
“我們正在從IT時期走向DT時期(數據時期)。IT和DT之間,不單單是技術的變革,更是思想意識的變革,IT主要是為自我服務,用來更好地自我控制和管理,DT則是激活生產力,讓他人活得比你好”——阿里巴巴董事局主席馬云。
數據量從M的級別到G的級別到現在T的級、P的級別。數據量的變化數據管理系統(DBMS)和數倉系統(DW)也在悄然的變化著。
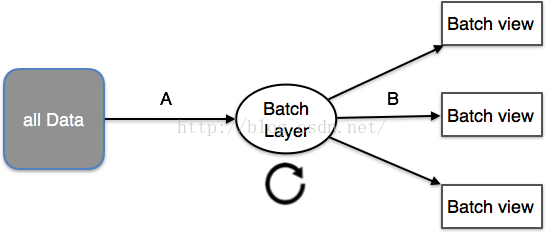
傳統利用的數據系統架構設計時,利用直接訪問數據庫系統。當用戶訪問量增加時,數據庫沒法支持日趨增長的用戶要求的負載時,從而致使數據庫服務器沒法及時響利用戶要求,出現超時的毛病。出現這類情況以后,在系統架構上就采取圖(A)的架構,在數據庫和利用中間過1層緩沖隔離,減緩數據庫的讀寫壓力。但是,當用戶訪問量延續增加時,就需要斟酌讀寫分離技術(Master-Slave)架構如圖(B),分庫分表技術。現在,架構變得愈來愈復雜了,增加隊列、分區、復制等處理邏輯。利用程序需要了解數據庫的schema,才能訪問到正確的數據。

圖(A)

圖(B)
大數據處理技術需要解決這類可伸縮性與復雜性。首先要認識到這類散布式的本質,要很好地處理分區與復制,不會致使毛病分區引發查詢失敗,而是要將這些邏輯內化到數據庫中。當需要擴大系統時,可以非常方便地增加節點,系統也能夠針對新節點進行rebalance。其次是要讓數據成為不可變的。原始數據永久都不能被修改,這樣即便犯了毛病,寫了毛病數據,原來好的數據其實不會遭到破壞。
Storm的作者NathanMarz提出的1個實時大數據處理框架(Lambda架構)就滿足以上兩點。Marz在Twitter工作期間開發了著名的實時大數據處理框架Storm,Lambda架構是其根據多年進行散布式大數據系統的經驗總結提煉而成。
Lambda架構的目標是設計出1個能滿足實時大數據系統關鍵特性的架構,包括有:高容錯、低延時和可擴大等。Lambda架構整合離線計算和實時計算,融會不可變性(Immunability),讀寫分離和復雜性隔離等1系列架構原則,可集成Hadoop,Kafka,Storm,Spark,Hbase等各類大數據組件。
Marz介紹BigData System許具有的屬性:
a、Robustandfault-tolerant(容錯性和魯棒性):對大范圍散布式系統來講,機器是不可靠的,可能會當機,但是系統需要是硬朗、行動正確的,即便是遇到機器毛病。除機器毛病,人更可能會出錯誤。在軟件開發中難免會有1些Bug,系統必須對有Bug的程序寫入的毛病數據有足夠的適應能力,所以比機器容錯性更加重要的容錯性是人為操作容錯性。對大范圍的散布式系統來講,人和機器的毛病每天都可能會產生,如何應對人和機器的毛病,讓系統能夠從毛病中快速恢復特別重要。
b、Lowlatency reads and updates(低延時):很多利用對讀和寫操作的延時要求非常高,要求對更新和查詢的響應是低延時的。
c、Scalable(橫向擴容):當數據量/負載增大時,可擴大性的系統通過增加更多的機器資源來保持性能。也就是常說的系統需要線性可擴大,通常采取scale out(通過增加機器的個數)而不是scale up(通過增強機器的性能)。
d、General(通用性):系統需要能夠適應廣泛的利用,包括金融領域、社交網絡、電子商務數據分析等。
e、Extensible(可擴大):需要增加新功能、新特性時,可擴大的系統能以最小的開發代價來增加新功能。
f、Allows ad hoc queries(方便查詢):數據中包含有價值,需要能夠方便、快速的查詢出所需要的數據。
d、Minimal maintenance(易于保護):系統要想做到易于保護,其關鍵是控制其復雜性,越是復雜的系統越容易出錯、越難保護。
h、Debuggable(易調試):當出問題時,系統需要有足夠的信息來調試毛病,找到問題的本源。其關鍵是能夠追根溯源到每一個數據生成點。
Marz認為:數據系統通過查詢過去的(部份、全部)數據去回答問題。如:他是1個甚么樣的人?他有多少朋友?這個賬號是不是收支平衡?。因此,DataSystem的通用定義為Query=Function(alldata)。對通用的表達式進行分解得到:數據系統=數據+查詢,從而可以從數據和查詢兩個方面認識大數據系統的本質。
數據是1個不可分割的單元,數據有兩個關鍵的特性:When和What。
When是只數據是與時間相干的,也就是數據是在某個時間產生的。這個非常重要,在具有事務特性的數據庫中,操作的前后順序對結果相當重要。例如數據庫的Binlog日志。因此,數據的時間性質決定了數據的全局產生前后,也就決定了數據的結果。
What是只數據的本身。由于數據跟某個時間點相干,所以數據的本身是不可變的(immutable),過往的數據已成為事實(Fact),你不可能回到過去的某個時間點去改變數據事實。這也就意味著對數據的操作其實只有兩種:讀取已存在的數據和添加更多的新數據。采取數據庫的記法,CRUD就變成了CR,Update和Delete本質上實際上是新產生的數據信息,用C來記錄。
根據上述對數據特性的分析,lambda架構中對數據的存儲采取的方式是:數據不可變,存儲所有數據。
采取這兩種方式存儲的好處:
a、簡單。采取不可變的數據模型,存儲數據時只需要簡單的往主數據集后追加數據便可。相比于采取可變的數據模型,為了Update操作,數據通常需要被索引,從而能快速找到要更新的數據去做更新操作。
b、應對人為和機器的毛病。人和機器每天都可能會出錯,如何應對人和機器的毛病,讓數據系統快速恢復極為重要。不可變和可重復計算是應對認為和機器毛病的經常使用方法。采取可變數據模型,引發毛病的數據有可能被覆蓋而丟失。相比于采取不可變的數據模型,由于所有的數據都在,引發毛病的數據也在。修復的方法就能夠簡單的是遍歷數據集上存儲的所有的數據,拋棄毛病的數據,重新計算得到Views。重新計算的關鍵點在于利用數據的時間特性決定的全局次序,順次順序重新履行,必定能得到正確的結果。
當前業界有很多采取不可變數據模型來存儲所有數據的例子。比如散布式數據庫Datomic,基于不可變數據模型來存儲數據,從而簡化了設計。散布式消息中間件Kafka,基于Log日志,以追加append-only的方式來存儲消息。
Lambda架構的主要思想是將大數據系統架構為多層個層次,分別為批處理層(batchlayer)、實時處理層(speedlayer)、服務層(servinglayer)如圖(C)。
理想狀態下,任何數據訪問都可以從表達式Query= function(alldata)開始,但是,若數據到達相當大的1個級別(例如PB),且還需要支持實時查詢時,就需要耗費非常龐大的資源。1個解決方式是預運算查詢函數(precomputedquery funciton)。書中將這類預運算查詢函數稱之為Batch View(A),這樣當需要履行查詢時,可以從BatchView中讀取結果。這樣1個預先運算好的View是可以建立索引的,因此可以支持隨機讀取(B)。因而系統就變成:
(A)batchview = function(all data);
(B)query =function(batch view)。
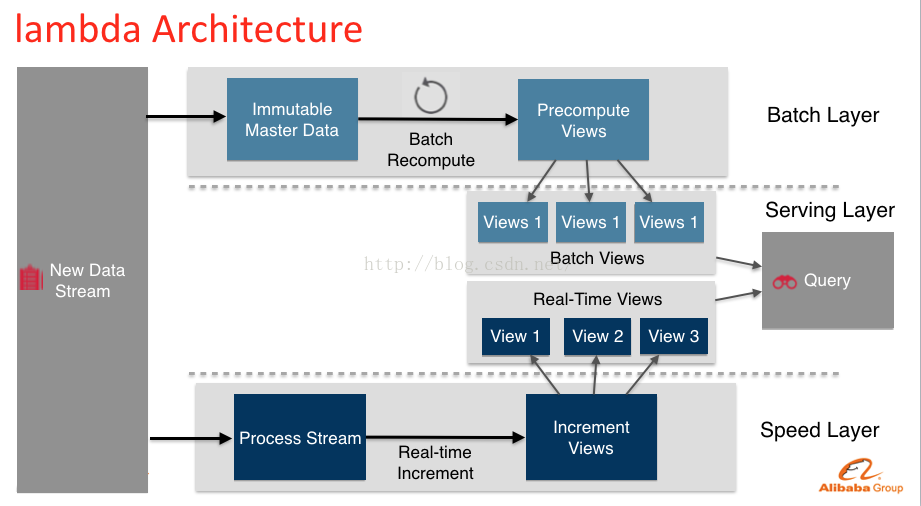
圖(C)
在Lambda架構中,實現(A)batch view =function(all data)的部份稱之為BatchLayer。他承當兩個職責:
a、存儲MasterDataset,這是1個不變的延續增長的數據集
b、針對這個MasterDataset進行預運算
在全部數據集上在線運行查詢函數得到結果的代價太大,同時處理查詢時間太長,致使用戶體驗不好。如果我們預先在數據集上計算并保存預計算的結果,查詢的時候直接返回預計算的結果,而無需重新進行復制耗時的計算。明顯,batchview是1個批處理進程,如采取Hadoop或spark支持的map-reduce方式。采取這類方式計算得到的每一個view都支持再次計算,且每次計算的結果都相同。
圖(D)
對View的理解:
View是1個和業務關聯性比較大的概念,View的創建需要從業務本身的需求動身。1個通用的數據庫查詢系統,查詢對應的函數千變萬化,不可能窮舉。但是如果從業務本身的需求動身,可以發現業務所需要的查詢常常是有限的。BatchLayer需要做的1件重要的工作就是根據業務的需求,考察可能需要的各種查詢,根據查詢定義其在數據集上對應的Views。
Batch Layer的Immutabledata模型和Views
如圖(E)坐席(agentid=50023)的人,在10:00:06分的時候,狀態是calling,在10:00:10的時候狀態為waiting。在傳統的數據庫設計中,直接后面的紀錄覆蓋前面的紀錄,而在Immutable數據模型中,不會對原有數據進行更改,而是采取插入修改紀錄的情勢更改歷史紀錄。
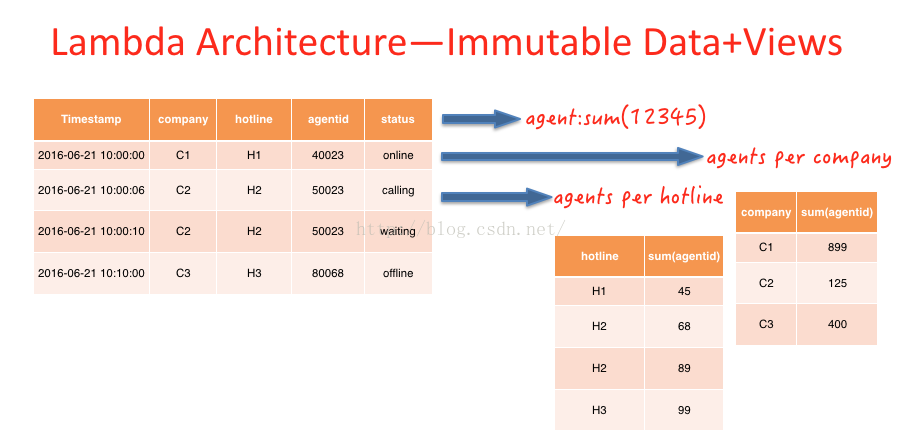
圖(E)
上文所提及的View是圖(E)中預先計算得到的相干視圖,例如:2016-06⑵1當天所有上線的agent數,每條熱線、公司下上線的Agent數。根據業務需要,預先計算出結果。此進程相當于傳統數倉建模的利用層,利用層也是根據業務場景,預先加工出的view。
BatchLayer能夠很好的處理離線數據,但是在很多場景數據不斷產生,并且業務場景需要實時查詢。SpeedLayer就是設計用來處理增量實時數據。
SpeedLayer和BatchLayer比較類似,對數據進行計算并生成RealtimeView,其主要的區分在于:
a、SpeedLayer處理的數據是最近的增量數據流,BatchLayer處理的是全部數據集
b、SpeedLayer為了效力,接收到新數據及時更新RealtimeView,而BatchLayer根據全部離線數據直接得到BatchView。SpeedLayer是1種增量計算,而非重新計算(recomputation)。
c、SpeedLayer由于采取增量計算,所以延遲小,而BatchLayer是全數據集的計算,耗時比較長。
綜上所訴,SpeedLayer是BatchLayer在實時性上的1個補充。如圖(F)

圖(F)
SpeedLayer可總結為以(C)RealtimeView=function(RealtimeView,newdata);
LambdaArchitecture將數據處理分解為BatchLayer和SpeedLayer有以下優點:
a、容錯性:SpeedLayer中處理的數據不斷寫入BatchLayer,當BatchLayer中重新計算數據集包括SpeedLayer處理的數據集后,當前的RealtimeView就能夠拋棄,這就意味著SpeedLayer處理中引入的毛病,在BatchLayer重新計算時都可以得到修證。這點也能夠看成時CAP理論中的終究1致性(EventualConsistency)的體現。
b、復雜性隔離。BatchLayer處理的是離線數據,可以很好的掌控。Speed Layer采取增量算法處理實時數據,復雜性比Batch Layer要高很多。通過分開BatchLayer和Speed Layer,把復雜性隔離到Speed Layer,可以很好的提高全部系統的魯棒性和可靠性。
BatchLayer通過對MasterDataset履行查詢取得BatchView,Speed Layer通過增量計算提供RealtimeView。Lambda架構的ServingLayer用于響利用戶的查詢要求,合并BatchView和Realtime View中的結果數據集到終究的數據集,如圖(G)。因此,ServingLayer的職責包括:
a、對batchView和RealTimeView的隨機訪問
b、更新BatchVeiw和RealTimeView,并負責結合二者的數據,對用戶提供統1的接口

圖(G)
綜上所訴,ServingLayer采取以下等式(D)表示:Query=function(BatchViews,RealtimeView)。
下圖給出了Lambda架構中各組件在大數據生態系統中和阿里團體的經常使用組件。數據流存儲選用不可變日志的散布式系統Kafa、TT、Metaq;BatchLayer數據集的存儲選用Hadoop的HDFS或阿里云的ODPS;BatchView的加工采取MapReduce;BatchView數據的存儲采取Mysql(查詢少許的最近結果數據)、Hbase(查詢大量的歷史結果數據)。SpeedLayer采取增量數據處理Storm、Flink;RealtimeView增量結果數據集采取內存數據庫Redis。
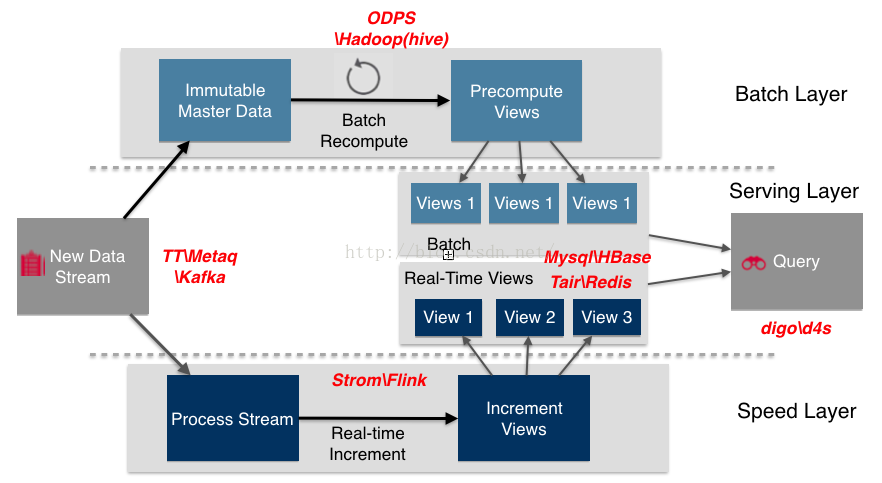
圖(H)
Lambda是1個通用框架,各模塊選型不要局限于上面給出的組件,特別是view的選型。由于View是和各業務關聯非常大的概念,View選擇組件時要根據業務的需求,選擇最適合的組件。
優點:
a、數據的不可變性。里面給出的數據傳輸模型是在初始化階段對數據進行實例化,這樣的做法是能獲益很多的。能夠使得大量的MapReduce工作變得有跡可循,從而便于在不同階段進行獨立調試。
b、強調了數據的重新計算問題。在流處理中重新計算是個主要挑戰,但是常常被忽視。比方說,某工作流的數據輸出是由輸入決定的,那末1旦代碼產生改動,我們將不能不重新計算來檢視變更的效度。甚么情況下代碼會改動呢?例如需求產生變更,計算字段需要調劑或程序發出毛病,需要進行調試。
缺點:
a、Jay Kreps認為Lambda包括固有的開發和運維的復雜性。Lambda需要將所有的算法實現兩次,1次是為批處理系統,另外一次是為實時系統,還要求查詢得到的是兩個系統結果的合并。
由于存在以上缺點,Linkedin的Jaykreps提出了Kappa架構如圖(I):
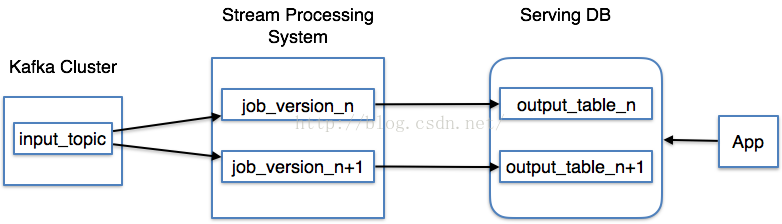
圖(I)
1、使用Kafka或其它系統來對需要重新計算的數據進行日志記錄,和提供給多個定閱者使用。例如需要重新計算30天內的數據,我們可以在Kafka中設置30天的數據保存值。
2、當需要進行重新計算時,啟動流處理作業的第2個實例對之前取得的數據進行處理,以后直接把結果數據放入新的數據輸出表中。
3、當作業完成時,讓利用程序直接讀取新的數據記錄表。
4、停止歷史作業,刪除舊的數據輸出表。
Kappa架構暫時未做深入了解,在此不做評價。我個人覺得,不同的數據架構有各自的優缺點,我們使用的時候只能根據利用場景,選擇更適合的架構,才能取長補短。
參考資料:
Big Data:Principles and best practices of scalable real-time data systems——Nathan Marz
http://blog.csdn.net/brucesea/article/details/45937875
https://zhuanlan.zhihu.com/p/20510974
http://www.infoq.com/cn/news/2014/09/lambda-architecture-questions

上一篇 Nginx之負載均衡
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


