct: 47184 Precision @ 1: 0.8579
Validation Data Eval:
Num examples: 5000 Num correct: 4349 Precision @ 1: 0.8698
Test Data Eval:
Num examples: 10000 Num correct: 8663 Precision @ 1: 0.8663
Step 1000: loss = 0.47 (0.006 sec)
Step 1100: loss = 0.40 (0.051 sec)
Step 1200: loss = 0.55 (0.005 sec)
Step 1300: loss = 0.43 (0.004 sec)
Step 1400: loss = 0.39 (0.004 sec)
Step 1500: loss = 0.57 (0.005 sec)
Step 1600: loss = 0.50 (0.004 sec)
Step 1700: loss = 0.37 (0.005 sec)
Step 1800: loss = 0.38 (0.006 sec)
Step 1900: loss = 0.35 (0.004 sec)
Training Data Eval:
Num examples: 55000 Num correct: 49292 Precision @ 1: 0.8962
Validation Data Eval:
Num examples: 5000 Num correct: 4525 Precision @ 1: 0.9050
Test Data Eval:
Num examples: 10000 Num correct: 9027 Precision @ 1: 0.9027在啟動TensorBoard時注意指定輸出log文件路徑,在本例中啟動命令以下
tensorboard --logdir /home/mlusr/files/tensorflow/tensorflow-r0.11/tensorflow/examples/tutorials/mnist/data啟動輸出信息以下所示:
Starting TensorBoard 29 on port 6006
(You can navigate to http://192.168.1.100:6006) 閱讀器訪問頁面指定ip和端口:
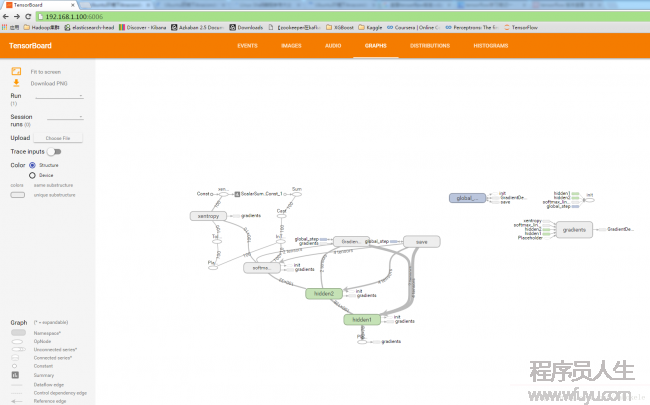
在TensorBoard中還可以查看該模型的更多信息。
本文接下來的部份,將以mnist.py和fully_connected_feed.py兩個文件中的內容
MNIST的數據主要分成以下3個部份,
| 數據集 | 作用 |
|---|---|
| data_sets.train | 55000條image和label數據,主要用于訓練模型 |
| data_sets.validation | 5000條image和label數據,用于在迭代進程中肯定模型準確率 |
| data_sets.test | 10000條image和label數據,用于終究評估模型的準確率 |
Placeholder的更多描寫,請看這里。使用Placeholder的地方,在構造Graph時其實不包括實際的數據,只是在利用運行時才會動態的用數據來替換。
在fully_connected_feed.py文件中的placeholder_inputs方法中,通過調用tf.placeholder方法分別生成了代表images和labels的placeholder。
IMAGE_SIZE = 28
IMAGE_PIXELS = IMAGE_SIZE * IMAGE_SIZE
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size, mnist.IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size)) 在生成placeholder時,只需要指定其中的數據類型,和維度。上面images_placeholder中的元素為float類型,維度為batch_size * IMAGE_PIXELS。lagels_placeholder中的元素為int類型,維度為batch_size。batch_size參數在程序調用placeholder_inputs時指定。
看到這里可以發現images_placeholder和labels_placeholder僅僅只是指定了其中元素的類型和shape,具體數值是在后續程序運行時才會填充進來的。所以叫做Placeholder。在這里這兩個Placeholder代表了輸入的兩個數據源。
Graph是TensorFlow中又1個重要概念。Graph可以理解成TensorFlow中的1個調劑好參數的履行計劃。構建好這個Graph以后,所有輸入數據,中間轉換進程,和輸出數據的流程和格式便固定下來,數據進入Graph后依照特定的結構和參數,就可以得到對應的輸出結果。以下圖所示:
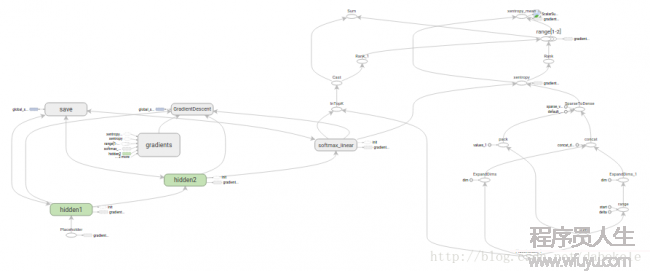
構建1個Graph主要分成以下3步。
inference方法,以images_placeholder作為輸入,連接到維度為(28 * 28, 128)的隱層1,隱層1連接到維度為(128, 32)的隱層2,最后的輸出層logits為10個節點。各層之間的激活函數為Relu。
下面代碼中使用到的常量
IMAGE_SIZE = 28
IMAGE_PIXELS = IMAGE_SIZE * IMAGE_SIZE
flags.DEFINE_integer('hidden1', 128, 'Number of units in hidden layer 1.')
flags.DEFINE_integer('hidden2', 32, 'Number of units in hidden layer 2.')
NUM_CLASSES = 10構建隱層1,
with tf.name_scope('hidden1'):
weights = tf.Variable(tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),
name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),
name='biases') 上面定義了兩個Variable,weights表示連接權重,biases表示偏置量。
biases比較簡單,定義了1個名為biases的元素全為0的變量,其長度為hiden1_units,默許為128。
weights的維度為IMAGE_PIXELS * hidden1_units,其中的初始值為標準差為1 / math.sqrt(float(IMAGE_PIXELS)的截斷正態散布值。
構建隱層2,
with tf.name_scope('hidden2'):
weights = tf.Variable(tf.truncated_normal([hidden1_units, hidden2_units],
stddev =1.0 / math.sqrt(float(hidden1_units))),
name = 'weights')
biases = tf.Variable(tf.zeros([hidden2_units]),
name ='biases')構建輸出層,
with tf.name_scope('softmax_linear'):
weights = tf.Variable(tf.truncated_normal([hidden2_units, NUM_CLASSES] ,
stddev =1.0 / math.sqrt(float(hidden2_units))) ,
name = 'weights')
biases = tf.Variable(tf.zeros([NUM_CLASSES]),
name ='biases') 基于上面的權重和偏置量值,使用relu激活函數連接各層,
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
logits = tf.matmul(hidden2, weights) + biases 前面的3組weights和biases變量名都相同,辨別的辦法是前面的with tf.name_scope('hidden1')。在hidden1命名空間下的wiehts參數的完全表示為"hidden1/weights"。
上1步肯定好模型各層結構和參數后,接下來需要定義1個損失函數的計算邏輯。
在mnist.py文件中有1個loss()方法,輸入兩個參數,第1個為上面模型的輸出結果logits,第2個為images對應的實際labels,在調用該方法時,傳入的是前面定義的labels_placeholder。
def loss(logits, labels):
labels = tf.to_int64(labels)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, labels , name = 'xentropy')
loss = tf.reduce_mean(cross_entropy, name ='xentropy_mean')
return loss 上面的tf.nn.sparse_softmax_cross_entropy_with_logits會根據labels的內容自動生成1-hot編碼,并且計算與輸出logits的1-hot編碼的交叉熵[cross entropy][http://blog.csdn.net/rtygbwwwerr/article/details/50778098])
最后,調用reduce_mean方法,計算交叉熵的平均值。
調用training方法的調用情勢為,傳入上面的損失值和學習率。
train_op = mnist.training(loss, FLAGS.learning_rate) 接下來,mnist.py文件中的training方法,將使用梯度降落法來計算使得損失值最小的模型參數。首先將損失值loss傳入tf.scala_summary中,這個操作主要是用于在后面使用SummaryWriter時向events file中生成求和值,將每次得到的損失值寫出到事件文tf.scalar_summary(loss.op.name, loss)后,調用tf.train.GradientDesecentOptimizer按指定的學習率實現梯度降落算法。
# Create the gradient descent optimizer with the given learning rate.
optimizer = tf.train.GradientDescentOptimizer(learning_rate) 最后,使用1個名為global_step的variable來記錄每次訓練的步長。optimizer.minimize操作用于更新系統的權重,同時增加步長。
# Create a variable to track the global step.
global_step = tf.Variable(0, name = 'global_step', trainable =False)
# Use the optimizer to apply the gradients that minimize the loss
# (and also increment the global step counter) as a single training step.
train_op = optimizer.minimize(loss, global_step=global_step)當第3步中的Graph構造完成以后,就能夠迭代的訓練和評估模型了。
在run_training()方法的最前面,使用1個with命令表明所有的操作都要與tf.Graph的默許全局graph相干聯。
with tf.Graph().as_default(): tf.Graph表示需要在1起運行的操作集合。在大多數情況下,TensorFlow使用1個默許的graph就已夠用了。
接下來就需要為利用運行準備環境了。在TensorFlow中使用的是Session。
sess = tf.Session() 另外,除按上面這行代碼生成sess對象外,還可使用with命令生成,以下所示,
with tf.Session() as sess: 在取得sess對象后,首先可以將之前定義的variable進行初始化,
init = tf.initialize_all_variables()
sess.run(init) 初始化以后就能夠開始循環訓練模型了。
可以通過以下代碼實現1個最簡單的訓練循環,在這個循環中可以控制每次循環的步長。
for step in xrange(FLAGS.max_steps):
sess.run(train_op) 但是在本教程中的例子比較復雜。這是由于必須把輸入的數據根據每步的情況進行切分,替換到之前的placeholder處。具體可以繼續看以下部份。
TensorFlow的feed機制可以在利用運行時向Graph輸入數據。在每步訓練進程中,首先會根據訓練數據生成1個feed dictionary,這里面會包括本次循環中使用到的訓練數據集。
feed_dict = fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder) fill_feed_dict方法以下,每次從訓練數據集中根據batch_size取出指定數量的images_feed和labels_feed,然后以images_pl和labels_pl為key存入字典中。
def fill_feed_dict (data_set, images_pl, labels_pl):
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size,
FLAGS.fake_data)
feed_dict = {
images_pl: images_feed,
labels_pl: labels_feed,
}
return feed_dict接下來以上面獲得到的每一個batch的數據開始履行訓練進程。
for step in xrange(FLAGS.max_steps):
feed_dict = fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder)
_, loss_value = sess.run([train_op, loss],
feed_dict=feed_dict) 在這里傳入train_op和loss后,sess.run方法返回1個包括兩個Tensor的tuple對象。由于train_op并沒有返回值,所以只記錄loss的返回值loss_value。
假定訓練進程很正常,那末每過100次訓練將會打印1次當前的loss值,
if step % 100 == 0 :
print ('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration)) 在上面每隔100次打印1次loss值以外,還有兩個操作將當前的loss值寫入到事件文件中,供TensorBoard作展現用。
summary_str = sess.run(summary, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, step)
summary_writer.flush() 在TensorFlow中使用tf.train.Saver將訓練好的模型進行保存。
saver = tf.train.Saver() 在循環訓練進程中,saver.save()方法會定期履行,用于將模型當前狀態寫入到檢查點文件中。
checkpoint_file = os.path.join(FLAGS.log_dir , 'model.ckpt')
saver.save(sess, checkpoint_file, global_step =step) 如果需要使用到該檢查點文件中保存的模型時,可使用saver.restore()方法進行加載,
saver.restore(sess, FLAGS.train_dir)在每次保存檢查點文件時,會同時計算此時模型在訓練數據集,檢驗數據集和測試數據集上的誤差。
print('Training Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.train)
# Evaluate against the validation set.
print ('Validation Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation)
# Evaluate against the test set.
print ('Test Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.test) 注意上面代碼中的do_eval方法,和該方法的eval_correct參數。eval_correct操作是在循環開始前就已定義好了的。
eval_correct = mnist.evaluation(logits, labels_placeholder) 這個evaluation從參數上看是用于比較預測值與真實值直接的差異。
def evaluation (logits, labels):
correct = tf.nn.in_top_k(logits, labels, 1)
return tf.reduce_sum(tf.cast(correct, tf.int32)) 返回1個長度為batch_size的tensor,如果預測值與真實值相同則為true,否則為false。
最后,在do_eval方法中,處理該誤差并輸出。類似于模型訓練進程中,這里也創建1個feed_dict對象,在給定的數據集上調用sess.run方法,計算預測值中有多少與實際值相1致。
for step in xrange(steps_per_epoch):
feed_dict = fill_feed_dict(data_set,
images_placeholder,
labels_placeholder)
true_count += sess.run(eval_correct, feed_dict =feed_dict)最后,將預測正確的記錄數與當前的總數據數進行比較,得到本次的預測精度。
precision = float(true_count) / num_examples
print ('Num examples: %d Num correct: %d Precision @ 1: %0.04f' %
(num_examples, true_count, precision))
上一篇 《JAVA與模式》之裝飾模式
下一篇 Java線程池總結
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


