Google深度學習筆記 文本與序列的深度模型
來源:程序員人生 發(fā)布時間:2016-07-14 08:34:27 閱讀次數:2951次
Deep Models for Text and Sequence
轉載請注明作者:夢里風林
Github工程地址:https://github.com/ahangchen/GDLnotes
歡迎star,有問題可以到Issue區(qū)討論
官方教程地址
視頻/字幕下載
Rare Event
與其他機器學習不同,在文本分析里,陌生的東西(rare event)常常是最重要的,而最多見的東西常常是最不重要的。
語法多義性
- 1個東西可能有多個名字,對這類related文本能夠做參數同享是最好的
- 需要辨認單詞,還要辨認其關系,就需要過量label數據
無監(jiān)督學習
- 不用label進行訓練,訓練文本是非常多的,關鍵是要找到訓練的內容
- 遵守這樣1個思想:類似的辭匯出現在類似的場景中
- 不需要知道1個詞真實的含義,詞的含義由它所處的歷史環(huán)境決定
Embeddings
- 將單詞映照到1個向量(Word2Vec),越類似的單詞的向量會越接近
- 新的詞可以由語境得到同享參數
Word2Vec
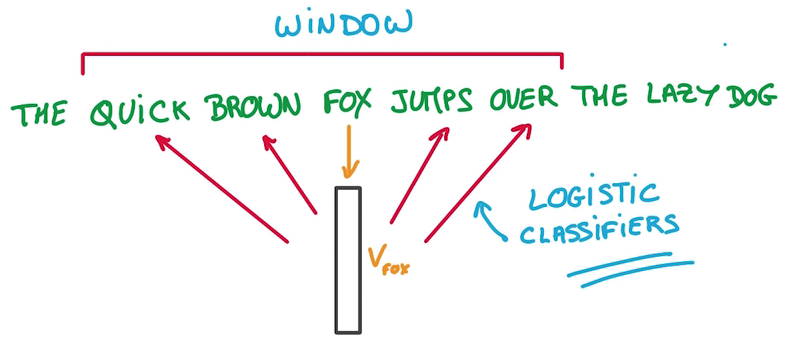
- 將每一個詞映照到1個Vector列表(就是1個Embeddings)里,1開始隨機,用這個Embedding進行預測
- Context即Vector列表里的鄰居
- 目標是讓Window里相近的詞放在相鄰的位置,即預測1個詞的鄰居
- 用來預測這些相鄰位置單詞的模型只是1個Logistics Regression, just a simple Linear model
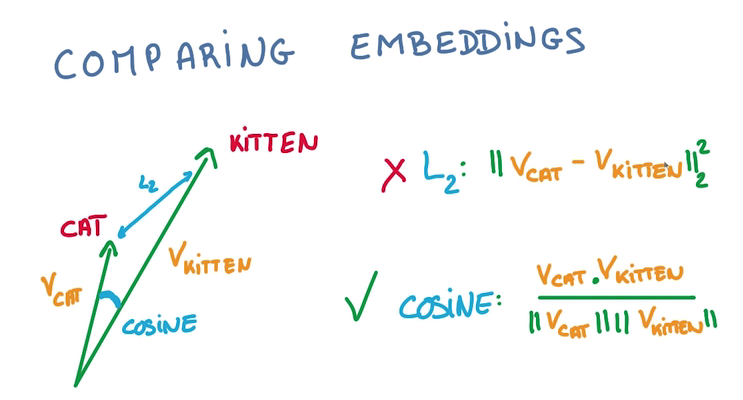
Comparing embeddings
- 比較兩個vector之間的夾角大小來判斷接近程度,用cos值而非L2計算,由于vector的長度和分類是不相干的:
Predict Words
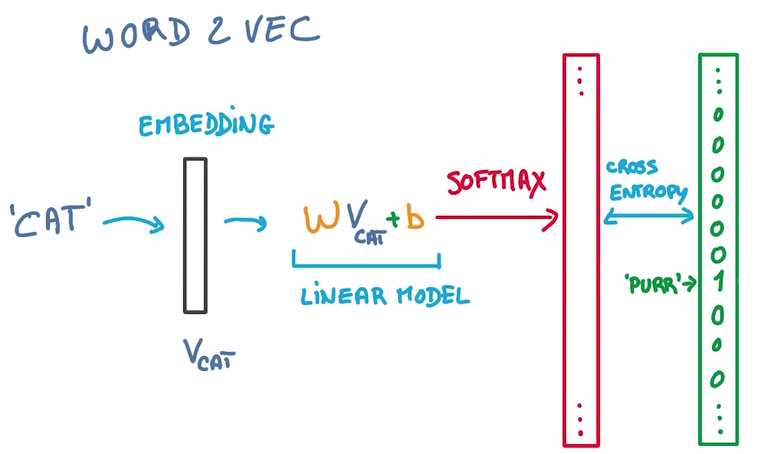
- 單詞經過embedding變成1個vector
- 然后輸入1個WX+b,做1個線性模型
- 輸出的label幾率為輸入文本中的辭匯
- 問題在于WX+b輸出時,label太多了,計算這類softmax很低效
- 解決方法是,篩掉不多是目標的label,只計算某個label在某個局部的幾率,sample softmax
t-SNE
- 查看某個詞在embedding里的最近鄰居可以看到單詞間的語義接近關系
- 將vector構成的空間降維,可以更高效地查找最近單詞,但降維進程中要保持鄰居關系(原來接近的降維后還要接近)
- t-SNE就是這樣1種有效的方法
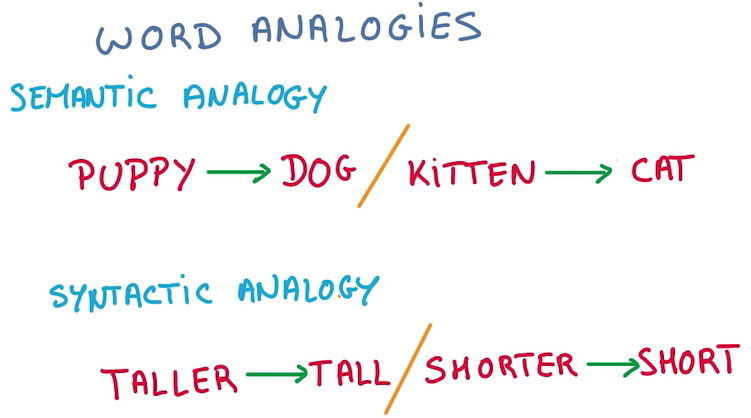
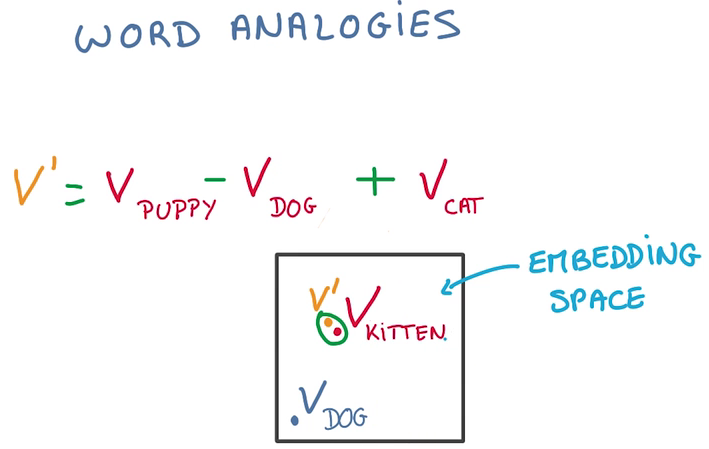
類比
- 實際上我們能得到的不但是單詞的鄰接關系,由于將單詞向量化,可以對單詞進行計算
- 可以通過計算進行語義加減,語法加減
Sequence
文本(Text)是單詞(word)的序列,1個關鍵特點是長度可變,就不能直接變成vector
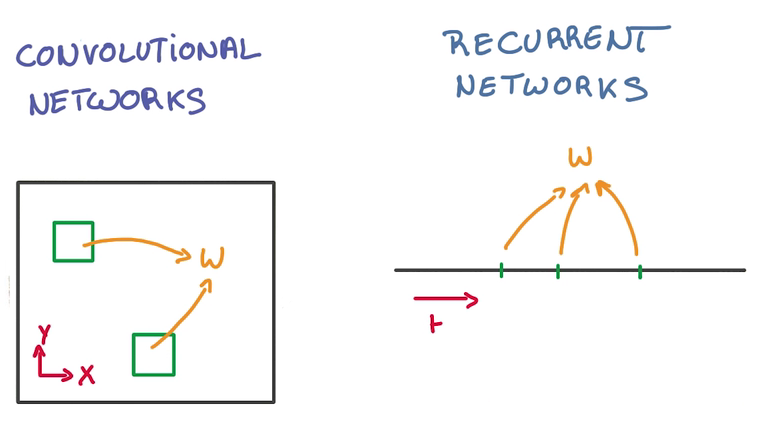
CNN and RNN
CNN 在空間上同享參數,RNN在時間上(順序上)同享參數
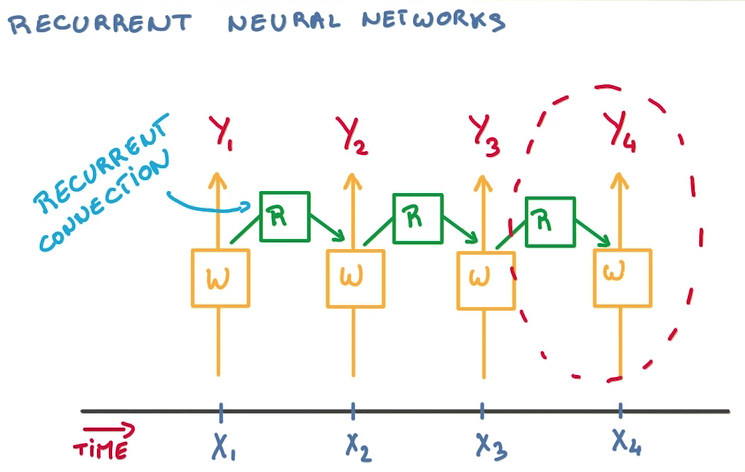
- 在每輪訓練中,需要判斷至今為之產生了甚么,過去輸入的所有數據都對當下的分類造成影響
- 1種思路是記憶之前的分類器的狀態(tài),在這個基礎上訓練新的分類器,從而結合歷史影響
- 這樣需要大量歷史分類器
- 重用分類器,只用1個分類器總結狀態(tài),其他分類器接受對應時間的訓練,然后傳遞狀態(tài)
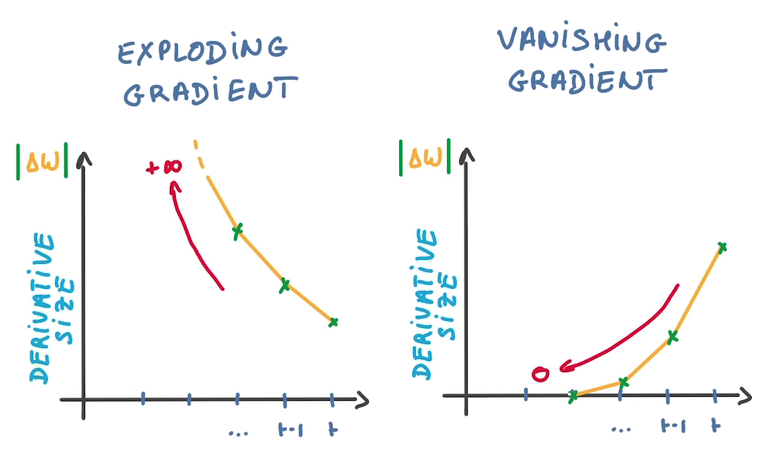
RNN Derivatives
- BackPropagation Through time
- 對同1個weight參數,會有許多求導操作同時更新之
- 對SGD不友好,由于SGD是用許多不相干的求導更新參數,以保證訓練的穩(wěn)定性
- 由于梯度之間的相干性,致使梯度爆炸或梯度消失
Clip Gradient
計算到梯度爆炸的時候,使用1個比值來代替△W(梯度是回流計算的,橫坐標從右往左看)
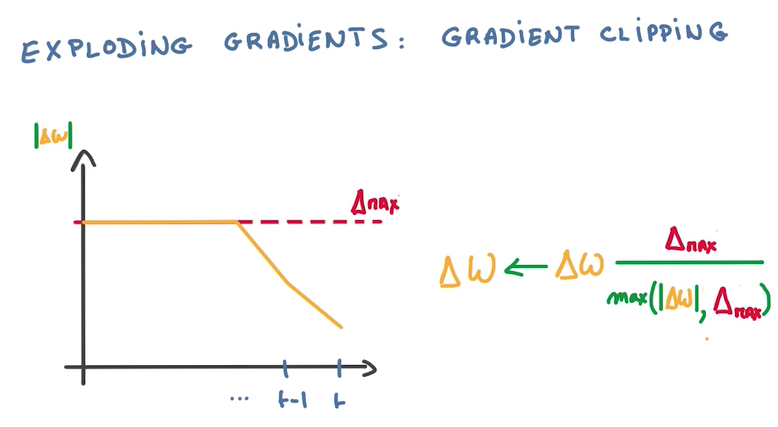
- Hack but cheap and effective
LSTM(Long Short-Term Memory)
梯度消失會致使分類器只對最近的消息的變化有反應,淡化之前訓練的參數,也不能用比值的方法來解決
- 1個RNN的model包括兩個輸入,1個是過去狀態(tài),1個是新的數據,兩個輸出,1個是預測,1個是將來狀態(tài)
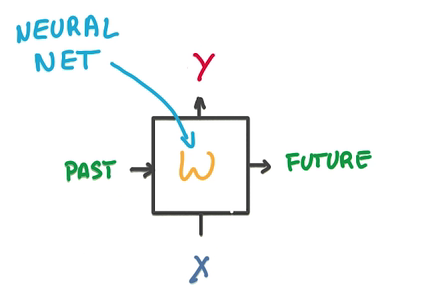
- 中間是1個簡單的神經網絡
- 將中間的部份換成LSTM-cell就可以解決梯度消失問題
- 我們的目的是提高RNN的記憶能力
- Memory Cell
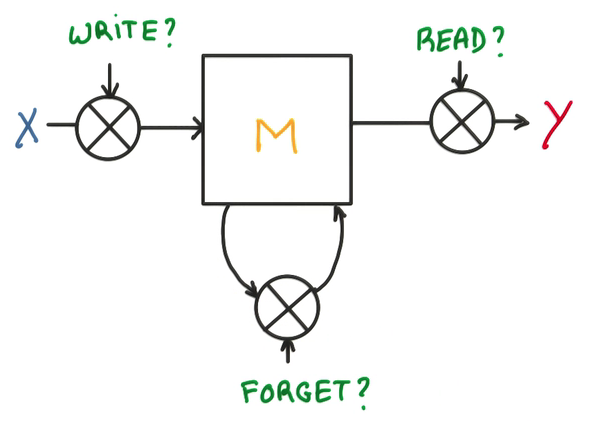
3個門,決定是不是寫/讀/遺忘/寫回
- 在每一個門上,不單純做yes/no的判斷,而是使用1個權重,決定對輸入的接收程度
- 這個權重是1個連續(xù)的函數,可以求導,也就能夠進行訓練,這是LSTM的核心
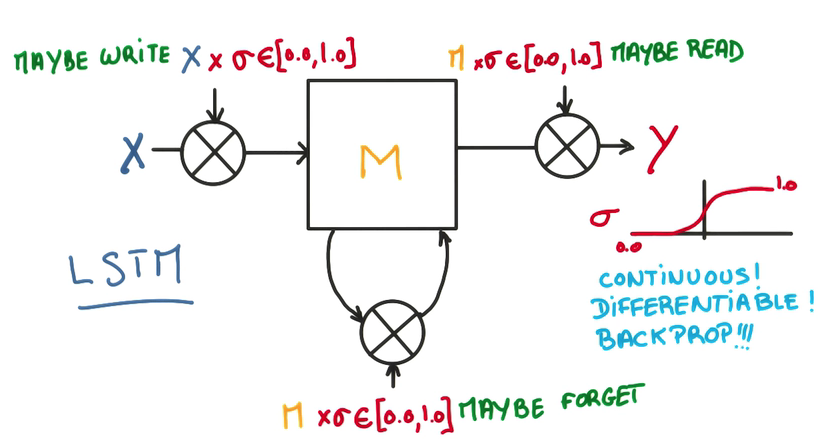
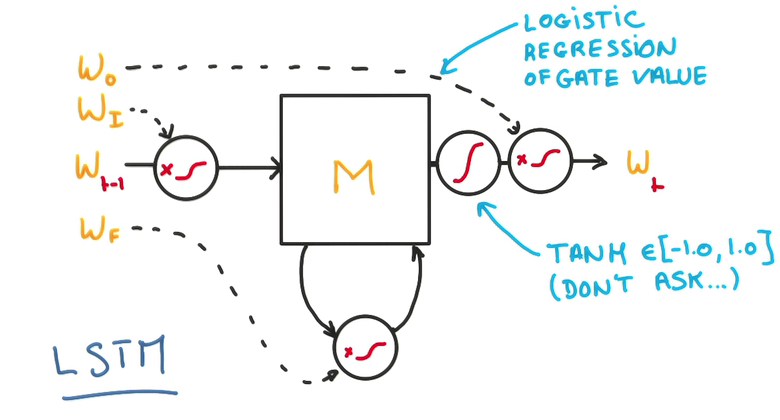
- 這樣的模型能讓全部cell更好地記憶與遺忘
- 由于全部模型都是線性的,所以可以方便地求導和訓練
LSTM Regularization
- L2, works
- Dropout on the input or output of data, works
Beam Search
有了上面的模型以后,我們可以根據上文來推測下文,乃至創(chuàng)造下文,預測,挑選最大幾率的詞,喂回,繼續(xù)預測……
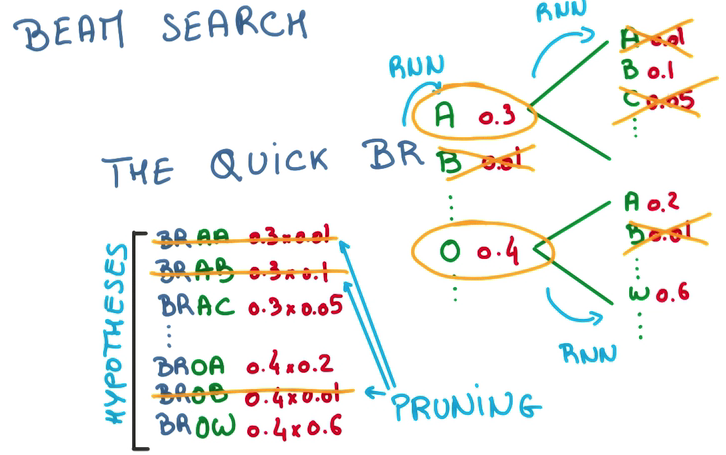
- 我們可以每次只預測1個字母,but this is greedy,每次都挑最好的那個
- 也能夠每次多預測幾步,然后挑整體幾率較高的那個,以減少偶然因素的影響
- 但這樣需要生成的sequence會指數增長
- 因此我們在多預測幾步的時候,只為幾率比較高的幾個候選項做預測,that’s beam search.
翻譯與識圖
循環(huán)神經網絡實踐
覺得我的文章對您有幫助的話,給個star可好?
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈




