
本講內容:
a. 數據接收架構設計模式
b. 數據接收源碼完全研究
注:本講內容基于Spark 1.6.1版本(在2016年5月來講是Spark最新版本)講授。
上節回顧
上1講中,我們給大家具體分析了Receiver啟動的方式及其啟動設計帶來的多個問題:
a. 如果有多個InputDStream,那就要啟動多個Receiver,每一個Receiver也就相當于分片partition,那我啟動Receiver的時候理想的情況下是在不同的機器上啟動Receiver,但是Spark Core的角度來看就是利用程序,感覺不到Receiver的特殊性,所以就會依照正常的Job啟動的方式來處理,極有可能在1個Executor上啟動多個Receiver;這樣的話便可能致使負載不均衡
b. 有可能啟動Receiver失敗,只要集群存在,Receiver就不應當啟動失敗
c. 從運行進程中看,1個Reveiver就是1個partition的話,Reveiver的啟動伴隨1個Task啟動,如果Task啟動失敗,以Task啟動的Receiver也會失敗
由此,我們通過源碼分析,完全解析了Spark Streaming是如何解決這些問題的:
a. Spark使用1個Job啟動1個Receiver.最大程度的保證了負載均衡
b. Spark Streaming已指定每一個Receiver運行在那些Executor上,在Receiver運行之前就指定了運行的地方
c. 如果Receiver啟動失敗,此時其實不是Job失敗,在內部會重新啟動Receiver
開講
本講我們主要給大家介紹Spark Streaming在接收數據的全生命周期貫通;
a. 當有Spark Streaming有利用程序的時候Spark Streaming會延續不斷的接收數據
b. 1般Receiver和Driver不在1個進程中的,所以接收到數據以后要不斷的匯報給Driver
c. Spark Streaming要接收數據肯定要使用消息循環器,循環器不斷的接收到數據以后,然后將數據存儲起來,再將存儲完的數據匯報給Driver
d. Sparkstreaming接收數據的全部流程類似于MVC模式,M就是Receiver,V就是Driver,C就是ReceiverSupervisor
e. ReceiverSupervisor是控制器,Receiver的啟動是靠ReceiverTracker啟動的,Receiver接收到數據以后是靠ReceiverSupervisor存儲數據的。然后Driver就取得元數據也就是界面,通過界面來操作底層的數據,這個元數據就相當于指針
Spark Streaming接收數據流程以下:
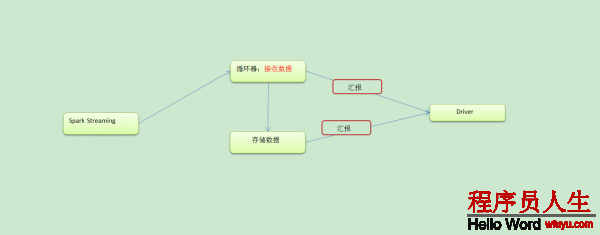
接收數據的時候肯定有1個循環器不斷的接收數據,接收到數據肯定也有存儲器,存儲過以后向Driver匯報。接收數據和存儲數據固然要分為兩個不同的模塊。
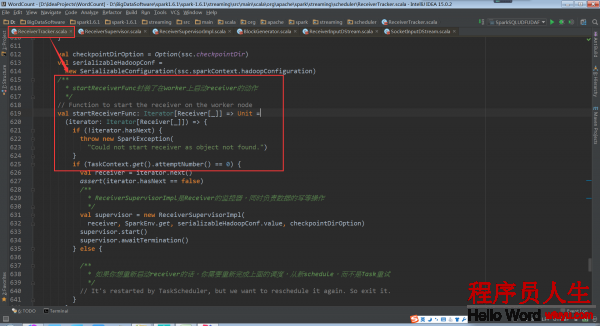
ReceiverSupervisorImpl是receiver的監控器,同時負責receiver的寫操作 這個方法需要傳入1個Iterator,實時上里邊就只有1個Receiver
取得receiver,這個receiver是根據數據輸入來源InputDstream取得的receiver。以SocketInputDstream為例,它的receiver就是SocketReceiver.這里的receiver只是1個援用,并沒有被實例化。作為1個參數傳入ReceiverSupervisorImpl
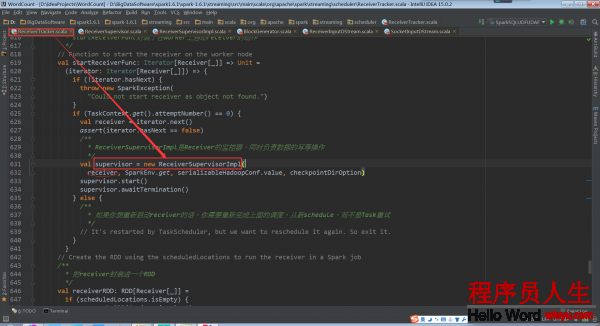
為了啟動Receiver啟動了1個spark作業,每個Receiver的啟動都會有1個作業來負責,Receiver是1個1個的啟動的如果是將所有的Receiver作為1個作業的不同task來啟動會有很多弱點
a. Reciver啟動可能失敗進而致使利用程序失敗
b. 運行的進程中會有任務傾斜的問題,將所有的Receiver作為1個作業的不同task來運行是采取的spark core的調度方式,在很不幸的情況下會出現所有Receiver運行在1個節點上,Receiver要不斷的接收數據,需要消耗很多資源,就會致使這個節點負載特別大。
將每一個Receiver都作為1個job來運行就會最大可能的負載均衡,不過這樣也有可能失敗,失敗以后不會重試job,而是重新schedule提交1個新的job來運行
Receiver,并且不會在之前運行的executor上啟動,只要sparkstreaming程序不停止,假設Receiver出故障就會不停止的進行重新echedule并啟動,確保Receiver1定會啟動還有很重要的1點是,當重新啟動1個Receiver時,是用1個線程池在新的線程中啟動的
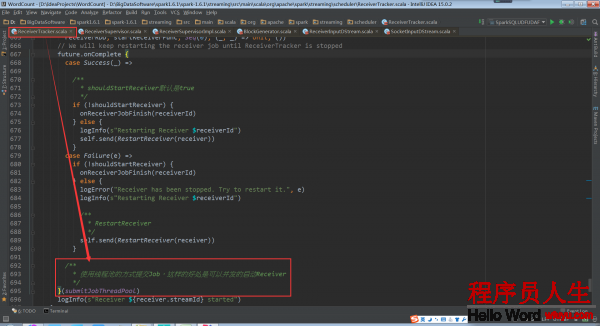
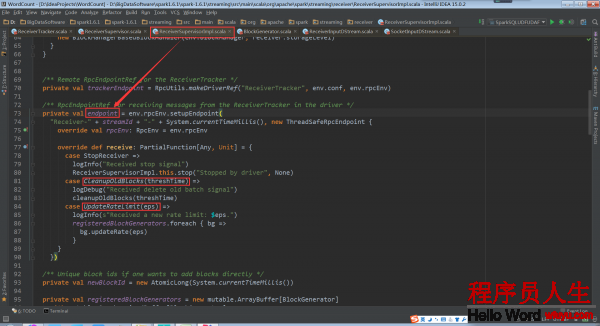
ReceiverSupervisorImpl負責處理Receiver接收到的數據,處理以后匯報給ReceiverTracker,所以ReceiverSupervisorImpl內部有和ReceiverTracker進行通訊的endpoint。這個負責向ReceiverTracker發送消息。
private val trackerEndpoint = RpcUtils.makeDriverRef(“ReceiverTracker”, env.conf,env.rpcEnv)
這個負責接收ReceiverTracker發送的消息,CleanupOldBlocks是用來清除運行完的每一個batch的Blocks,UpdateRateLimit是用來隨時調劑限流(限流實際上是限的數據存儲的速度)
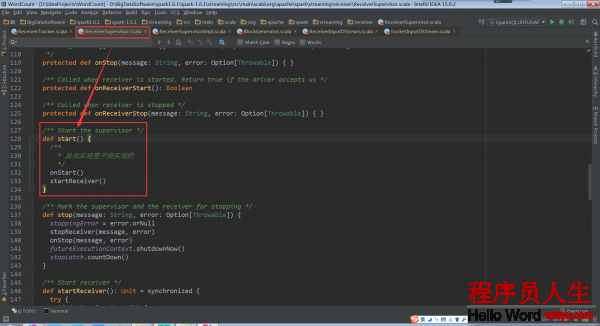
ReceiverSupervisor的start方法
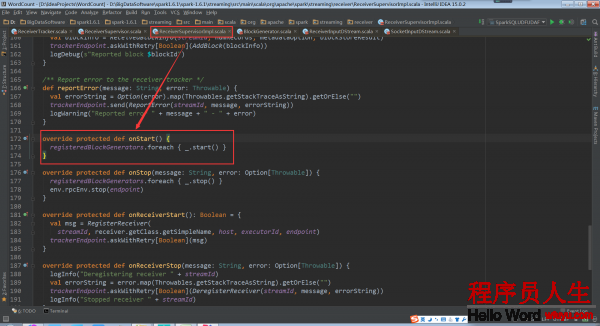
在onStart中啟動的是BlockGenerator,BlockGenerator是把接收到的1條1條的數據生成block存儲起來,1個BlockGenerator只服務于1個Receiver。所以BlockGenerator要在Receiver啟動之前啟動
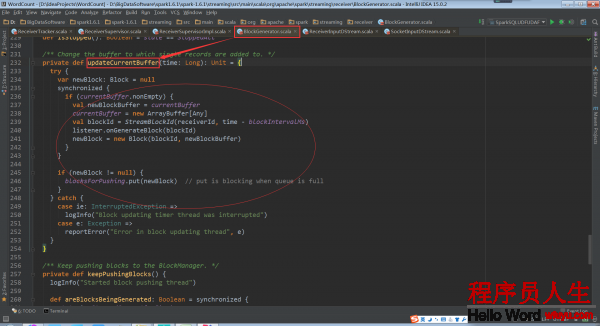
BlockGenerator種有1個定時器。這個定時器每隔1定(默許是200ms,和設定的batchduration無關)的時間就履行以下方法。這個方法就是把接收到的數據1條1條的放入到這個buffer緩存中,再把這個buffer依照1定的時間或尺寸合并成block。除定時器之外還有1條線程不停的把生成的block交給blockmanager存儲起來。
下面來看startReceiver方法
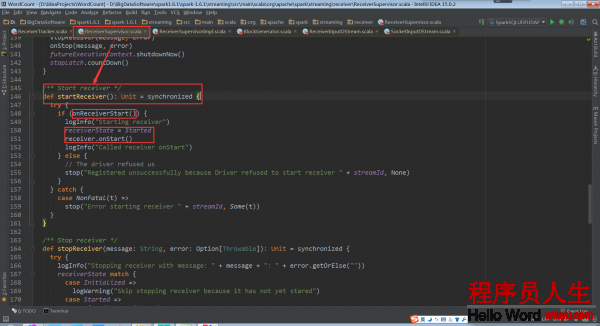
在啟動Receiver之前還要向ReceiverTracker要求是不是可以啟動Receiver。當返回是true才會啟動。ReceiverTracker接收到匯報的信息就把注冊Receiver的信息。
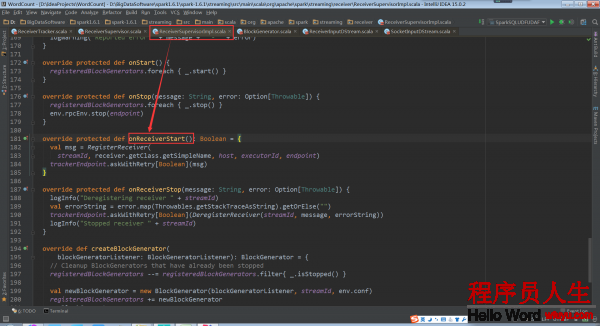
Receiver的啟動只是調用receiver.onStart(),Receiver就在work節點上運行了
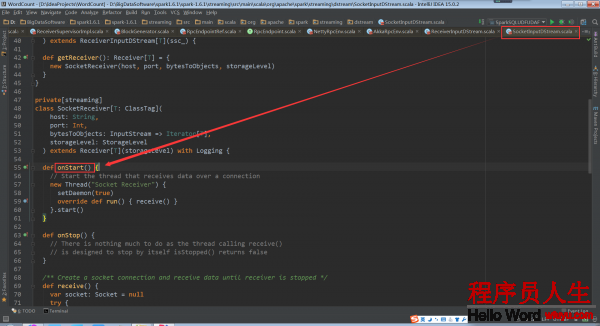
以SocketReceiver為例我看看它的onStart方法
備注:
1、DT大數據夢工廠微信公眾號DT_Spark
2、Spark大神級專家:王家林
3、新浪微博: http://www.weibo.com/ilovepains

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


