
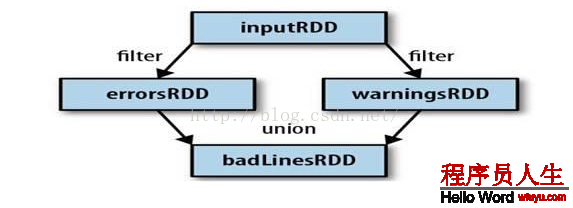
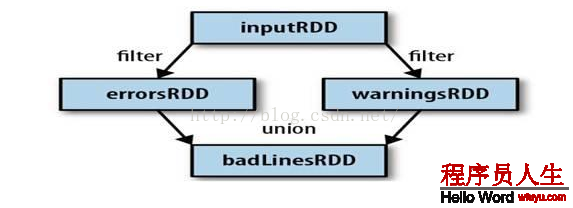
3、Spark會(huì)使用譜系圖來記錄這些不同RDD之間的依賴關(guān)系,Spark需要用這些信息來按需計(jì)算每一個(gè)RDD,也能夠依托譜系圖在持久化的RDD丟失部份數(shù)據(jù)時(shí)用來恢復(fù)所丟失的數(shù)據(jù)。(以下圖,過濾errorsRDD與warningsRDD,終究調(diào)用union函數(shù))
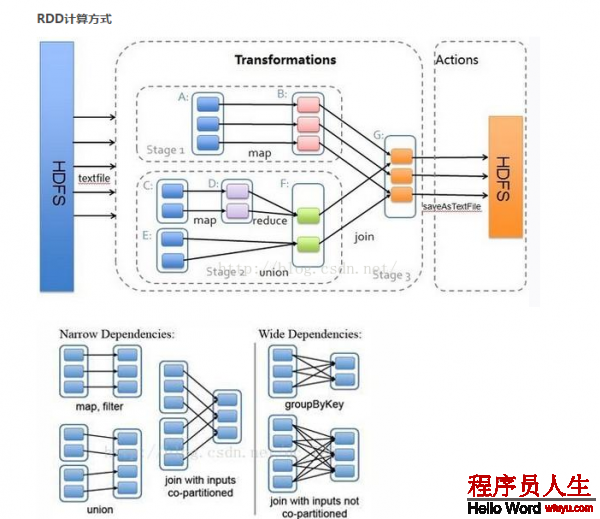
窄依賴 (narrowdependencies) 和寬依賴 (widedependencies) 。窄依賴是指 父 RDD 的每一個(gè)分區(qū)都只被子 RDD 的1個(gè)分區(qū)所使用 。相應(yīng)的,那末寬依賴就是指父 RDD 的分區(qū)被多個(gè)子 RDD 的分區(qū)所依賴。例如, map 就是1種窄依賴,而 join 則會(huì)致使寬依賴
這類劃分有兩個(gè)用途。首先,窄依賴支持在1個(gè)結(jié)點(diǎn)上管道化履行。例如基于1對1的關(guān)系,可以在 filter 以后履行 map 。其次,窄依賴支持更高效的故障還原。由于對窄依賴,只有丟失的父 RDD 的分區(qū)需要重新計(jì)算。而對寬依賴,1個(gè)結(jié)點(diǎn)的故障可能致使來自所有父 RDD 的分區(qū)丟失,因此就需要完全重新履行。因此對寬依賴,Spark 會(huì)在持有各個(gè)父分區(qū)的結(jié)點(diǎn)上,將中間數(shù)據(jù)持久化來簡化故障還原,就像 MapReduce 會(huì)持久化 map 的輸出1樣。
RDD工作原理:
RDD(Resilient DistributedDatasets)[1] ,彈性散布式數(shù)據(jù)集,是散布式內(nèi)存的1個(gè)抽象概念,RDD提供了1種高度受限的同享內(nèi)存模型,即RDD是只讀的記錄分區(qū)的集合,只能通過在其他RDD履行肯定的轉(zhuǎn)換操作(如map、join和group by)而創(chuàng)建,但是這些限制使得實(shí)現(xiàn)容錯(cuò)的開消很低。對開發(fā)者而言,RDD可以看做是Spark的1個(gè)對象,它本身運(yùn)行于內(nèi)存中,如讀文件是1個(gè)RDD,對文件計(jì)算是1個(gè)RDD,結(jié)果集也是1個(gè)RDD,不同的分片、數(shù)據(jù)之間的依賴、key-value類型的map數(shù)據(jù)都可以看作RDD。
主要分為3部份:創(chuàng)建RDD對象,DAG調(diào)度器創(chuàng)建履行計(jì)劃,Task調(diào)度器分配任務(wù)并調(diào)度Worker開始運(yùn)行。
SparkContext(RDD相干操作)→通過(提交作業(yè))→(遍歷RDD拆分stage→生成作業(yè))DAGScheduler→通過(提交任務(wù)集)→任務(wù)調(diào)度管理(TaskScheduler)→通過(依照資源獲得任務(wù))→任務(wù)調(diào)度管理(TaskSetManager)
Transformation返回值還是1個(gè)RDD。它使用了鏈?zhǔn)秸{(diào)用的設(shè)計(jì)模式,對1個(gè)RDD進(jìn)行計(jì)算后,變換成另外1個(gè)RDD,然后這個(gè)RDD又可以進(jìn)行另外1次轉(zhuǎn)換。這個(gè)進(jìn)程是散布式的。
Action返回值不是1個(gè)RDD。它要末是1個(gè)Scala的普通集合,要末是1個(gè)值,要末是空,終究或返回到Driver程序,或把RDD寫入到文件系統(tǒng)中
轉(zhuǎn)換(Transformations)(如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是說從1個(gè)RDD轉(zhuǎn)換生成另外一個(gè)RDD的操作不是馬上履行,Spark在遇到Transformations操作時(shí)只會(huì)記錄需要這樣的操作,其實(shí)不會(huì)去履行,需要等到有Actions操作的時(shí)候才會(huì)真正啟動(dòng)計(jì)算進(jìn)程進(jìn)行計(jì)算。
操作(Actions)(如:count, collect, save等),Actions操作會(huì)返回結(jié)果或把RDD數(shù)據(jù)寫到存儲(chǔ)系統(tǒng)中。Actions是觸發(fā)Spark啟動(dòng)計(jì)算的動(dòng)因。
它們本質(zhì)區(qū)分是:Transformation返回值還是1個(gè)RDD。它使用了鏈?zhǔn)秸{(diào)用的設(shè)計(jì)模式,對1個(gè)RDD進(jìn)行計(jì)算后,變換成另外1個(gè)RDD,然后這個(gè)RDD又可以進(jìn)行另外1次轉(zhuǎn)換。這個(gè)進(jìn)程是散布式的。Action返回值不是1個(gè)RDD。它要末是1個(gè)Scala的普通集合,要末是1個(gè)值,要末是空,終究或返回到Driver程序,或把RDD寫入到文件系統(tǒng)中。關(guān)于這兩個(gè)動(dòng)作,在Spark開發(fā)指南中會(huì)有就進(jìn)1步的詳細(xì)介紹,它們是基于Spark開發(fā)的核心。
參考:http://www.itshipin.com/article/article110.html

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


