您當前位置:
首頁 >
服務器 > Apache Spark的設計思路
Apache Spark的設計思路
來源:程序員人生 發布時間:2015-08-03 09:13:45 閱讀次數:2751次
大家都知道,現在Apache Spark可以說是最火的開源大數據項目,就連EMC旗下專門做大數據Pivotal也開始拋棄其自研10幾年GreenPlum技術,轉而投入到Spark技術開發當中,并且從全部業界而言,Spark火的程度也只有IaaS界的OpenStack能等量齊觀。那末本文作為1篇技術文章,我們接著就直接切入它的核心機制吧。
 甚么是內存計算技術?
關于內存計算,就像云計算和大數據1樣,其實不管在百度百科還是Wikipedia都沒有非常精確的描寫,但是有幾個共通的關鍵點,我在這里給大家總結1下:其1是數據放在內存中,最少和當前查詢工作觸及到的數據放在都要放在內存中;其2是多線程和多機并行,也就是盡量地利用現代x86 Xeon CPU線程數多的優勢來加速全部查詢;其3是支持多種類型的工作負載,除常見和基本的SQL查詢以后,還通常支持數據發掘,更有甚者支持Full
Stack(全棧),也就是常見編程模型都要支持,比如說SQL查詢,流計算和數據發掘等。
Apache Spark的設計思路
大家都知道,現在Apache Spark可以說是最火的開源大數據項目,就連EMC旗下專門做大數據Pivotal也開始拋棄其自研10幾年GreenPlum技術,轉而投入到Spark技術開發當中,并且從全部業界而言,Spark火的程度也只有IaaS界的OpenStack能等量齊觀。那末本文作為1篇技術文章,我們接著就直接切入它的核心機制吧。
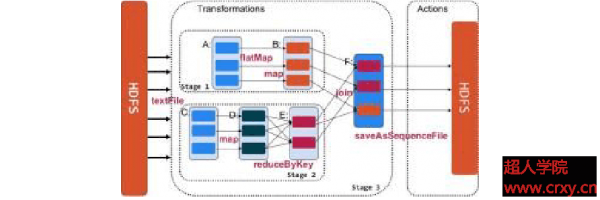
圖1. Spark的核心機制圖
在Spark的核心機制方面,主要有兩個層面:首先是RDD(Resilient Distributed Datasets),RDD是Spark的最基本抽象,是對散布式內存的抽象使用,實現了以操作本地集合的方式來操作散布式數據集的抽象實現,它表示已被分區,不可變的并能夠被并行操作的數據集合,并且通常緩存到內存中,并且每次對RDD數據集的操作以后的結果,都可以寄存到內存中,下1個操作可以直接從內存中輸入,省去了Map
Reduce框架中由于Shuffle操作所引發的大量磁盤IO。這對迭代運算比較常見的機器學習算法, 交互式數據發掘來講,效力提升比較大。
其次,就是在RDD上面履行的算子(Operator),在Spark的支持算子方面,主要有轉換(Transformation)和操作(Action)這兩大類。在轉換方面支持算子有 map, filter,groupBy和join等,而在操作方面支持算子有count,collect和save等。
Spark常見存儲數據的格式是Key-Value,也就是Hadoop標準的Sequence File,但同時也聽說支持類似Parquet這樣的列存格式。Key-Value格式的優點在于靈活,上至數據發掘算法,明細數據查詢,下至復雜SQL處理都能承載,缺點也很明顯就是存儲空間比較浪費,和類似Parquet列存格式相比更是如此,key-Value格式數據1般是原始數據大小的2倍左右,而列存1般是原始數據的1/3到1/4。
在效力層面,由于?使用Scala這樣基于JVM的高級語言來構建,不言而喻會有1定程度的損失,標準Java程序履行時候的速度基本接近C/C++ O0模式的程度,會比C/C++ O2模式的速度慢60%左右。
在技術創新方面,個人覺得Spark還談不上創新,由于它其實屬于比較典型In-Memory Data Grid內存數據網格,不管從7⑻年前的IBM WebSphere eXtreme Scale到最近幾年新出,并用于12306的Pivotal Gemfire都采取較類似的架構,都主要通過量臺機器拼成1個較大內存網格,里面存儲的數據都接近Key-Value模式,并且這個內存網格會根據很多機制來確保數據會持久穩定地保存在內存中,并能保持數據的更新和恢復,而在網格上面使用1些常見的算子,來履行靈活的查詢,并且用戶可以寫的程序來直接調用這些算子。
甚么是內存計算技術?
關于內存計算,就像云計算和大數據1樣,其實不管在百度百科還是Wikipedia都沒有非常精確的描寫,但是有幾個共通的關鍵點,我在這里給大家總結1下:其1是數據放在內存中,最少和當前查詢工作觸及到的數據放在都要放在內存中;其2是多線程和多機并行,也就是盡量地利用現代x86 Xeon CPU線程數多的優勢來加速全部查詢;其3是支持多種類型的工作負載,除常見和基本的SQL查詢以后,還通常支持數據發掘,更有甚者支持Full
Stack(全棧),也就是常見編程模型都要支持,比如說SQL查詢,流計算和數據發掘等。
Apache Spark的設計思路
大家都知道,現在Apache Spark可以說是最火的開源大數據項目,就連EMC旗下專門做大數據Pivotal也開始拋棄其自研10幾年GreenPlum技術,轉而投入到Spark技術開發當中,并且從全部業界而言,Spark火的程度也只有IaaS界的OpenStack能等量齊觀。那末本文作為1篇技術文章,我們接著就直接切入它的核心機制吧。
圖1. Spark的核心機制圖
在Spark的核心機制方面,主要有兩個層面:首先是RDD(Resilient Distributed Datasets),RDD是Spark的最基本抽象,是對散布式內存的抽象使用,實現了以操作本地集合的方式來操作散布式數據集的抽象實現,它表示已被分區,不可變的并能夠被并行操作的數據集合,并且通常緩存到內存中,并且每次對RDD數據集的操作以后的結果,都可以寄存到內存中,下1個操作可以直接從內存中輸入,省去了Map
Reduce框架中由于Shuffle操作所引發的大量磁盤IO。這對迭代運算比較常見的機器學習算法, 交互式數據發掘來講,效力提升比較大。
其次,就是在RDD上面履行的算子(Operator),在Spark的支持算子方面,主要有轉換(Transformation)和操作(Action)這兩大類。在轉換方面支持算子有 map, filter,groupBy和join等,而在操作方面支持算子有count,collect和save等。
Spark常見存儲數據的格式是Key-Value,也就是Hadoop標準的Sequence File,但同時也聽說支持類似Parquet這樣的列存格式。Key-Value格式的優點在于靈活,上至數據發掘算法,明細數據查詢,下至復雜SQL處理都能承載,缺點也很明顯就是存儲空間比較浪費,和類似Parquet列存格式相比更是如此,key-Value格式數據1般是原始數據大小的2倍左右,而列存1般是原始數據的1/3到1/4。
在效力層面,由于?使用Scala這樣基于JVM的高級語言來構建,不言而喻會有1定程度的損失,標準Java程序履行時候的速度基本接近C/C++ O0模式的程度,會比C/C++ O2模式的速度慢60%左右。
在技術創新方面,個人覺得Spark還談不上創新,由于它其實屬于比較典型In-Memory Data Grid內存數據網格,不管從7⑻年前的IBM WebSphere eXtreme Scale到最近幾年新出,并用于12306的Pivotal Gemfire都采取較類似的架構,都主要通過量臺機器拼成1個較大內存網格,里面存儲的數據都接近Key-Value模式,并且這個內存網格會根據很多機制來確保數據會持久穩定地保存在內存中,并能保持數據的更新和恢復,而在網格上面使用1些常見的算子,來履行靈活的查詢,并且用戶可以寫的程序來直接調用這些算子。
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈

------分隔線----------------------------
------分隔線----------------------------



