
前幾章將有特點(diǎn)的公有云計(jì)算平臺(tái)都介紹了1下,這里費(fèi)下嘴,不是說(shuō)只有這些云平臺(tái),實(shí)際上有很多,到現(xiàn)在Bat、360等都得云計(jì)算平臺(tái)有觸及,方向、功能大體相似,我們經(jīng)常使用的網(wǎng)盤算是其中之1。通過(guò)前面云計(jì)算的介紹,云計(jì)算相干的虛擬化、并行計(jì)算、主機(jī)管理等技術(shù),我們也積累很多東西,現(xiàn)在就開始利用到實(shí)踐中。
筆者認(rèn)為可以依照數(shù)據(jù)的使用方式,將利用分為3種:以計(jì)算為中心的利用(統(tǒng)計(jì)計(jì)算,摹擬計(jì)算,圖象、信息管理系統(tǒng),這類單個(gè)計(jì)算所需數(shù)據(jù)量小,數(shù)據(jù)傳輸代價(jià)小,能夠?qū)崟r(shí)處理),以數(shù)據(jù)為中心的利用(互聯(lián)網(wǎng)搜索公司、數(shù)據(jù)發(fā)掘、人口統(tǒng)計(jì)、日志分析,輸入數(shù)據(jù)量較大,傳輸代價(jià)高,需要散布式并行處理),需要統(tǒng)籌數(shù)據(jù)與計(jì)算的利用(采取分而治之的方法,根據(jù)不同的功能模塊采取不同的技術(shù))。
對(duì)這么利用,我們有不同的架構(gòu)選擇,以計(jì)算為中心的利用架構(gòu)選擇,除本機(jī)采取多線程編程外,通常可以把計(jì)算所需的數(shù)據(jù)分發(fā)到多臺(tái)計(jì)算機(jī)上同時(shí)計(jì)算,1般這樣的利用計(jì)算所需數(shù)據(jù)量較小,數(shù)據(jù)傳輸花費(fèi)時(shí)間少,側(cè)重于并行計(jì)算,而沒(méi)必要關(guān)注數(shù)據(jù)存儲(chǔ)問(wèn)題,前端因特網(wǎng)利用可使用負(fù)載均衡器,后臺(tái)的大計(jì)算量可以選擇Platform Symphony等軟件來(lái)解決。
以數(shù)據(jù)為中心的利用架構(gòu)與以計(jì)算為中心的最大區(qū)分就是計(jì)算所需的數(shù)據(jù)”量“,當(dāng)需要傳輸?shù)臄?shù)據(jù)量很大時(shí),數(shù)據(jù)傳輸?shù)臅r(shí)間遠(yuǎn)遠(yuǎn)大于處理的時(shí)間,單純提高速度就沒(méi)有了實(shí)際用途,因而,Google提出了MapReduce計(jì)算框架,他將數(shù)據(jù)最初產(chǎn)生時(shí)就散布寄存在散布式文件系統(tǒng)中,每個(gè)數(shù)據(jù)存儲(chǔ)節(jié)點(diǎn)同時(shí)也是計(jì)算節(jié)點(diǎn),大大節(jié)省了數(shù)據(jù)傳輸時(shí)間,提高了計(jì)算速度,算是目前較為有效的離線處理方案,后來(lái)就有了實(shí)時(shí)處理數(shù)據(jù)框架Spark,所以以數(shù)據(jù)為中心的利用可以采取MapReduce架構(gòu)(比如hadoop實(shí)現(xiàn))構(gòu)建利用計(jì)算環(huán)境。
需要統(tǒng)籌數(shù)據(jù)和計(jì)算的利用架構(gòu)選擇,比如Google的搜索頁(yè)面,它采取前端頁(yè)面使用負(fù)載均衡器提高用戶的響應(yīng)速度,后臺(tái)大數(shù)據(jù)量計(jì)算采取MapReduce架構(gòu)解決,總之,就是分而治之,轉(zhuǎn)化為以數(shù)據(jù)和計(jì)算為中心。
其實(shí),MapReduce框架其實(shí)不能解決所有的問(wèn)題,大致有這么3點(diǎn):1、目前很多利用都是集中式存儲(chǔ)的,出于各種斟酌,多數(shù)用戶不會(huì)使用HDFS這類散布式文件系統(tǒng),那樣就使用不了MapReduce框架;2、現(xiàn)有的MapReduce實(shí)現(xiàn),數(shù)據(jù)都是分散式存儲(chǔ)的,這樣必將給數(shù)據(jù)的傳輸和同步帶來(lái)新的問(wèn)題;3、MapReduce計(jì)算節(jié)點(diǎn)是和數(shù)據(jù)相干聯(lián)的,需要將數(shù)據(jù)分發(fā)到所有的工作節(jié)點(diǎn)上,而實(shí)際情況是,1般數(shù)據(jù)只存在全部集群的部份節(jié)點(diǎn)上,這樣有時(shí)就不能充分的利用計(jì)算資源。
除MapReduce框架的問(wèn)題,現(xiàn)有的云計(jì)算技術(shù)還存在很多問(wèn)題。由于我們說(shuō)了那末多的云計(jì)算產(chǎn)品,他們都是針對(duì)某1方面問(wèn)題而產(chǎn)生的解決方案,當(dāng)整合時(shí),各種問(wèn)題也就隨機(jī)產(chǎn)生:1、NoSQL數(shù)據(jù)庫(kù)API不兼容,不同廠商提供的數(shù)據(jù)庫(kù)操作方式不1樣,一樣的插入功能不盡相同,雖然他們?cè)谠O(shè)計(jì)上相似。這類不同會(huì)致使當(dāng)選擇了某種特殊NoSQL數(shù)據(jù)庫(kù)開發(fā)利用后,很難將利用遷移到其他云計(jì)算平臺(tái)上;2、各公共服務(wù)提供商所提供的服務(wù)不同,具體的看下圖:
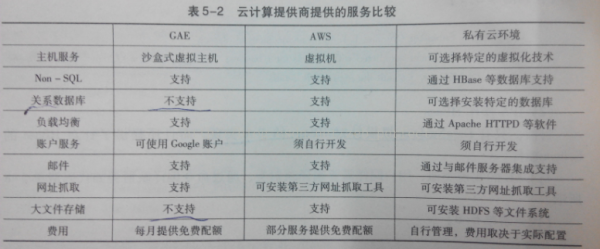
針對(duì)上面提到的問(wèn)題現(xiàn)狀,我們也有相應(yīng)的解決辦法。我們知道在傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)中,也遇到過(guò)一樣的問(wèn)題,當(dāng)時(shí)是創(chuàng)建了SQL標(biāo)準(zhǔn)數(shù)據(jù)庫(kù)訪問(wèn)語(yǔ)言,開發(fā)了hibernate,DataNucleus等輕量級(jí)的ORM開發(fā)組件,一樣,對(duì)新興NoSQl數(shù)據(jù)庫(kù),針對(duì)java語(yǔ)言,幾近所有的NoSQL數(shù)據(jù)庫(kù)都支持JPA標(biāo)準(zhǔn),注意這是個(gè)標(biāo)準(zhǔn)。
JPA(Java Persistence API)實(shí)現(xiàn)了存儲(chǔ)對(duì)象向不同數(shù)據(jù)庫(kù)存儲(chǔ)的相互轉(zhuǎn)化,整體思想和現(xiàn)有的Hibernate、DataNucleus等ORM框架大體1致,總的來(lái)講,JPA包括以下兩方面技術(shù):1是ORM對(duì)象關(guān)系映照,ORM簡(jiǎn)而言之就是將java類中字段、名稱和數(shù)據(jù)庫(kù)的列名、表名關(guān)聯(lián)在1起,JPA支持XMl和java Annotation(注解式編程)兩種元數(shù)據(jù)的情勢(shì);2是統(tǒng)1標(biāo)準(zhǔn)的數(shù)據(jù)庫(kù)編程接口,JPA提供統(tǒng)1的數(shù)據(jù)庫(kù)編程接口標(biāo)準(zhǔn)來(lái)操作實(shí)體對(duì)象,履行查詢,插入,刪除,更新等操作,以筆者經(jīng)驗(yàn),JPA能很好解決90%的數(shù)據(jù)庫(kù)操作,對(duì)個(gè)別的大數(shù)據(jù)量、特定的操作需要開發(fā)人員自己完成。具體JPA的實(shí)現(xiàn)操作我會(huì)專門1文來(lái)介紹。
最后就是實(shí)戰(zhàn)基于云計(jì)算平臺(tái)的文件同享系統(tǒng)需求分析,請(qǐng)看下回分解。說(shuō)明1下,基于云計(jì)算平臺(tái)的文件同享系統(tǒng)有很多知識(shí)點(diǎn)我都沒(méi)有學(xué)過(guò),所以接下來(lái)的時(shí)間我會(huì)先逐一補(bǔ)充這個(gè)項(xiàng)目所需要的1些知識(shí)點(diǎn),比如HBase、JPA的使用,簡(jiǎn)單工具類的介紹,經(jīng)常使用模式(單態(tài)等)的學(xué)習(xí),還有Google,Amazon平臺(tái)的搭建等。待補(bǔ)充完再詳細(xì)學(xué)習(xí)這個(gè)項(xiàng)目。

上一篇 如何在三個(gè)月內(nèi)獲得三年的工作經(jīng)驗(yàn)
下一篇 java.lang.ClassCastException:java.math.BigDecimal cannot be cast to java.lang.St
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


