Python scikit-learn 學習筆記―鳶尾花模型
來源:程序員人生 發布時間:2015-06-05 08:45:25 閱讀次數:5642次
鳶尾花數據是1個簡易有趣的數據集。這個數據集來源于科學家在1島上找到1種花的3種不同亞種別,分別叫做setosa,versicolor,virginica。但是這3個種類其實不是很好辯白,所以他們又從花萼長度,花萼寬度,花瓣長度,花瓣寬度這4個角度丈量不同的種類用于定量分析。基于這4個特點,這些數據成了1個多重變量分析的數據集。下面,我們就利用sklearn試著從不同的角度去分析1下這個數據集。
第1種思路是這樣:這3種不同的品種每種想必都會有特點或存在1定的相似性。我們無妨先把這些雜亂無章的數據分成3類,然后對應的標出他們每類的種別。如果依照這樣的想法,那末這1個問題就變成了1個聚類問題。
作為聚類問題,我們可以用k-means模型去解決。可以參考這1篇博文。網址以下:
http://blog.csdn.net/heavendai/article/details/7029465
首先大體了解1下k-means,這1種算法是非監督模型,也就是說1開始我可以不用告知它種別,讓他們自己去分類。那末怎樣去分類呢?假定我們首先將它映照到歐式空間
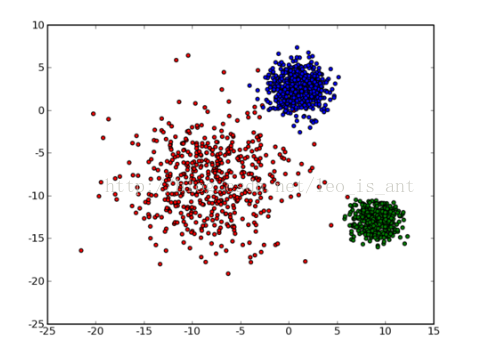
可以直觀的看出來,圖中把點分成了3類。然后我們做出這樣1種假定:每類有1個中心點,這1類的絕大部份點到中心點的距離應當是小于到其他類中心點的距離的。之所以說絕大部份是由于斟酌到點的特例,我們不能由于單獨的幾個點而否定之前的大部份。基于這1個思想我們可以肯定所要優化的目標函數,我們假定分類N個數據到K個種別,則有:
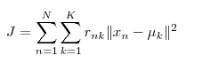
其中的rnk意味著歸類到k時為1,剩下為0.剩下的具體如何優化這里不在詳細說了。
我們來看實現代碼
<span style="font-family:Microsoft YaHei;">from sklearn.cluster import KMeans
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
clf=KMeans(n_clusters=3)
model=clf.fit(X)
predicted=model.predict(X)</span>
這里調用了聚類器KMeans,由于已知3類我們讓其中的clusters中心點為3就能夠了。
KMeans的參數除聚類個數以外還有max_iter,n_init,init,precompute_distances等。具體的參數含義解釋以下網址:
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
如果想更加直觀1點的話,官網有鳶尾花數據在k-means上的1個demo網址以下:
我們po出代碼:
<span style="font-family:Microsoft YaHei;">print(__doc__)
# Code source: Gaël Varoquaux
# Modified for documentation by Jaques Grobler
# License: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
from sklearn import datasets
np.random.seed(5)
centers = [[1, 1], [⑴, ⑴], [1, ⑴]]
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimators = {'k_means_iris_3': KMeans(n_clusters=3),
'k_means_iris_8': KMeans(n_clusters=8),
'k_means_iris_bad_init': KMeans(n_clusters=3, n_init=1,
init='random')}
fignum = 1
for name, est in estimators.items():
fig = plt.figure(fignum, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
est.fit(X)
labels = est.labels_
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=labels.astype(np.float))
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
fignum = fignum + 1
# Plot the ground truth
fig = plt.figure(fignum, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
for name, label in [('Setosa', 0),
('Versicolour', 1),
('Virginica', 2)]:
ax.text3D(X[y == label, 3].mean(),
X[y == label, 0].mean() + 1.5,
X[y == label, 2].mean(), name,
horizontalalignment='center',
bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
# Reorder the labels to have colors matching the cluster results
y = np.choose(y, [1, 2, 0]).astype(np.float)
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=y)
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
plt.show()</span>
這個代碼用了很多matplotlib的函數,將不同品種花聚類以后又標定了出來,而且圖是3D的可以用鼠標從不同角度視察,效果很炫酷。展現幾個效果~
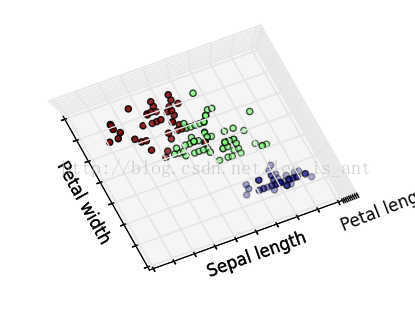
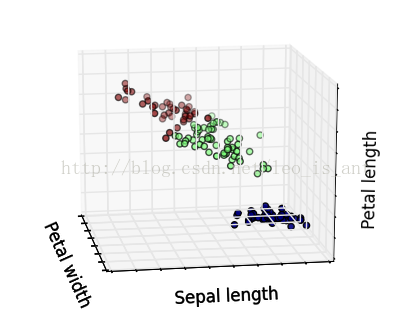
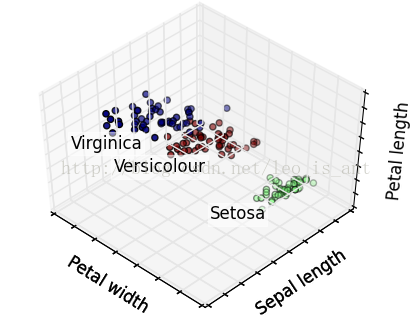
除聚類的思想以外已知了它的種別和數據,我們也能夠把它當作1個監督學習的模型來做。這樣的話研究的問題就成了1個分類問題。分類問題的模型很多LR,SVM,DT都可以解決。這里用決策樹做1個簡單的樣例。
實現之前簡單的了解1下這個模型。可以參考之前的博客
http://blog.csdn.net/leo_is_ant/article/details/43565505
首先決策樹是1種樹形結構,其中每個內部節點表示1個屬性上的測試,每個分支代表1個測試輸出,每個葉子節點代表1個種別。這類結構構建在已知各種情況產生幾率的基礎上,所以我們在構建決策樹的時候先要選擇能最大程度分離各個屬性的特點(即信息增益最大的特點),然后根據分類的情況決定是不是再用剩下的數據集和特點集構建子樹。
我們再看1下實現的代碼:
<span style="font-family:Microsoft YaHei;">from sklearn.datasets import load_iris
from sklearn.cross_validation import cross_val_score
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(random_state=0)
iris = load_iris()
model=clf.fit(iris.data, iris.target)
predicted=model.predict(iris.data)
score=cross_val_score(clf, iris.data, iris.target, cv=10)</span>
這里面,用了決策樹的分類器,去做分類。這里注意,由于是監督問題,所以fit方法用時需要 iris.target 這1個變量喲~
最后注意1下cross_val_score這1個方法,是1個交叉驗證的手段,原理是將數據分成了cv份,1份來訓練剩下的來預測,終究得到的評分能夠避免過擬合。
最后給出決策樹分類器的參數網址:
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.tree
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈




