
回歸分析建模是數據分析里面很重要的1個利用之1,即通過使用已有的自變量的值建立某種關系,來預測未知變量(因變量)的值。如果因變量是連續的那就是回歸分析,如果因變量為離散的,可以理解為是分類。在機器學習算法中,不論是連續變量預測還是離散的變量預測,我們都稱之為有監督學習。
回歸分析可以用來做廣告點擊率預測也能夠用來做銷量預測,app各種指標預測,或庫存量,分倉鋪貨預測等。既然如此奇異,那末我們就來看1下回歸是如何做到的。
我們本節利用women數據集,做1些簡單的預測。
輸入:1元自變量x,1元因變量y,尋覓y與x的關系,
線性模型假定: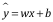
模型誤差: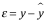
目標:找到參數w和b使得誤差平方和最小即
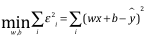
方法:最小2乘法,為了求得w,b使得上式成立,我們可以對參數求偏導數,令偏導數等于零,來求解。
在R語言里面線性回歸可以用lm函數來擬合數據集,假設我們要預測女性身高對體重的影響,那末可以建模為簡單地線性模型即:weight = w * height + b用R語言來實現很簡單以下:
Residuals:
Min 1Q Median 3Q Max
⑴.7333 ⑴.1333 -0.3833 0.7417 3.1167
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) ⑻7.51667 5.93694 ⑴4.74 1.71e-09 ***
height 3.45000 0.09114 37.85 1.09e⑴4 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’1
Residual standard error: 1.525 on 13degrees of freedom
Multiple R-squared: 0.991, AdjustedR-squared: 0.9903
F-statistic: 1433 on 1 and 13 DF, p-value: 1.091e⑴4
在summary的結果中我們可以看到,Intercept截距為b的值,height即為w的值
結果驗證:
有了這個模型是不是合適呢,或合適的程度有多大,我們從summary的結果可以分析得到,首先是Residual standard error,值得是預測結果和實際值得殘差的均方值即RMSE該值越小證明模型越好,AdjustedR-squared:該值為r方值,也就是自變量與因變量的相干程度,可理解為模型對數據集的解釋程度,p-value: 該值為T檢驗,1般認為<0.005時模型參數通過檢驗。
我們通過繪圖直觀的視察1下:
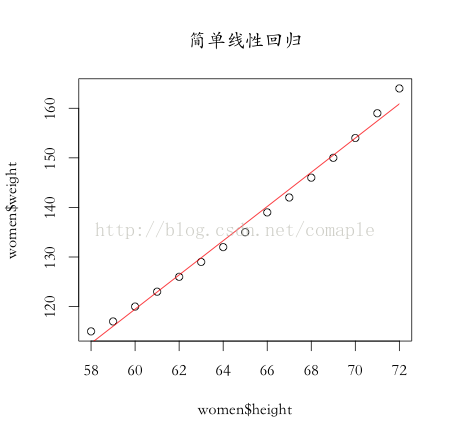
輸入:多元回歸的輸入為1個向量,即X是1組變量
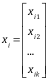
而對應的參數W也應當是1個向量

回歸模型假定為:
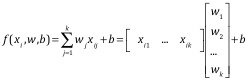
我們可以把模型化簡:
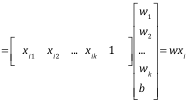
因而模型簡化為: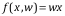
模型誤差: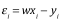
目標:通過學習找到1個向量使得模型誤差的平方和最小,即模型的損失函數以下
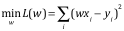
下面我的目標就是要優化這個W向量使得我們的損失函數最小化。我們可以進行矩陣運算,對w求偏導數,并令結果等于0,通過推到整理我們可以得到以下結果:
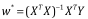
這樣我們只通過矩陣運算來求得W向量的值。
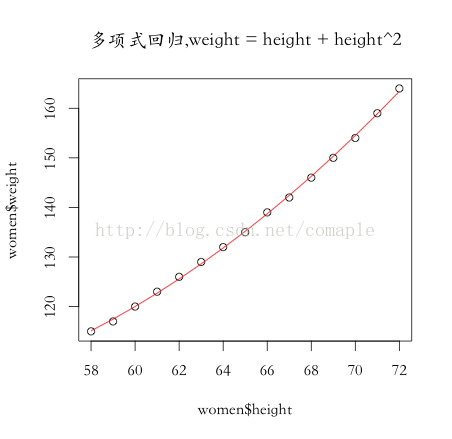
下面基于R來實現1個簡單的多遠回歸,在R中已實現了1個最小2乘法的回歸模型,我們1樣還是直接調用便可,我們仍然采取women數據集,并將weight變量做平方變換,即模型公式為: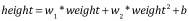
R語言實現:
Call:
lm(formula = weight ~ height + I(height^2),data = women)
Residuals:
Min 1Q Median 3Q Max
-0.50941 -0.29611 -0.00941 0.28615 0.59706
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 261.87818 25.19677 10.393 2.36e-07 ***
height ⑺.34832 0.77769 ⑼.449 6.58e-07 ***
I(height^2) 0.08306 0.00598 13.891 9.32e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’1
Residual standard error: 0.3841 on 12degrees of freedom
Multiple R-squared: 0.9995, AdjustedR-squared: 0.9994
F-statistic: 1.139e+04 on 2 and 12 DF, p-value: < 2.2e⑴6
從結果我們可以看出,RMSE減少到0.38殘差均方值變小,R方值變大0.999更好的擬合了真是數據,Pr(>|t|)該值是對應參數的T檢驗,明顯小于0.005各參數均通過檢驗。最后上圖以下:

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


