
【問】hadoop在生產環境下綜合斟酌的的數據塊副本數多少
1. hadoop 生態概況
Hadoop是1個由Apache基金會所開發的散布式系統基礎架構。
用戶可以在不了解散布式底層細節的情況下,開發散布式程序。充分利用集群的威力進行高速運算和存儲。
具有可靠、高效、可伸縮的特點。
Hadoop的核心是YARN,HDFS和Mapreduce
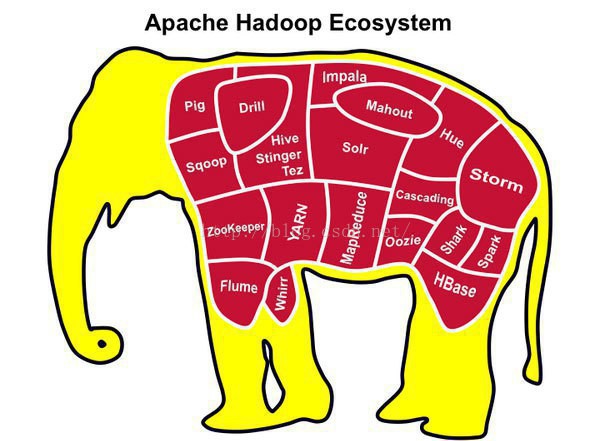
下圖是hadoop生態系統,集成spark生態圈。在未來1段時間內,hadoop將于spark共存,hadoop與spark
都能部署在yarn、mesos的資源管理系統之上

下面將分別對以上各組件進行扼要介紹,具體介紹參見后續系列博文。
源自于Google的GFS論文,發表于2003年10月,HDFS是GFS克隆版。
HDFS是Hadoop體系中數據存儲管理的基礎。它是1個高度容錯的系統,能檢測和應對硬件故障,用于在低本錢的通用硬件上運行。
HDFS簡化了文件的1致性模型,通過流式數據訪問,提供高吞吐量利用程序數據訪問功能,合適帶有大型數據集的利用程序。
它提供了1次寫入屢次讀取的機制,數據以塊的情勢,同時散布在集群不同物理機器上。
源自于google的MapReduce論文,發表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是1種散布式計算模型,用以進行大數據量的計算。它屏蔽了散布式計算框架細節,將計算抽象成map和reduce兩部份,
其中Map對數據集上的獨立元素進行指定的操作,生成鍵-值對情勢中間結果。Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到終究結果。
MapReduce非常合適在大量計算機組成的散布式并行環境里進行數據處理。
4. HBASE(散布式列存數據庫)
源自Google的Bigtable論文,發表于2006年11月,HBase是Google Bigtable克隆版
HBase是1個建立在HDFS之上,面向列的針對結構化數據的可伸縮、高可靠、高性能、散布式和面向列的動態模式數據庫。
HBase采取了BigTable的數據模型:增強的稀疏排序映照表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。
HBase提供了對大范圍數據的隨機、實時讀寫訪問,同時,HBase中保存的數據可使用MapReduce來處理,它將數據存儲和并行計算完善地結合在1起。
5. Zookeeper(散布式協作服務)
源自Google的Chubby論文,發表于2006年11月,Zookeeper是Chubby克隆版
解決散布式環境下的數據管理問題:統1命名,狀態同步,集群管理,配置同步等。
Hadoop的許多組件依賴于Zookeeper,它運行在計算機集群上面,用于管理Hadoop操作。
6. HIVE(數據倉庫)
由facebook開源,最初用于解決海量結構化的日志數據統計問題。
Hive定義了1種類似SQL的查詢語言(HQL),將SQL轉化為MapReduce任務在Hadoop上履行。通經常使用于離線分析。
HQL用于運行存儲在Hadoop上的查詢語句,Hive讓不熟習MapReduce開發人員也能編寫數據查詢語句,然后這些語句被翻譯為Hadoop上面的MapReduce任務。
7.Pig(ad-hoc腳本)
由yahoo!開源,設計動機是提供1種基于MapReduce的ad-hoc(計算在query時產生)數據分析工具
Pig定義了1種數據流語言—Pig Latin,它是MapReduce編程的復雜性的抽象,Pig平臺包括運行環境和用于分析Hadoop數據集的腳本語言(Pig Latin)。
其編譯器將Pig Latin翻譯成MapReduce程序序列將腳本轉換為MapReduce任務在Hadoop上履行。通經常使用于進行離線分析。
8.Sqoop(數據ETL/同步工具)
Sqoop是SQL-to-Hadoop的縮寫,主要用于傳統數據庫和Hadoop之前傳輸數據。數據的導入和導出本質上是Mapreduce程序,充分利用了MR的并行化和容錯性。
Sqoop利用數據庫技術描寫數據架構,用于在關系數據庫、數據倉庫和Hadoop之間轉移數據。
9.Flume(日志搜集工具)
Cloudera開源的日志搜集系統,具有散布式、高可靠、高容錯、易于定制和擴大的特點。
它將數據從產生、傳輸、處理并終究寫入目標的路徑的進程抽象為數據流,在具體的數據流中,數據源支持在Flume中定制數據發送方,從而支持搜集各種不同協議數據。
同時,Flume數據流提供對日志數據進行簡單處理的能力,如過濾、格式轉換等。另外,Flume還具有能夠將日志寫往各種數據目標(可定制)的能力。
總的來講,Flume是1個可擴大、合適復雜環境的海量日志搜集系統。固然也能夠用于搜集其他類型數據
Mahout起源于2008年,最初是Apache Lucent的子項目,它在極短的時間內獲得了長足的發展,現在是Apache的頂級項目。
Mahout的主要目標是創建1些可擴大的機器學習領域經典算法的實現,旨在幫助開發人員更加方便快捷地創建智能利用程序。
Mahout現在已包括了聚類、分類、推薦引擎(協同過濾)和頻繁集發掘等廣泛使用的數據發掘方法。
除算法,Mahout還包括數據的輸入/輸出工具、與其他存儲系統(如數據庫、MongoDB 或Cassandra)集成等數據發掘支持架構。
11. Oozie(工作流調度器)
Oozie是1個可擴大的工作體系,集成于Hadoop的堆棧,用于調和多個MapReduce作業的履行。它能夠管理1個復雜的系統,基于外部事件來履行,外部事件包括數據的定時和數據的出現。
Oozie工作流是放置在控制依賴DAG(有向無環圖 Direct Acyclic Graph)中的1組動作(例如,Hadoop的Map/Reduce作業、Pig作業等),其中指定了動作履行的順序。
Oozie使用hPDL(1種XML流程定義語言)來描寫這個圖。
12. Yarn(散布式資源管理器)
- 資源管理:包括利用程序管理和機器資源管理
- 資源雙層調度
- 容錯性:各個組件均有斟酌容錯性
- 擴大性:可擴大到上萬個節點
13. Mesos(散布式資源管理器)
Mesos誕生于UC Berkeley的1個研究項目,現已成為Apache項目,當前有1些公司使用Mesos管理集群資源,比如Twitter。
與yarn類似,Mesos是1個資源統1管理和調度的平臺,一樣支持比如MR、steaming等多種運算框架。
14. Tachyon(散布式內存文件系統)
Tachyon(/'t?ki:??n/ 意為超光速粒子)是之內存為中心的散布式文件系統,具有高性能和容錯能力,
能夠為集群框架(如Spark、MapReduce)提供可靠的內存級速度的文件同享服務。
Tachyon誕生于UC Berkeley的AMPLab。
15. Tez(DAG計算模型)
Tez是Apache最新開源的支持DAG作業的計算框架,它直接源于MapReduce框架,核心思想是將Map和Reduce兩個操作進1步拆分,
即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,
這樣,這些分解后的元操作可以任意靈活組合,產生新的操作,這些操作經過1些控制程序組裝后,可構成1個大的DAG作業。
目前hive支持mr、tez計算模型,tez能完善2進制mr程序,提升運算性能。
16. Spark(內存DAG計算模型)
Spark是1個Apache項目,它被標榜為“快如閃電的集群計算”。它具有1個繁華的開源社區,并且是目前最活躍的Apache項目。
最早Spark是UC Berkeley AMP lab所開源的類Hadoop MapReduce的通用的并行計算框架。
Spark提供了1個更快、更通用的數據處理平臺。和Hadoop相比,Spark可讓你的程序在內存中運行時速度提升100倍,或在磁盤上運行時速度提升10倍
17. Giraph(圖計算模型)
Apache Giraph是1個可伸縮的散布式迭代圖處理系統, 基于Hadoop平臺,靈感來自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
最早出自雅虎。雅虎在開發Giraph時采取了Google工程師2010年發表的論文《Pregel:大范圍圖表處理系統》中的原理。后來,雅虎將Giraph捐贈給Apache軟件基金會。
目前所有人都可以下載Giraph,它已成為Apache軟件基金會的開源項目,并得到Facebook的支持,取得多方面的改進。
18. GraphX(圖計算模型)
Spark GraphX最早是伯克利AMPLAB的1個散布式圖計算框架項目,目前整合在spark運行框架中,為其提供BSP大范圍并行圖計算能力。
19. MLib(機器學習庫)
Spark MLlib是1個機器學習庫,它提供了各種各樣的算法,這些算法用來在集群上針對分類、回歸、聚類、協同過濾等。
20. Streaming(流計算模型)
Spark Streaming支持對流數據的實時處理,以微批的方式對實時數據進行計算
21. Kafka(散布式消息隊列)
Kafka是Linkedin于2010年12月份開源的消息系統,它主要用于處理活躍的流式數據。
活躍的流式數據在web網站利用中非常常見,這些數據包括網站的pv、用戶訪問了甚么內容,搜索了甚么內容等。
這些數據通常以日志的情勢記錄下來,然后每隔1段時間進行1次統計處理。
22. Phoenix(hbase sql接口)
Apache Phoenix 是HBase的SQL驅動,Phoenix 使得Hbase 支持通過JDBC的方式進行訪問,并將你的SQL查詢轉換成Hbase的掃描和相應的動作。
23. ranger(安全管理工具)
Apache ranger是1個hadoop集群權限框架,提供操作、監控、管理復雜的數據權限,它提供1個集中的管理機制,管理基于yarn的hadoop生態圈的所有數據權限。
24. knox(hadoop安全網關)
Apache knox是1個訪問hadoop集群的restapi網關,它為所有rest訪問提供了1個簡單的訪問接口點,能完成3A認證(Authentication,Authorization,Auditing)和SSO(單點登錄)等
25. falcon(數據生命周期管理工具)
Apache Falcon 是1個面向Hadoop的、新的數據處理和管理平臺,設計用于數據移動、數據管道調和、生命周期管理和數據發現。它使終端用戶可以快速地將他們的數據及其相干的處理和管理任務“上載(onboard)”到Hadoop集群。
26.Ambari(安裝部署配置管理工具)
Apache Ambari 的作用來講,就是創建、管理、監視 Hadoop 的集群,是為了讓 Hadoop 和相干的大數據軟件更容易使用的1個web工具。
參考文獻:
Hadoop生態系統介紹 http://blog.csdn.net/qa962839575/article/details/44256769?ref=myread
大數據和Hadoop生態圈,Hadoop發行版和基于Hadoop的企業級利用 http://www.36dsj.com/archives/26942
Oozie介紹 http://blog.csdn.net/wf1982/article/details/7200663
統1資源管理與調度平臺(系統)介紹 http://blog.csdn.net/meeasyhappy/article/details/8669688
Tachyon簡介http://blog.csdn.net/u014252240/article/details/41810849
Apache Tez:1個運行在YARN之上支持DAG作業的計算框架 http://segmentfault.com/a/1190000000458726
Giraph:基于Hadoop的開源圖形處理平臺 http://tech.it168.com/a2013/0821/1523/000001523700.shtml
Hadoop家族學習線路圖 http://blog.fens.me/hadoop-family-roadmap/
基于Spark的圖計算框架 GraphX 入門介紹 http://www.open-open.com/lib/view/open1420689305781.html
Apache Spark 入門簡介 http://blog.jobbole.com/89446/
Ambari——大數據平臺的搭建利器 http://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/index.html
消息系統Kafka介紹 http://dongxicheng.org/search-engine/kafka/
使用Apache Phoenix 實現 SQL 操作HBase http://www.tuicool.com/articles/vu6jae
面向Hadoop的、新的數據處理和管理平臺:Apache Falcon http://www.open-open.com/lib/view/open1422533435767.html

上一篇 談談MySQL的存儲引擎
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


