
在Hadoop⑵.4之前,Yarn中的ResourceManager也是單點(diǎn)故障中的,就像Hadoop⑴.x中的NameNode,由于Hadoop⑵.X已支持NameNode的HA(高可用性),那末自然也要在hadoop的某個(gè)版本中實(shí)現(xiàn)ResourceManager的HA,否則又會(huì)招致1些事后諸葛亮的詬病。本文將介紹RM的高可用性,并詳細(xì)學(xué)習(xí)如何配置和使用該特性。就像NameNode的HA1樣,ResourceManager的HA也是通過冗余的Active/Standby ResourceManagers消除單點(diǎn)故障所存在的問題。
RM的HA架構(gòu)以下(引自官方圖片),該圖所展現(xiàn)的架構(gòu)與NameNode有很多類似的地方,比如支持自動(dòng)或手動(dòng)的故障轉(zhuǎn)移,使用ZooKeeper保存Active RM的狀態(tài)等。
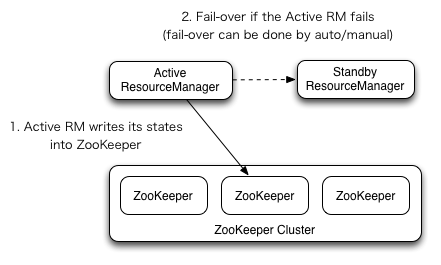
ResourceManager的HA是通過Active/Standby架構(gòu)實(shí)現(xiàn)的,在任什么時(shí)候間點(diǎn)只有1個(gè)RM處于active狀態(tài),而剩余的RM(1個(gè)或多個(gè))則處于standby狀態(tài),時(shí)刻準(zhǔn)備著接收active的工作。可以通過在CLI輸入命令或在自動(dòng)故障轉(zhuǎn)移啟動(dòng)的條件下通過集成的故障轉(zhuǎn)移控制器實(shí)現(xiàn)standby到active的轉(zhuǎn)換,也就是手動(dòng)故障轉(zhuǎn)移和自動(dòng)故障轉(zhuǎn)移。
在沒啟用自動(dòng)故障轉(zhuǎn)移的情況下,管理員必須手動(dòng)地將處于standby狀態(tài)的RMs之1轉(zhuǎn)換為active狀態(tài)。手動(dòng)故障轉(zhuǎn)移必須首先將本來處于active的RM轉(zhuǎn)換為standby狀態(tài),然后再將1個(gè)standby RM轉(zhuǎn)換為active,具體的命令為:yarn rmadmin。在自動(dòng)故障轉(zhuǎn)移方面,RM與NameNode略有不同,RM不需要運(yùn)行單獨(dú)的守護(hù)進(jìn)程ZKFC,這是由于RM有內(nèi)置的基于ZooKeeper的ActiveStandbyElector類用于在active RM宕機(jī)或無響應(yīng)時(shí)自動(dòng)選擇哪一個(gè)standbyRM將做為active RM,由于該類實(shí)現(xiàn)了ZKFC的功能。
當(dāng)存在多個(gè)RMs時(shí),需要在yarn-site.xml中羅列所有RMs,這是由于客戶端、ApplicationMasters (AMs) 和NodeManagers (NMs)以循環(huán)的方式嘗試連接RM直到連接上active RM。當(dāng)active RM不可用時(shí),再依照循環(huán)的方式嘗試連接RMs,直到遇上新的active RM。默許的嘗試邏輯由org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider實(shí)現(xiàn),可以通過實(shí)現(xiàn)org.apache.hadoop.yarn.client.RMFailoverProxyProvider接口和設(shè)置yarn.client.failover-proxy-provider的值為新類以覆蓋默許邏輯。
如果也啟用了RM的重啟特性,正在變成active狀態(tài)的RM能夠加載RM的內(nèi)部狀態(tài)和盡量多的繼續(xù)先前active RM遺留的操作。將為每一個(gè)之條件交到RM的利用程序提交新的嘗試,利用程序可以周期性地進(jìn)行檢查點(diǎn)以免丟失任何工作。狀態(tài)存儲(chǔ)必須對Active/Standby RMs都是可見的,正如之前已了解的,目條件供了兩個(gè)狀態(tài)存儲(chǔ):FileSystemRMStateStore和ZKRMStateStore,建議在RM HA集群中使用后者做為狀態(tài)存儲(chǔ)。
正如Hadoop大部份特性都可以通過配置參數(shù)進(jìn)行設(shè)置1樣,RM的HA也能夠通過下表中的參數(shù)進(jìn)行設(shè)置(更詳細(xì)的信息可以參考yarn-default.xml):
參數(shù) | 描寫 |
yarn.resourcemanager.zk-address | ZooKeeper服務(wù)器的地址(主機(jī):端口號),既用于狀態(tài)存儲(chǔ)也用于內(nèi)嵌的leader-election。 |
yarn.resourcemanager.ha.enabled | 是不是啟用RM HA,默許為false(不啟用)。 |
yarn.resourcemanager.ha.rm-ids | RMs的邏輯id列表,用逗號分隔,如:rm1,rm2 |
yarn.resourcemanager.hostname.rm-id | 每一個(gè)rm-id的主機(jī)名,rm-id的值包括在上面的參數(shù)值中。 |
yarn.resourcemanager.ha.id | 可選項(xiàng),用于標(biāo)識(shí)RM。如果設(shè)置了,管理員需要確保所有的RMs在配置中都有自己的ID。 |
yarn.resourcemanager.ha.automatic-failover.enabled | 是不是啟用自動(dòng)故障轉(zhuǎn)移。默許情況下,在啟用HA時(shí),啟用自動(dòng)故障轉(zhuǎn)移。 |
yarn.resourcemanager.ha.automatic-failover.embedded | 啟用內(nèi)置的自動(dòng)故障轉(zhuǎn)移。默許情況下,在啟用HA時(shí),啟用內(nèi)置的自動(dòng)故障轉(zhuǎn)移。 |
yarn.resourcemanager.cluster-id | 集群的Id,elector使用該值確保RM不會(huì)做為其它集群的active。 |
yarn.client.failover-proxy-provider | Clients, AMs和NMs使用該類故障轉(zhuǎn)移到active RM。 |
yarn.client.failover-max-attempts | FailoverProxyProvider嘗試故障轉(zhuǎn)移的最大次數(shù)。 |
yarn.client.failover-sleep-max-ms | 故障轉(zhuǎn)移間的最大休眠時(shí)間(單位:毫秒)。 |
yarn.client.failover-retries | 每一個(gè)嘗試連接到RM的重試次數(shù)。 |
yarn.client.failover-retries-on-socket-timeouts | 在socket超時(shí)時(shí),每一個(gè)嘗試連接到RM的重試次數(shù)。 |
下面是RM故障轉(zhuǎn)移的簡單配置示例,在該示例中啟用了HA,那末也就啟用了自動(dòng)故障轉(zhuǎn)移。
正如上面提到的,hadoop也為管理員提供了CLI的方式管理RM HA,但在沒有啟用HA的情況下,下面的命令是不可用的:
假定已啟用了HA,那末就能夠通過CLI的方式查看RM的狀態(tài)和手動(dòng)進(jìn)行故障轉(zhuǎn)移,假定yarn.resourcemanager.ha.rm-ids的值為rm1和rm2:
手動(dòng)故障轉(zhuǎn)移必須在自動(dòng)故障轉(zhuǎn)移禁用的條件下履行,否則會(huì)出現(xiàn)split-brain的情形或其它不正確的狀態(tài),手動(dòng)故障轉(zhuǎn)移的命令為:

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


