
函數是基本的代碼塊,用于履行1個任務,是構成代碼履行的邏輯結構。
在Go語言中,函數的基本組成為:關鍵字func、函數名、參數列表、返回值、函數體和返回語句。
函數其實在之前已見過了,第1次履行hello world程序的main()其實就是1個函數,而且是1個比較特殊的函數。每一個go程序都是從名為main的package包的main()函數開始履行包的概念不是這里的重點,以后做單獨說明。同時main()函數是無參數,無返回值的。
Go函數的完成定義以下:
func function_name( [parameter list] ) [return_types] {
函數體
}定義解析:
從Go的函數定義可以看出,Go的返回值是放在函數名和參數后面的,這點和C及Java的差別還是很多大的。
Go的函數調用只要通過函數名然后向函數傳遞參數,函數就會履行并返回值回來。就像之前調用Println()輸出信息1樣。
這里提1點,如果函數和調用不在同1個包(package)內,需要先通過import關鍵字將包引入–import “fmt”。函數Println()就屬于包fmt。
這里可能注意到Println()函數命名是首字母是大寫的。在Go語言中函數名字的大小寫不單單是風格,更直接體現了該函數的可見性。這和其他語言對函數或方法的命名規定可能有很大不同,像Java就推薦是駝峰的寫法,C也不建議函數名首字母是大寫。但是在Go中,如果首字母不大寫,你可能會遇到稀里糊涂的編譯毛病, 比如你明明導入了對應的包,Go編譯器還是會告知你沒法找到這個函數。
因此在Go中,需要記住1個規則:
小寫字母開頭的函數只在本包內可見,大寫字母開頭的函數才能被其他包使用。
同時這個規則也適用于變量的可見性,即首字母大寫的變量才是全局的。
package main
import "fmt"
/* 函數返回兩個數的較大值 */
func max(num1 int, num2 int) int {
/* 定義局部變量 */
var result int
if num1 > num2 {
result = num1
} else {
result = num2
}
return result
}
func main() {
var a int = 100
var b int = 200
var ret int
/* 調用函數并返回較大值 */
ret = max(a, b)
fmt.Printf("最大值是 : %d\n", ret)
}
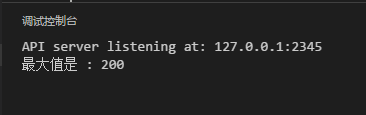
上面定義了1個函數max(),用于比較兩個數,并返回其中較大的1個。終究通過main() 函數中調用 max()函數履行。
這里關于函數的參數列表有1個簡便寫法,當連續兩個或多個函數的已命名形參類型相同時,除最后1個類型之外,其它都可以省略。
就像上面的func max(num1 int, num2 int) int {}定義,可以簡寫成
func max(num1 , num2 int) int {}前面定義函數時說過,Go的函數支持多返回值,這與C、C++和Java等開發語言極大不同。這個特性能夠使我們寫出比其他語言更優雅、更簡潔的代碼,比如File.Read()函 數就能夠同時返回讀取的字節數和毛病信息。如果讀取文件成功,則返回值中的n為讀取的字節 數,err為nil,否則err為具體的出錯信息:
func (file *File) Read(b []byte) (n int, err Error) 1個簡單的例子以下:
package main
import "fmt"
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b := swap("hello", "world")
fmt.Println(a, b)
}
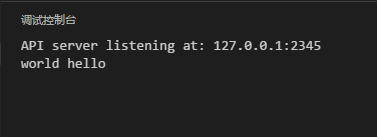
上面實現了簡單的字符串交換功能,代碼實現上10分的簡潔,由于支持多返回值,所以不需要想Java需要構建1個可以保存多個值得數據結構。
而且可以發現,對返回值如果是同1類型,可以不定義變量名稱,雖然代碼看上去是簡潔了很多,但是命名后的返回值可讓代碼更清晰,可讀性更強。
如果調用方調用了1個具有多返回值的方法,但是卻不想關心其中的某個返回值,可以簡單 地用1個下劃線“_”來跳過這個返回值。就像上面的例子,如果我們只關注第1個返回值則可以寫成:
a, _ := swap("hello", "world")若值關注第2返回值則可以寫成:
_, b := swap("hello", "world")函數定義時指出,函數定義時有參數,該變量可稱為函數的形參。形參就像定義在函數體內的局部變量。
但當調用函數,傳遞過來的變量就是函數的實參,函數可以通過兩種方式來傳遞參數:
在默許情況下,Go 語言使用的是值傳遞,即在調用進程中不會影響到實際參數。
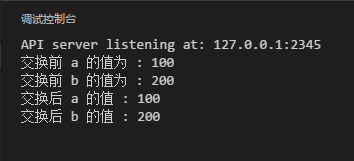
Go中int類型保存的的是1個數字類型,下面定義1個交換函數swap(),用于交換兩個參數的值。
package main
import "fmt"
func main() {
var a int = 100
var b int = 200
fmt.Printf("交換前 a 的值為 : %d\n", a)
fmt.Printf("交換前 b 的值為 : %d\n", b)
/* 通過調用函數來交換值 */
swap(a, b)
fmt.Printf("交換后 a 的值 : %d\n", a)
fmt.Printf("交換后 b 的值 : %d\n", b)
}
/* 定義相互交換值的函數 */
func swap(x, y int) int {
var temp int
temp = x /* 保存 x 的值 */
x = y /* 將 y 值賦給 x */
y = temp /* 將 temp 值賦給 y*/
return temp
}
通過前面的介紹可以知道,Go的指針類型是對變量地址的援用。
將上面的swap()做些修改,參數接受兩個指針類型,然后做交換。
package main
import "fmt"
func main() {
var a int = 100
var b int = 200
fmt.Printf("交換前 a 的值為 : %d\n", a)
fmt.Printf("交換前 b 的值為 : %d\n", b)
/* 調用 swap() 函數
* &a 指向 a 指針,a 變量的地址
* &b 指向 b 指針,b 變量的地址
*/
swap(&a, &b)
fmt.Printf("交換后 a 的值 : %d\n", a)
fmt.Printf("交換后 b 的值 : %d\n", b)
}
/* 定義相互交換值的函數 */
func swap(x, y *int) {
var temp int
temp = *x /* 保存 x 的值 */
*x = *y /* 將 y 值賦給 x */
*y = temp /* 將 temp 值賦給 y*/
}
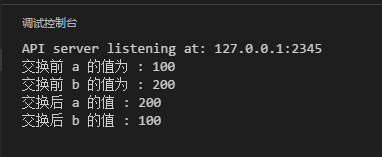
可以發現,終究傳進來的參數指在履行交換函數swap()后也被修改了,這是由于參數終究指向的都是地址的援用,所有援用被修改了,值也就相應的變了。
顧名思義,不定參數就是函數的參數不是固定的。這個在C和Java里都有。在之前的代碼中,包fmt下面的 fmt.Println()函數也是參數不定的。
先看1個函數的定義:
func myfunc(args ...int) {
}可以看出,上面的定義和之前的函數定義最大的不同就是,他的參數是以“…type”的方式定義的,這和Java的語法有些類似,也是用”…”實現。需要說明的是“…type”在Go中只能作為參數的情勢出現,而且只能作為函數的最后1個參數。
從內部實現機理上來講,類型“…type“本質上是1個數組切片,也就是[]type,這點可以從下面的1個小程序驗證1下。
package main
import "fmt"
func main() {
var a int = 100
var b int = 200
myfunc(a, b)
}
func myfunc(args ...int) {
fmt.Println(args)
for _, arg := range args {
fmt.Println(arg)
}
}
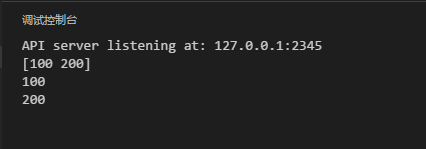
從上面的結果可以看出,類型“…type“本質上是1個數組切片,也就是[]type,所以參數args可以用for循環來取得每一個傳入的參數。
這是Go的1 個語法糖(syntactic sugar),即這類語法對語言的功能并沒有影響,但是更方便程序員使用。通常來講,使用語法糖能夠增加程序的可讀性,從而減少程序出錯的機會。
一樣是上面的myfunc(args …int)函數為例,在參數賦值時可以不用用1個1個的賦值,可以直接傳遞1個數組或切片,特別注意的是在參數后加上“…”便可。
package main
import "fmt"
func main() {
arr := []int{100, 200, 300}
myfunc(arr...)
myfunc(arr[:2]...)
}
func myfunc(args ...int) {
fmt.Println(args)
for _, arg := range args {
fmt.Println(arg)
}
}
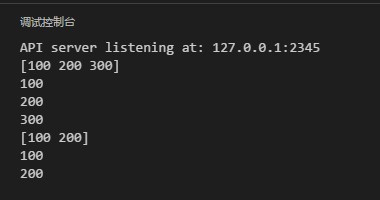
上面的例子在定義不定參數時,都有1個要求,參數的類型是1致的。那末如果函數的參數類型不1致,如何使用不定參數方式來定義。在Go中,要實現這個需求需要引入1個新的類型–interface{}。看名字可以看出,這類類型實際上就是接口。關于Go的接口這里只做引出。
看1下之前經常使用的Printf函數的定義,位置在Go的src目錄下的print.go文件中。
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}其實用interface{}傳遞任意類型數據是Go語言的慣例用法,而且interface{}是類型安全的。
看下面的例子:
package main
import (
"fmt"
"reflect"
)
func main() {
arr := []int{100, 200, 300}
myfunc(100, "abc", arr)
}
func myfunc(args ...interface{}) {
fmt.Println(args)
for _, arg := range args {
fmt.Println(arg)
fmt.Println(reflect.TypeOf(arg))
fmt.Println("=======")
}
}
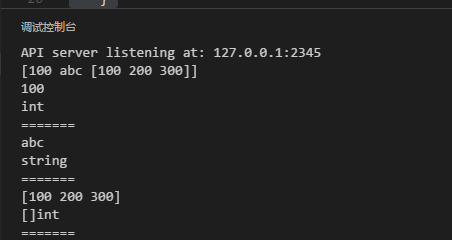
匿名函數是指不需要定義函數名的1種函數實現方式。1958年LISP首先采取匿名函數。
在Go里面,函數可以像普通變量1樣被傳遞或使用,Go語言支持隨時在代碼里定義匿名函數。
匿名函數由1個不帶函數名的函數聲明和函數體組成。匿名函數的優越性在于可以直接使用函數內的變量,沒必要申明。
直接看1個例子:
package main
import (
"fmt"
"math"
)
func main() {
getSqrt := func(a float64) float64 {
return math.Sqrt(a)
}
fmt.Println(getSqrt(4))
}
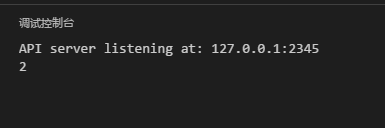
上面先定義了1個名為getSqrt 的變量,初始化該變量時和之前的變量初始化有些不同,使用了func,func是定義函數的,可是這個函數和上面說的函數最大不同就是沒有函數名,也就是匿名函數。這里將1個函數當作1個變量1樣的操作。
閉包的應當都聽過,但到底甚么是閉包呢?
閉包是由函數及其相干援用環境組合而成的實體(即:閉包=函數+援用環境)。
“官方”的解釋是:所謂“閉包”,指的是1個具有許多變量和綁定了這些變量的環境的表達式(通常是1個函數),因此這些變量也是該表達式的1部份。
維基百科講,閉包(Closure),是援用了自由變量的函數。這個被援用的自由變量將和這個函數1同存在,即便已離開了創造它的環境也不例外。所以,有另外一種說法認為閉包是由函數和與其相干的援用環境組合而成的實體。閉包在運行時可以有多個實例,不同的援用環境和相同的函數組合可以產生不同的實例。
看著上面的描寫,會發現閉包和匿名函數仿佛有些像。可是可能還是有些云里霧里的。由于跳過閉包的創建進程直接理解閉包的定義是非常困難的。目前在JavaScript、Go、PHP、Scala、Scheme、Common Lisp、Smalltalk、Groovy、Ruby、 Python、Lua、objective c、swift 和Java8以上等語言中都能找到對閉包不同程度的支持。通過支持閉包的語法可以發現1個特點,他們都有垃圾回收(GC)機制。
JavaScript應當是普及度比較高的編程語言了,通過這個來舉例應當好理解寫。看下面的代碼,只要關注script里方法的定義和調用就能夠了。
<!DOCTYPE html>
<html lang="zh">
<head>
<title></title>
</head>
<body>
</body>
</html>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.2.6/jquery.min.js" type="text/javascript"></script>
<script>
function a(){
var i=0;
function b(){
console.log(++i);
document.write("<h1>"+i+"</h1>");
}
return b;
}
$(function(){
var c=a();
c();
c();
c();
//a(); //不會有信息輸出
document.write("<h1>=============</h1>");
var c2=a();
c2();
c2();
});
</script>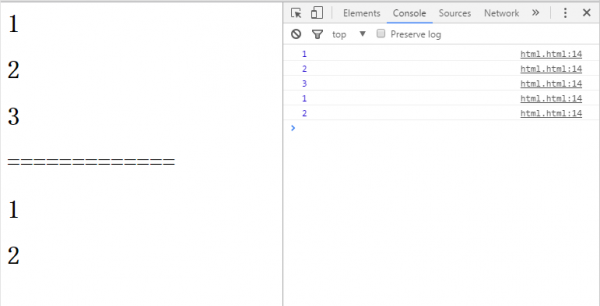
這段代碼有兩個特點:
這樣在履行完var c=a()后,變量c實際上是指向了函數b(),再履行函數c()后就會顯示i的值,第1次為1,第2次為2,第3次為3,以此類推。
其實,這段代碼就創建了1個閉包。由于函數a()外的變量c援用了函數a()內的函數b(),就是說:
當函數a()的內部函數b()被函數a()外的1個變量援用的時候,就創建了1個閉包。
在上面的例子中,由于閉包的存在使得函數a()返回后,a中的i始終存在,這樣每次履行c(),i都是自加1后的值。
從上面可以看出閉包的作用就是在a()履行完并返回后,閉包使得Javascript的垃圾回收機制GC不會收回a()所占用的資源,由于a()的內部函數b()的履行需要依賴a()中的變量i。
在給定函數被屢次調用的進程中,這些私有變量能夠保持其持久性。變量的作用域僅限于包括它們的函數,因此沒法從其它程序代碼部份進行訪問。不過,變量的生存期是可以很長,在1次函數調用期間所創建所生成的值在下次函數調用時依然存在。正由于這1特點,閉包可以用來完成信息隱藏,并進而利用于需要狀態表達的某些編程范型中。
下面來想象另外一種情況,如果a()返回的不是函數b(),情況就完全不同了。由于a()履行完后,b()沒有被返回給a()的外界,只是被a()所援用,而此時a()也只會被b()引 用,因此函數a()和b()相互援用但又不被外界打擾(被外界援用),函數a和b就會被GC回收。所以直接調用a();是頁面并沒有信息輸出。
下面來講閉包的另外一要素援用環境。c()跟c2()援用的是不同的環境,在調用i++時修改的不是同1個i,因此兩次的輸出都是1。函數a()每進入1次,就構成了1個新的環境,對應的閉包中,函數都是同1個函數,環境卻是援用不同的環境。這和c()和c()的調用順序都是無關的。
以上就是對閉包作用的非常直白的描寫,不專業也不嚴謹,但大概意思就是這樣,理解閉包需要按部就班的進程。
Go語言是支持閉包的,這里只是簡單地講1下在Go語言中閉包是如何實現的。
下面我來將之前的JavaScript的閉包例子用Go來實現。
package main
import (
"fmt"
)
func a() func() int {
i := 0
b := func() int {
i++
fmt.Println(i)
return i
}
return b
}
func main() {
c := a()
c()
c()
c()
//a() //不會輸出i
}
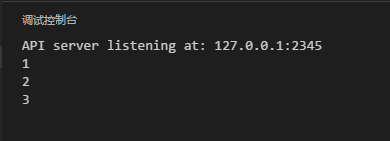
可以發現,輸出和之前的JavaScript的代碼是1致的。具體的緣由和上面的也是1樣的,這里就不在贅述了。
這頁說明Go語言是支持閉包的,至于具體是如何支持的目前就先做討論了。
關于閉包這里也只講到了基本的概念,至于更深入的東西我目前能力有限只能靠以后漸漸摸索。就像上面講到的,理解閉包需要按部就班的進程。

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


