Alex 的 Hadoop 菜鳥教程: 第20課 工作流引擎 Oozie
來源:程序員人生 發(fā)布時間:2015-03-30 08:35:05 閱讀次數(shù):6419次
本文基于 Centos6.x + CDH5.x
Oozie是甚么
簡單的說Oozie是1個工作流引擎。只不過它是1個基于Hadoop的工作流引擎,在實際工作中,遇到對數(shù)據(jù)進行1連串的操作的時候很實用,不需要自己寫1些處理代碼了,只需要定義好各個action,然后把他們串在1個工作流里面就能夠自動履行了。對大數(shù)據(jù)的分析工作非常有用
安裝Oozie
Oozie分為服務(wù)端和客戶端,我現(xiàn)在選擇host1作為服務(wù)端,host2作為客戶端。
所以在host1上運行
yum install oozie
在host2上運行
yum install oozie-client
配置Oozie
配置Oozie使用的MapReduce版本,MapReduce版本有兩個1個是 MRv1 和 YARN。由于我們選擇的是YARN,而且我為了方便上手暫時不用SSL,所以切換成不帶SSL并且使用YARN
alternatives --set oozie-tomcat-conf /etc/oozie/tomcat-conf.http
$ mysql -u root -p
Enter password: ******
mysql> create database oozie;
Query OK, 1 row affected (0.03 sec)
mysql> grant all privileges on oozie.* to 'oozie'@'localhost' identified by 'oozie';
Query OK, 0 rows affected (0.03 sec)
mysql> grant all privileges on oozie.* to 'oozie'@'%' identified by 'oozie';
Query OK, 0 rows affected (0.03 sec)
編輯 oozie-site.xml 配置mysql的連接屬性
<property>
<name>oozie.service.JPAService.jdbc.driver</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.url</name>
<value>jdbc:mysql://localhost:3306/oozie</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.username</name>
<value>oozie</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.password</name>
<value>oozie</value>
</property>
把mysql的jdbc驅(qū)動做1個軟鏈到 /var/lib/oozie/
$ sudo yum install mysql-connector-java
$ ln -s /usr/share/java/mysql-connector-java.jar /var/lib/oozie/mysql-connector-java.jar
第1行,如果你已裝過 mysql-connector-java 可以跳過這步
創(chuàng)建oozie需要的表結(jié)構(gòu)
$ sudo -u oozie /usr/lib/oozie/bin/ooziedb.sh create -run
打開Web控制臺
Step1
Oozie使用的是ExtJs,所以得先下載1個ext http://archive.cloudera.com/gplextras/misc/ext⑵.2.zip
Step2
解壓開 ext⑵.2.zip 并拷貝到 /var/lib/oozie.
# unzip ext⑵.2.zip
# mv ext⑵.2 /var/lib/oozie/
在HDFS上安裝Oozie庫
為oozie分配hdfs的權(quán)限,編輯所有機器上的 /etc/hadoop/conf/core-site.xml ,增加以下配置
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>*</value>
</property>
并重啟hadoop的service(namenode 和 datanode 就好了)
拷貝Oozie的Jars到HDFS,讓DistCp, Pig, Hive, and Sqoop 可以調(diào)用
$ sudo -u hdfs hadoop fs -mkdir /user/oozie
$ sudo -u hdfs hadoop fs -chown oozie:oozie /user/oozie
$ sudo oozie-setup sharelib create -fs hdfs://mycluster/user/oozie -locallib /usr/lib/oozie/oozie-sharelib-yarn.tar.gz
這里的mycluster請自行替換成你的clusterId
啟動Oozie
$ sudo service oozie start
使用Oozie
連接Oozie的方法
連接Oozie有3個方法
用客戶端連接
由于我的client端裝在了host2上,所以在host2上運行
$ oozie admin -oozie http://host1:11000/oozie -status
System mode: NORMAL
為了方便,不用每次都輸入oozie-server所在
服務(wù)器,我們可以設(shè)置環(huán)境變量
$ export OOZIE_URL=http://host1:11000/oozie
$ oozie admin -version
Oozie server build version: 4.0.0-cdh5.0.0
用閱讀器訪問
打開閱讀器訪問 http://host1:11000/oozie
用HUE訪問
上節(jié)課我們講了HUE的使用,現(xiàn)在可以在hue里面配置上Oozie的參數(shù)。用HUE來使用Oozie。
編輯 /etc/hue/conf/hue.init 找到 oozie_url 這個屬性,修改成真實地址
[liboozie]
# The URL where the Oozie service runs on. This is required in order for
# users to submit jobs. Empty value disables the config check.
oozie_url=http://host1:11000/oozie
重啟hue服務(wù)
訪問hue中的oozie模塊
點擊 Workflow 可以看到工作流界面
Oozie的3個概念
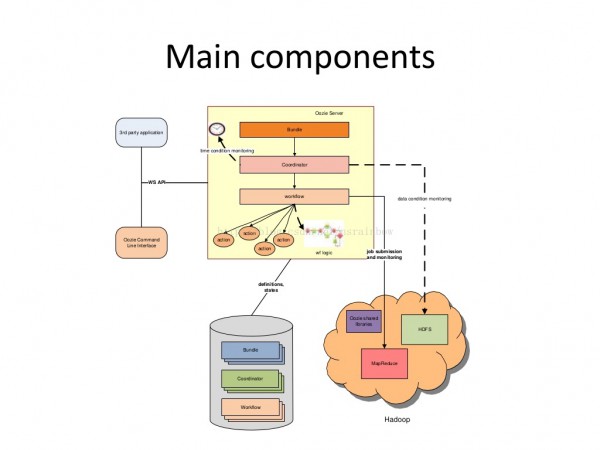
Oozie有3個主要概念
- workflow 工作流
- coordinator 多個workflow可以組成1個coordinator,可以把前幾個workflow的輸出作為后1個workflow的輸入,也能夠定義workflow的觸發(fā)條件,來做定時觸發(fā)
- bundle 是對1堆coordinator的抽象
以下這幅圖解釋了Oozie組件之間的關(guān)系
hPDL
oozie采取1種叫 hPDL的xml規(guī)范來定義工作流。
這是1個wordcount版本的hPDL的xml例子
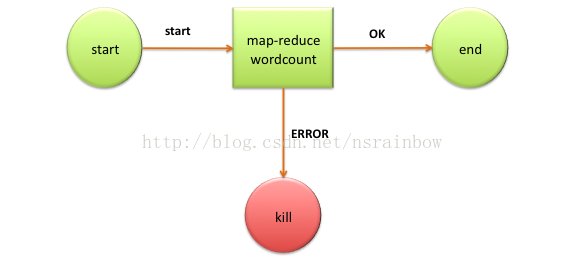
<workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.1">
<start to='wordcount'/>
<action name='wordcount'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.WordCount.Map</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.myorg.WordCount.Reduce</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to='end'/>
<error to='end'/>
</action>
<kill name='kill'>
<message>Something went wrong: ${wf:errorCode('wordcount')}</message>
</kill/>
<end name='end'/>
</workflow-app>
這個例子可以用以下這幅圖表示
1個oozie job的組成
1個oozie 的 job 1般由以下文件組成
- job.properties 記錄了job的屬性
- workflow.xml 使用hPDL 定義任務(wù)的流程和分支
- class 文件,用來履行具體的任務(wù)
任務(wù)啟動的命令1般長這模樣
$ oozie job -oozie http://localhost:11000/oozie -config examples/apps/map-reduce/job.properties -run
可以看到 任務(wù)開始是通過調(diào)用 oozie job 命令并傳入oozie
服務(wù)器地址和 job.properties 的路徑開始。job.properties 是1個任務(wù)的履行入口
做個MapReduce例子
這里使用官方提供的例子。
Step1
在 host1 上下載oozie包
wget http://apache.fayea.com/oozie/4.1.0/oozie⑷.1.0.tar.gz
解壓開,里面有1個 examples文件夾,我們將這個文件夾拷貝到別的地方,并改名為
oozie-examples 進入這個文件夾,然后修改pom.xml,在plugins里面增加1個plugin
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.5</version>
<configuration>
<skipTests>false</skipTests>
<testFailureIgnore>true</testFailureIgnore>
<forkMode>once</forkMode>
</configuration>
</plugin>
然后運行 mvn package 可以看到 target 文件夾下有 oozie-examples⑷.1.0.jar
Step2
編輯 oozie-examples/src/main/apps/map-reduce/job.properties
修改 namenode為hdfs 的namenode地址,由于我們是搭成ha模式,所以寫成 hdfs://mycluster 。修改 jobTracker為 resoucemanager 所在的地址,這邊為 host1:8032
改完后的 job.properties 長這樣
nameNode=hdfs://mycluster
jobTracker=host1:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/map-reduce
outputDir=map-reduce
這里的 user.name 就是你運行oozie的linux 用戶名,我用的是root,所以最后的路徑會變成 hdfs://mycluster/user/root/examples/apps/map-reduce
Step3
根據(jù)上面配置的路徑,我們在hdfs上先建立出 /user/root/examples/apps/map-reduce/ 目錄
hdfs dfs -mkdir -p /user/root/examples/apps/map-reduce
然后把 src/main/apps/map-reduce/workflow.xml 傳到 /user/root/examples/apps/map-reduce 下面
hdfs dfs -put oozie-examples/src/main/apps/map-reduce/workflow.xml /user/root/examples/apps/map-reduce/
在 /user/root/examples/apps/map-reduce/ 里面建立 lib 文件夾,并把 打包好的 oozie-examples⑷.1.0.jar 上傳到這個目錄下
hdfs dfs -mkdir /user/root/examples/apps/map-reduce/lib
hdfs dfs -put oozie-examples/target/oozie-examples⑷.1.0.jar /user/root/examples/apps/map-reduce/lib
在hdfs上建立 /examples 文件夾
sudo -u hdfs hdfs dfs -mkdir /examples
把examples 文件夾里面的 srcmainapps 文件夾傳到這個文件夾底下
hdfs dfs -put examples/src/main/apps /examples
建立輸出跟輸入文件夾并上傳測試數(shù)據(jù)
hdfs dfs -mkdir -p /user/root/examples/input-data/text
hdfs dfs -mkdir -p /user/root/examples/output-data
hdfs dfs -put oozie-examples/src/main/data/data.txt /user/root/examples/input-data/text
Step4
運行這個任務(wù)
oozie job -oozie http://host1:11000/oozie -config oozie-examples/src/main/apps/map-reduce/job.properties -run
任務(wù)創(chuàng)建成功后會返回1個job號比如 job: 0000017⑴50302164219871-oozie-oozi-W
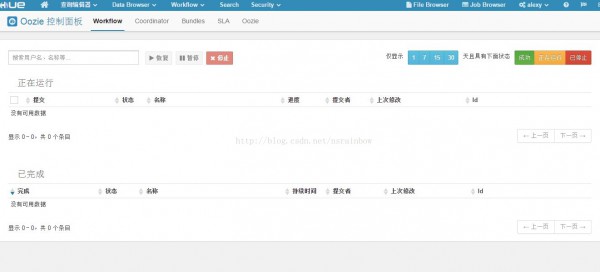
然后你可以采取之條件供的 3 個連接oozie 的方法去查詢?nèi)蝿?wù)狀態(tài),這里我采取HUE去查詢的情況,點擊最上面的 Workflow -> 儀表盤 -> Workflow
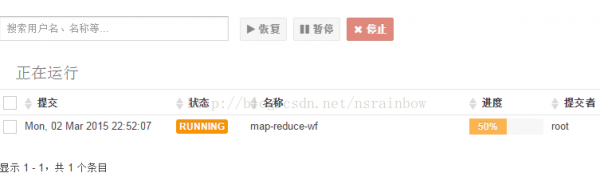
會看到有1個任務(wù)正在運行
點擊后,可以實時的看任務(wù)狀態(tài),完成后會變成SUCCESS
這時候候去看下結(jié)果 /user/root/examples/output-data/map-reduce/part-00000
0 To be or not to be, that is the question;
42 Whether 'tis nobler in the mind to suffer
84 The slings and arrows of outrageous fortune,
129 Or to take arms against a sea of troubles,
172 And by opposing, end them. To die, to sleep;
217 No more; and by a sleep to say we end
255 The heart-ache and the thousand natural shocks
302 That flesh is heir to ? 'tis a consummation
346 Devoutly to be wish'd. To die, to sleep;
387 To sleep, perchance to dream. Ay, there's the rub,
438 For in that sleep of death what dreams may come,
487 When we have shuffled off this mortal coil,
531 Must give us pause. There's the respect
571 That makes calamity of so long life,
608 For who would bear the whips and scorns of time,
657 Th'oppressor's wrong, the proud man's contumely,
706 The pangs of despised love, the law's delay,
751 The insolence of office, and the spurns
791 That patient merit of th'unworthy takes,
832 When he himself might his quietus make
871 With a bare bodkin? who would fardels bear,
915 To grunt and sweat under a weary life,
954 But that the dread of something after death,
999 The undiscovered country from whose bourn
1041 No traveller returns, puzzles the will,
1081 And makes us rather bear those ills we have
1125 Than fly to others that we know not of?
1165 Thus conscience does make cowards of us all,
1210 And thus the native hue of resolution
1248 Is sicklied o'er with the pale cast of thought,
1296 And enterprises of great pitch and moment
1338 With this regard their currents turn awry,
1381 And lose the name of action.
workflow.xml解析
我們把剛剛這個例子里面的workflow.xml打開看下
<workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
最重要的就是里面的action 節(jié)點。
中間那段action 可以有支持幾種類型的action
- Map-Reduce Action
- Pig Action
- Fs(HDFS) Action
- Java Action
- Email Action
- Shell Action
- Hive Action
- Sqoop Action
- Ssh Action
- DistCp Action
- 自定義Action
- sub-workflow (這個可以嵌套另外1個workflow.xml文件的路徑)
具體見 http://oozie.apache.org/docs/4.1.0/WorkflowFunctionalSpec.html#a3.2_Workflow_Action_Nodes
這個簡單的map-reduce 其實甚么也沒干,只是把文本1行的讀取并打印出來。接下來我要把這個例子改成我們熟習(xí)的WordCount例子
WordCount例子
Step1
先改1下我們的Mapper 和 Reducer 代碼
修改SampleMapper為
package org.apache.oozie.example;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SampleMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
然后再把Reducer修改成
package org.apache.oozie.example;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SampleReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
改好后用 mvn clean package 打包好,還是上傳到 /user/root/examples/apps/map-reduce/lib 覆蓋之前的那份jar
這邊說1點題外話,關(guān)于MapReduce的old API跟new API的區(qū)分,這個跟我們這次的教程沒關(guān)系,如果不感興趣的同學(xué)可以直接跳過下面這1段
MapReduce 的 old API 跟 new API 區(qū)分
mapreduce 分為 old api 和 new api , new api廢棄了 org.apache.hadoop.mapred 包下的 Mapper 和 Reducer,新增了org.apache.hadoop.mapreduce包,如果你手頭有用舊api寫的mp(mapreduce)任務(wù)可以通過以下幾個改動修改成新的mp寫法
- 將implements Mapper/Reducer 改成 extends Mapper/Reducer,由于new API 里 Mapper 和 Reducer不是接口,并且包的位置變成 org.apache.hadoop.mapreduce.Mapper
- OutputCollector 改成 Context
- map方法改成 map(LongWritable key, Text value, Context context) reduce 方法改成
具體見 Hadoop WordCount with new map reduce api
Step2
我們把之前的 src/main/apps/map-reduce/workflow.xml 修改1下成為這樣
<workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapred.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<property>
<name>mapreduce.inputformat.class</name>
<value>org.apache.hadoop.mapreduce.lib.input.TextInputFormat</value>
</property>
<property>
<name>mapreduce.outputformat.class</name>
<value>org.apache.hadoop.mapreduce.lib.output.TextOutputFormat</value>
</property>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapreduce.map.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapreduce.reduce.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
我把中間的action 里面的屬性替換了,我說明1下幾個重要屬性
- mapred.mapper.new-api 和 mapred.reducer.new-api 意思是是不是要使用new API,我們這邊設(shè)置為true
- mapred.output.key.class 和 mapred.output.value.class 意思是 mapper的輸出類型
- mapreduce.map.class 和 mapreduce.reduce.class 這兩處連屬性名都修改了,可能很多人會發(fā)現(xiàn)不了,之前是 mapred.mapper.class 和 mapred.reducer.class ,如果你只改了value就會出錯,說new API的屬性里面沒有這兩個屬性
然后我們把workflow.xml上傳到hdfs上
hdfs dfs -put -f oozie-examples/src/main/apps/map-reduce/workflow.xml /user/root/examples/apps/map-reduce/
Step3
我們把素材準(zhǔn)備1下,還是之前做 wordcount 用的 file0 和 file1
$ echo "Hello World Bye World" > file0
$ echo "Hello Hadoop Goodbye Hadoop" > file1
$ hdfs dfs -put file* /user/root/examples/input-data/text
順便把之前的data.txt刪掉
hdfs dfs -rm /user/root/examples/input-data/text/data.txt
Step4
我們來運行1下這個job
oozie job -oozie http://host1:11000/oozie -config oozie-examples/src/main/apps/map-reduce/job.properties -run
履行完后到 / user/ root/ examples/ output-data/ map-reduce/ part-r-00000 查看我們的結(jié)果
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
完成!
參考資料
- http://www.infoq.com/cn/articles/introductionOozie
- http://www.infoq.com/cn/articles/oozieexample
- https://github.com/yahoo/oozie/wiki/Oozie-Coord-Use-Cases
- https://oozie.apache.org/docs/3.1.3-incubating/CoordinatorFunctionalSpec.html#a2._Definitions
- http://oozie.apache.org/docs/4.1.0/DG_Examples.html
- https://github.com/jrkinley/oozie-examples
- http://codesfusion.blogspot.com/2013/10/hadoop-wordcount-with-new-map-reduce-api.html
- https://support.pivotal.io/hc/en-us/articles/203355837-How-to-run-a-Map-Reduce-jar-using-Oozie-workflow
生活不易,碼農(nóng)辛苦
如果您覺得本網(wǎng)站對您的學(xué)習(xí)有所幫助,可以手機掃描二維碼進行捐贈