
其實通過模型來預測1個user對1個item的評分,思想類似線性回歸做預測,大致以下
定義1個預測模型(數學公式),
然后肯定1個損失函數,
將已有數據作為訓練集,
不斷迭代來最小化損失函數的值,
終究肯定參數,把參數套到預測模型中做預測。
矩陣分解的預測模型是:
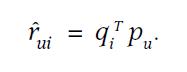
損失函數是:
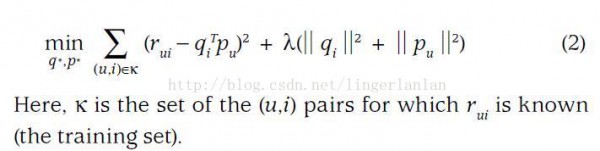
矩陣分解模型的物理意義
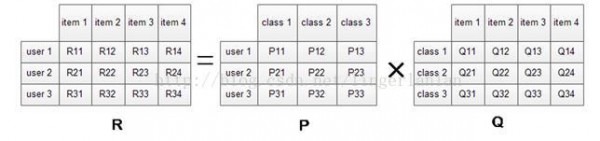
我們希望學習到1個P代表user的特點,Q代表item的特點。特點的每個維度代表1個隱性因子,比如對電影來講,這些隱性因子多是導演,演員等。固然,這些隱性因子是機器學習到的,具體是甚么含義我們不肯定。
學習到P和Q以后,我們就能夠直接P乘以Q就能夠預測所有user對item的評分了。
講完矩陣分解推薦模型,下面到als了(全稱Alternatingleast squares)。其實als就是上面損失函數最小化的1個求解方法,固然還有其他方法比如SGD等。
als論文中的損失函數是(跟上面那個略微有點不同)
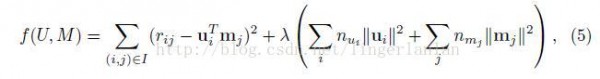
每次迭代,
固定M,逐一更新每一個user的特點u(對u求偏導,令偏導為0求解)。
固定U,逐一更新每一個item的特點m(對m求偏導,令偏導為0求解)。
論文中是這樣推導的
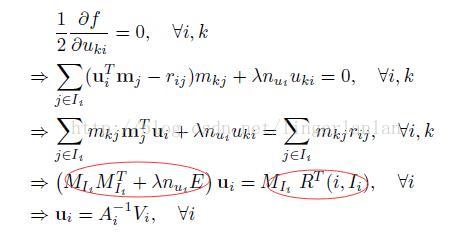
這是每次迭代求u的公式。求m的類似。
為了更清晰的理解,這里結合spark的als代碼講授。
spark源碼中實現als有3個版本,1個是LocalALS.scala(沒有用spark),1個是SparkALS.scala(用了spark做并行優化),1個是mllib中的ALS。
本來LocalALS.scala和SparkALS.scala這個兩個實現是官方為了開發者學習使用spark展現的,
mllib中的ALS可以用于實際的推薦。
但是mllib中的ALS做了很多優化,不合適初學者研究來理解als算法。
因此,下面我拿LocalALS.scala和SparkALS.scala來說解als算法。
LocalALS.scala
再結合論文中的公式
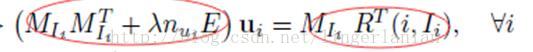
其實代碼中的XtX就是公式中左側紅圈的部份,Xty就是右側紅圈的部份。
同理,更新每一個電影的特點m類似,這里不再重復。
SparkALS.scala
SparkALS版本相對LocalALS的亮點時,做了并行優化。LocalALS中,每一個user的特點是串行更新的。而SparkALS中,是并行更新的。
參考資料:
《Large-scale Parallel Collaborative Filtering for the Netflix Prize》(als-wr原論文)
《Matrix Factorization Techniques for Recommender Systems》(矩陣分解模型的好材料)
https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/LocalALS.scala
https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/SparkALS.scala
本文作者:linger
本文鏈接:http://blog.csdn.net/lingerlanlan/article/details/44085913

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


