
該配置為VMware10+CentOS7mini+jdk+hadoop⑵.7(ps:hadoop
2.7需要64位的jdk和CentOS版本了),由于小編主要用來學hadoop就用CentOS7mini(600M+)版本了(如果需要深入了解的童鞋可以下載4G大小的那個DVD版本的CentOS7),另外強勢推薦兩個非常好用的插件(Xshell和Xftp,可自行百度下,用于遠程登錄和從真機傳輸下面的緊縮包)。
下載地址:
CentOS:
https://www.centos.org/download/
JDK:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads⑵133151.html
Hadoop:
http://hadoop.apache.org/releases.html
下載完成后如圖:

(ps:兩個緊縮包后綴均為.gz,大小均為200M左右,hadoop的緊縮包別下錯了,小編第1次下了個30M的,致使重擼了1遍-.-!!!)
創建虛擬機(如圖1)--->典型(如圖2)--->稍后安裝系統(如圖3)--->選擇Linux(L),版本CentOS64位(如圖4)--->虛擬機名稱:cMaster,只是用來標識該虛擬機,位置自選(如圖5)--->大小20G,將虛擬機拆分多個文件(如圖6)--->自定義硬件中(內存為1G足夠,處理器1,CD/DVD選擇你的系統鏡像位置如圖7,網絡適配器網絡連接選擇NAT模式
圖1
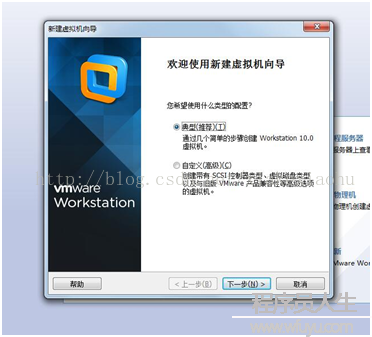
圖2
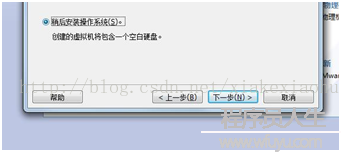
圖3
圖4
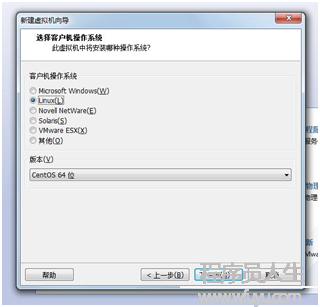
圖5
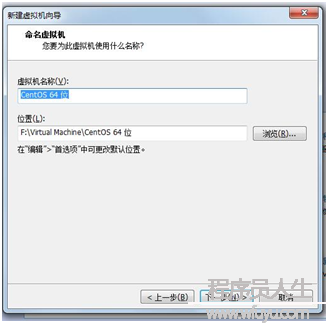
圖6
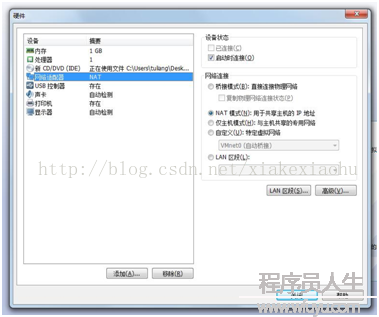
圖7
完成以上配置后點擊完成便可(另外兩臺slave機器完全不需要如此安裝,等完成master后克隆便可,3臺虛擬機只需要10來分鐘弄定)。
啟動虛擬機落后入頁面(如圖8),選擇Install CentOS Linux 7(如圖9)回車肯定。以后進入語言選擇中文,簡體中文(如圖10)。
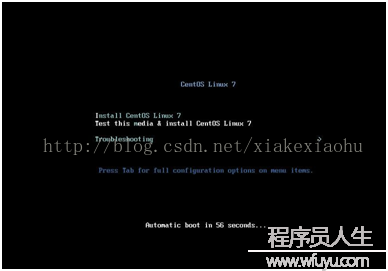
圖8
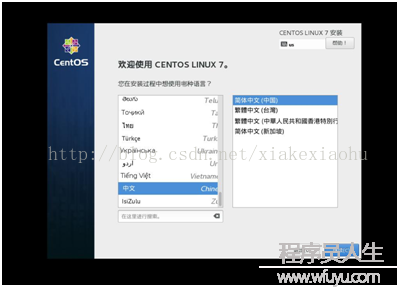
圖9
進入詳細信息安裝界面(如圖10),肯定下安裝位置便可,選擇自動分區,點擊完成(如圖11),單機開始安裝。將ROOT密碼設為:123456,創建用戶均為:hadoop,密碼為:123456(如圖12)。
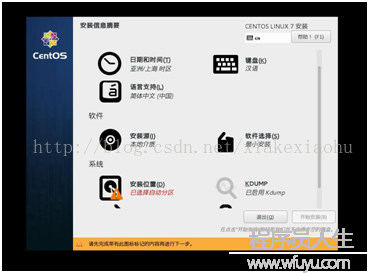
圖10
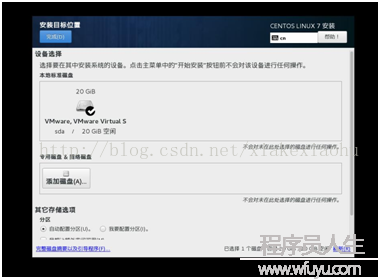
圖11
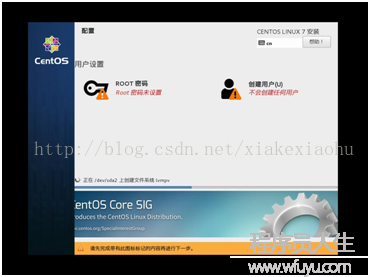
圖12
最后安裝完成點擊重啟便可。
啟動以后直接以:root登錄(如圖1),默許情況下CentOS是不提供網絡打開的,輸入命令:#cd /etc/sysconfig/network-scripts
以后鍵入:#ll 可以看到有ifcfg-ens33 該文件(隨機產生,因人而異),鍵入:#vi ifcfg-ens33 進入編輯狀態(如圖2),修改其中的onboot=no,改成onboot=yes(如圖3),最后wq 保存,鍵入#systemctl restart network(如圖4),即可以看到已有網絡了,可以#pingwww.baidu.com測試下。
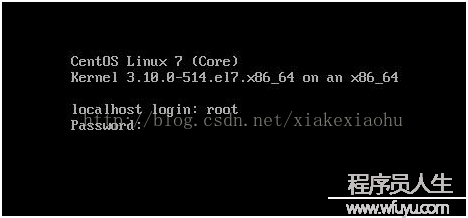
圖1
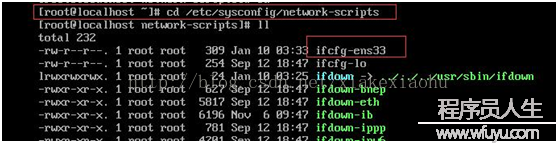
圖2
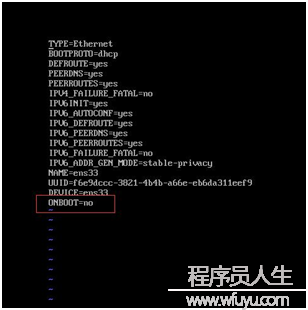
圖3
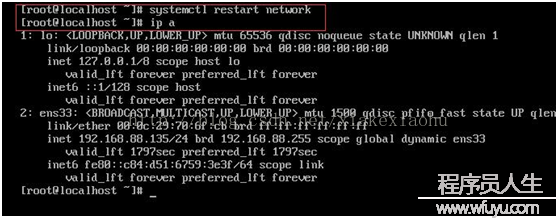
圖4
這個時候就要用到前面提的xshell,比直接在linux下好用,可以復制粘貼啥的,Xshell連接該該虛擬機的界面(如圖5,6)。
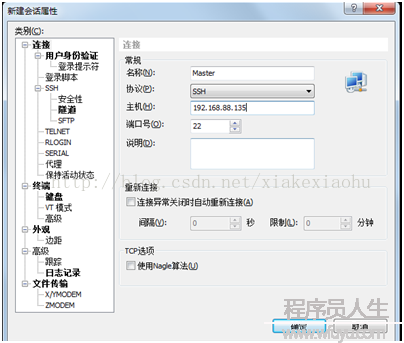
圖5
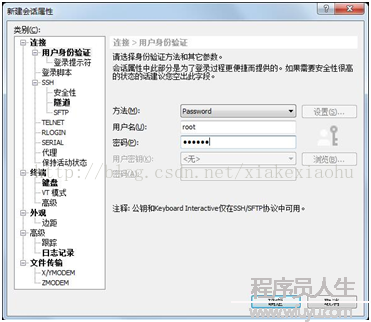
圖6
在Xshell里操作,比在虛擬機里好用多了。
當3臺虛擬機均安裝完成后,需要進行的是修改機器名、添加域名映照、關閉防火墻,并安裝jdk。
3.2.1修改機器名。
首先需要安裝下vim編輯器,鍵入:#yum –yinstall vim*,
修改主機名
$ vim/etc/sysconfig/network
在其中添加“HOSTNAME=cMaster”,然后重啟當前虛擬機,再查看機器名就是cMaster了。
(如果重啟以后機器名不是cMaster,可使用命令hostnamectlset-hostnamecMaster修改機器名)
(2) 添加域名映照
使用ifconfig命令分別查看3臺虛擬機的IP地址。然后將3個ip地址都添加到各自的/etc/hosts文件中圖2,偽分步3臺主機的ip配置以下圖1。
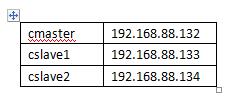
圖1
(ps:ip配置不1定要跟小編1樣,只要合適自己就行。。)
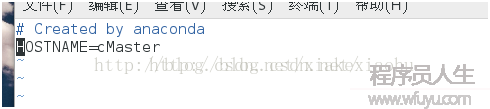
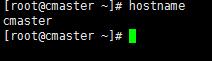
圖2
3臺機器均修改完成后,使用# ping cmaster/cslave1/cslave2/命令測試各機器之間是不是能夠正常通3臺機信。如果出現下圖所示信息說明通訊正常。

(3) 關閉當前機器的防火墻。
在root權限下履行以下兩條指令,關閉防火墻并禁止其開機啟動。
# systemctl stop firewalld.service#停止firewall
# systemctl disable firewalld.service#制止firewall開機啟動
(4) 安裝JDK。
將切換到:# cd /home/hadoop目錄下,
使用命令# tar zxvf jdk⑻u111-linux-x64.tar.gz解壓安裝、修改配置文件:# vim /etc/profile,在文章最末尾添加以下配置:
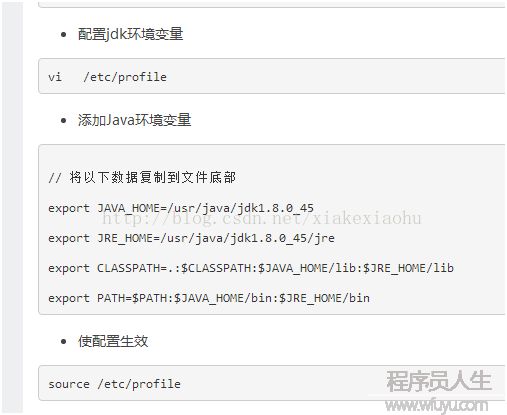
安裝完成后使用java -version以下圖則表明安裝成功。
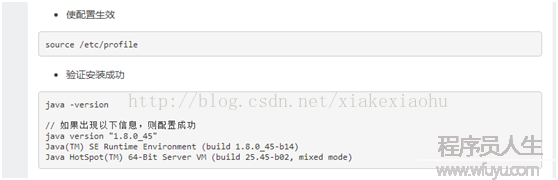
(1)依照以上步驟配置完成后,最好重啟1下所有機器,確保所有的設置生效。
然后利用root賬戶分別登錄3臺機器。將事前下載好的hadoop緊縮包用xftp傳輸到每臺機器的/home/hadoop/目錄下,然后在每臺機器上分別使用
#tar -zxvf /home/joe/ hadoop⑵.7.3.tar 命令解壓安裝hadoop2.7.3
將hadoop寫入配置中(hadoop安裝路徑,因人而異,將export HADOOP_INSTALL=/你的hadoop安裝路徑),以下圖。
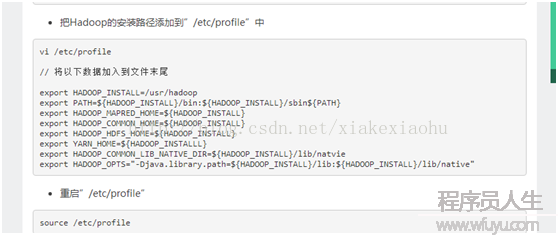
(2)解壓完成后需要修改hadoop的配置文件。
(本小節步驟在3臺機器上都完全相同,3臺機器都需要進行修改)
A.使用以下指令編輯hadoop-env.sh文件
# vim/home/hadoop/hadoop-**/etc/hadoop/hadoop-env.sh
在文件中找到exportJAVA_HOME=${JAVA_HOME}
修改成exportJAVA_HOME=/usr/Java/jdk1.8.0_101(填寫自己安裝的jdk的路徑)
B.修改core-site.xml文件
使用命令# vim/home/hadoop/hadoop-** /etc/hadoop/core-site.xml
在<configuration>標簽之間插入以下內容,(需要在hadoop目錄下創建1個cloudData的文件目錄)。
<property><name>hadoop.tmp.dir</name><value>/home/hadoop/cloudData</value></property>
<property><name>fs.defaultFS</name><value>hdfs://cMaster:8020</value></property>
C.修改yarn-site.xml文件
使用以下命令修改#vim/home/hadoop/hadoop-**/etc/hadoop/yarn-site.xml
在<configuration>標簽之間插入以下內容
<property><name>yarn.resourcemanager.hostname</name><value>cMaster</value></property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
D.修改mapred-site.xml.template
將/home/ hadoop/hadoop-** /etc/hadoop/目錄下的mapred-site.xml.template重命名為mapred-site.xml
并用命令
# vim/home/ hadoop/hadoop-**/etc/hadoop/mapred-site.xml
在<configuration>標簽之間加入以下內容:
<property><name>mapreduce.framework.name</name><value>yarn</value></property>
3.3.1免密碼SSH設置
(1)以下在cMaster主機上設置
生成秘鑰對,履行以下命令
#ssh-keygen -t rsa
然后1直按【Enter】鍵,就會依照默許的選項將生成的秘鑰對保存在.ssh/id_rsa文件中。
進入.ssh目錄履行以下命令
#cp id_rsa.pub authorized_keys//將id_rsa.pub授權到key里面去
(2)設置SSH配置
#vi /etc/ssh/sshd_config
將RSAAuthentication yes//前面的#去掉
PubkeyAutentication yes//前面的#去掉
AuthorizedKeysFile .ssh/authorized_keys//看看是不是變成autorized_keys
(3)重啟SHH服務
#service ssh start//mini版本好像不需要該步驟,直接可以進入ssh無密碼登錄
(4)設置cslave兩臺ssh配置
把公鑰復制所有cslave機器上
//scp ~/.ssh/id_rsa.pub 遠程用戶名@遠程服務器ip:~/
#scp ~/.ssh/id_rsa.pub root@192.168.88.133:~/
#scp~/.ssh/id_rsa.pub root@192.168.88.134:~/
(5)設置cslave主機
將公鑰復制給authorized_keys
//cp 文件1 文件2
#cp id_rsa.pub ~/.ssh/authorized_keys
設置SSH配置
#vi /etc/ssh/sshd_config
將RSAAuthentication yes//前面的#去掉
PubkeyAutentication yes//前面的#去掉
AuthorizedKeysFile .ssh/authorized_keys//看看是不是變成autorized_keys
(6)測試是不是可行
#ssh localhost

3.4啟動hadoop
首先格式化主節點命名空間,使用命令:
#/home/hadoop/hadoop-**/bin/hdfsnamenode –formate
方法1:其次在主節點上啟動存儲服務和資源管理主服務。使用命令:
/home/ hadoop/hadoop-**/sbin/hadoop-daemon.sh start namenode #啟動主存儲服務
#/home/ hadoop/hadoop-**/sbin/yarn-daemon.sh start resourcemanager# 啟動資源管理服務。
最后在從節點上啟動存儲從服務和資源管理從服務(以下兩條命令要在兩臺機器上分別履行)
#/home/ hadoop/hadoop-**/sbin/hadoop-daemon.sh start datanode #啟動從存儲服務
/home/ hadoop/hadoop-**/sbin/yarn-daemon.sh start nodemanager #啟動資源管理從服務
方法2:或進入sbin目錄
#cd /home/hadoop/hadoop-**/sbin/start-all.sh//啟動hadoop守護進程
#cd /home/hadoop/hadoop-**/sbin/stop-all.sh//停止hadoop守護進程
服務啟動后在3臺機器上分別使用jps命令查看是不是啟動。
cSlave1和cSlave2以下圖所示

cMaster節點顯示以下圖所示

在cMaster機器的閱讀器地址欄里輸入cMaster:50070可以看到HDFS的相干信息,cMaster:8088可以看到Yarn的相干信息。
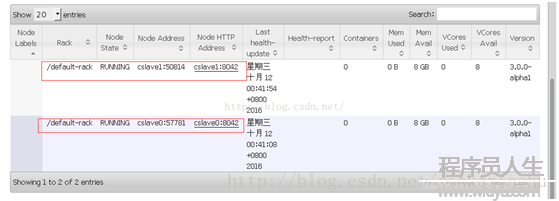
如圖還可以查看從節點的信息。
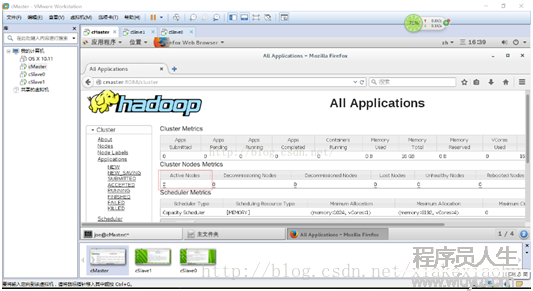
至此 Hadoop3.0的配置工作已完成了。接下來可使用示例程序Wordcount來利用散布式系統統計某個文件中單詞出現的次數。
在cMaster上以hadoop用戶登錄,然后履行以下的操作命令:
cd/home/ hadoop/hadoop-**/
bin/hdfs dfs -mkdir /in
bin/hdfs dfs -put/home/ hadoop/hadoop-**/etc/hadoop/* /in
bin/hadoopjarshare/hadoop/mapreduce/hadoop-mapreduce-examples⑶.0.0-alpha1.jar wordcount /in /out/wc
以下圖,在閱讀器中輸入cMaster:50070 可以看到hdfs,切換到相應文件夾下可以看到統計出的結果。


程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


