【CUDA并行編程之七】數組元素之和
來源:程序員人生 發布時間:2015-01-31 10:19:05 閱讀次數:3805次
現在需要求得1個數組的所有元素之和,之前感覺似乎不太可能,由于每一個線程只處理1個元素,沒法將所有元素聯系起來,但是最近學習了1段代碼可以實現,同時也對shared memory有了進1步的理解。
1、C++串行實現
串行實現的方法非常之簡單,只要將所有元素順次相加就可以夠得到相應的結果,實際上我們重視的不是結果,而是運行的效力。那末代碼以下:
array_sum.cc:
#include<iostream>
#include<stdio.h>
#include "kmeans.h"
using namespace std;
const int cnt = 100000;
int main()
{
int *a = new int[cnt];
for(int i=0;i<cnt;i++)
{
a[i] = i+1;
}
double t = wtime();
for(int i=0;i<cnt;i++)
sum += a[i];
printf("computation elapsed %.8f
",wtime()-t);
return 0;
}
wtime.cu:
#include <sys/time.h>
#include <stdio.h>
#include <stdlib.h>
double wtime(void)
{
double now_time;
struct timeval etstart;
struct timezone tzp;
if (gettimeofday(&etstart, &tzp) == ⑴)
perror("Error: calling gettimeofday() not successful.
");
now_time = ((double)etstart.tv_sec) + /* in seconds */
((double)etstart.tv_usec) / 1000000.0; /* in microseconds */
return now_time;
}
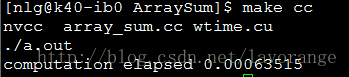
運行結果:
2、CUDA并行實現
先上代碼然后再進行解釋:
#include <iostream>
#include <stdio.h>
#include "kmeans.h"
using namespace std;
const int count = 1000;
void generate_data(int *arr)
{
for(int i=0;i<count;i++)
{
arr[i] = i+1;
}
}
int nextPowerOfTwo(int n)
{
n--;
n = n >> 1 | n;
n = n >> 2 | n;
n = n >> 4 | n;
n = n >> 8 | n;
n = n >> 16 | n;
//n = n >> 32 | n; //For 64-bits int
return ++n;
}
/*
cnt : count
cnt2 : next power of two of count
*/
__global__ static void compute_sum(int *array,int cnt , int cnt2)
{
extern __shared__ unsigned int sharedMem[];
sharedMem[threadIdx.x] = (threadIdx.x < cnt) ? array[threadIdx.x] : 0 ;
__syncthreads();
//cnt2 "must" be a power of two!
for( unsigned int s = cnt2/2 ; s > 0 ; s>>=1 )
{
if( threadIdx.x < s )
{
sharedMem[threadIdx.x] += sharedMem[threadIdx.x + s];
}
__syncthreads();
}
if(threadIdx.x == 0)
{
array[0] = sharedMem[0];
}
}
int main()
{
int *a = new int[count];
generate_data(a);
int *deviceArray;
cudaMalloc( &deviceArray,count*sizeof(int) );
cudaMemcpy( deviceArray,a,count*sizeof(int),cudaMemcpyHostToDevice );
int npt_count = nextPowerOfTwo(count);//next power of two of count
//cout<<"npt_count = "<<npt_count<<endl;
int blockSharedDataSize = npt_count * sizeof(int);
double t = wtime();
for(int i=0;i<count;i++)
{
compute_sum<<<1,count,blockSharedDataSize>>>(deviceArray,count,npt_count);
}
printf("computation elapsed %.8f
",wtime()-t);
int sum ;
cudaMemcpy( &sum,deviceArray,sizeof(int),cudaMemcpyDeviceToHost );
cout<<"sum = "<<sum<<endl;
return 0;
}
主函數:
line58:為數組a賦初值,維度為count。
line60~62:定義device變量并分配內存,將數組a的值拷貝到顯存上去。
line63:nextPowerOfTwo是非常精巧的1段代碼,它計算大于等于輸入參數n的第1個2的冪次數。至于為何這么做要到kernel函數里面才能明白。
line68:compute_sum中的"1"為block的數量,"count"為每一個block里面的線程數,"blockSharedDataSize"為同享內存的大小。
核函數compute_sum:
line35:定義shared memory變量。
line36:將threadIdx.x小于cnt的對應的sharedMem的內存區賦值為數組array中的值。
line39~47:這段代碼的功能就是將所有值求和以后放到了shareMem[0]這個位置上。這段代碼要好好體會1下,它把本來計算復雜度為O(n)的串行實現的時間效力通過并行到達了O(logn)。最后將結果保存到array[0]并拷貝回主存。
makefile:
cu:
nvcc cuda_array_sum.cu wtime.cu
./a.out
結果:

3、效力對照
我們通過修改count的值并且加大循環次數來視察變量的效力的差別。
代碼修改:


運行時間對照:
|
count
|
串行(s) |
并行(s)
|
|
1000
|
0.00627995
|
0.00345612
|
|
10000
|
0.29315591
|
0.06507015
|
|
100000
|
25.18921304
|
0.65188980
|
|
1000000
|
2507.66827798
|
5.61648989
|
|
|
|
|
哈哈,可見在數據量大的情況下效力還是相當不錯的。
Author:憶之獨秀
Email:leaguenew@qq.com
注明出處:http://blog.csdn.net/lavorange/article/details/43031419
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈




