
Python 2.7
Pycharm 5.0.3
Geopy 1.11
圖形展現 地圖無憂-網頁版
你可能需要知道
1.機器學習之K-means算法(Python描寫)基礎
2.經緯度地址轉換的方法集合(Python描寫)
3.想要知道怎樣實現的可能還要python等相干知識
4.看官隨便
這次利害了,我爬出了哈爾濱市TOP285家好吃的店,包括燒烤的TOP,餃子的TOP,醬骨的TOP等等等等,在地圖上顯示,計劃熱門,再用聚類算法計算下能不能找出吃貨最好的住宿點,能夠距離吃的各個地方行程最近,吃貨們,準備好了嗎?
可視化美食熱門,計劃各類美食聚集點,計劃行程。
首先,我不對這次排行的可信度負責,我只是直接百度的top餐廳,里面的水份大家自己權衡,甩鍋給哈爾濱美食最新榜出爐,史上最強300家美食滿足你各種挑剔!
大概是這樣的
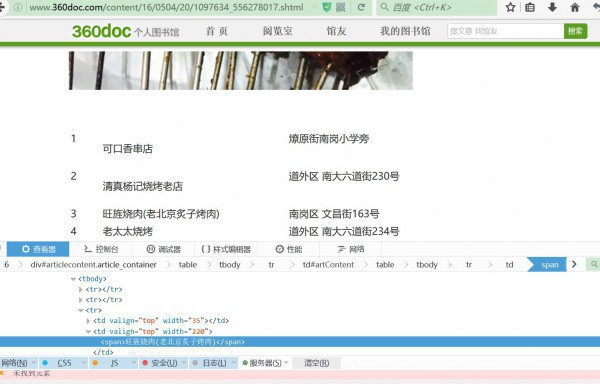
怎樣爬我就不重復演示了,這里可以了解動態和靜態爬的各種方法可以參考這里,有靜態和動態的例子,這次我用靜態爬發現被攔截了,mdzz,然后我就直接上selenium+Firefox(這里有1堆用Selenium的不累述了),至于為何不上PhantomJS,我這里說下,有時候PhantomJS爬的內容沒有Firefox全,也許有人跳出來講,你個sb,他兩是1樣的啊,而且PhantomJS更加省內存,呵呵,你自己去試試就知道了,我不止1次在爬動態的時候PhantomJS遇到問題而Firefox沒有問題的(比如這個偽解決Selenium中調用PhantomJS沒法摹擬點擊(click)操作 ,連xpath都1樣,就換了個無頭,就不行了,我也有看到Stack Overflow上遇到一樣問題的,多是我手法不夠吧,也許是我真的理解錯了,到時候我自來認錯。
剛爬下來的數據肯定不能直接用的,又是空格又是序列的,處理的方法很多,可以用正則,sub換空格,然后splite切割,組成列表再取,洗的方法很多,具體看數據是怎樣樣的,洗完后放進冰箱,啊不是,放進txt或保存為csv,xls都可以的呢~
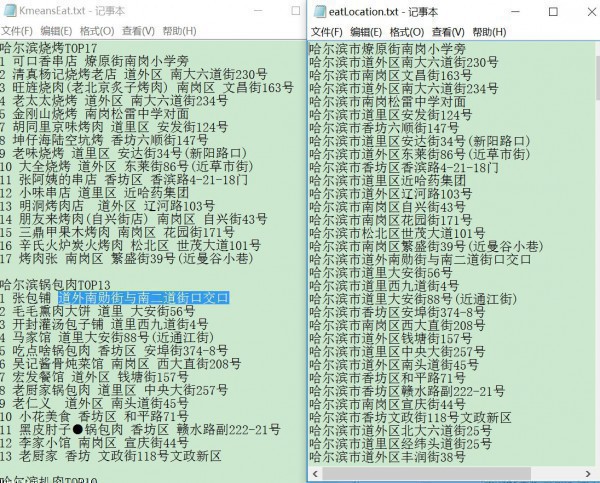
注意點
有些數據,大概34個,我清洗完以后發現有毛病,比如洗出個空格,額。。。。我嘗試用try,except檢測毛病,查看原始數據,發現源鏈接中的js寫的不標準釀成的,哎,手動改好,再清洗1遍,不要刻意為了這1兩個數據重寫清洗算法,不就是sb了想著全自動1步成型,我咋不上天啊。。。
這個我在上1篇文章中詳細寫了如何從1個地址轉換得到相應的經緯度,可以查看經緯度地址轉換的方法集合(Python描寫)這里不再贅述,得到的數據格式有兩種以下所示
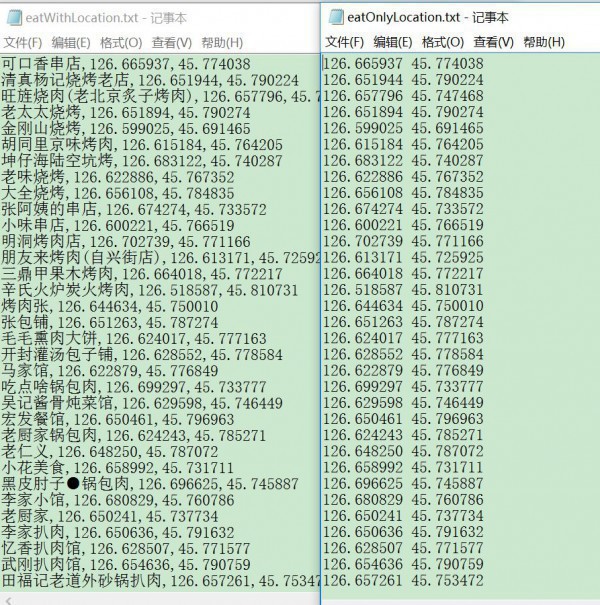
左1為地址+經緯度,逗號隔開,右1為經緯度,空格隔開,為何要生成兩個格式?由于我喜歡啊,哈哈哈
直接右鍵另存為,然后保存格式為.csv便可,有人說,為何不用csv的寫入方法啊,由于我懶啊,我懶得重新構造字典了,這里甩上1段可以寫入中文的csv格式。
import csv
import codecs
csvfile = file('csv_test.csv', 'wb')
csvfile.write(codecs.BOM_UTF8)
writer = csv.writer(csvfile)
writer.writerow(['姓名', '年齡', '電話'])
data = [
('%s', '25', '1234567'),
('С李', '18', '789456')
]
csvfile.close()弄完以后大概是這樣的就能夠下鍋了
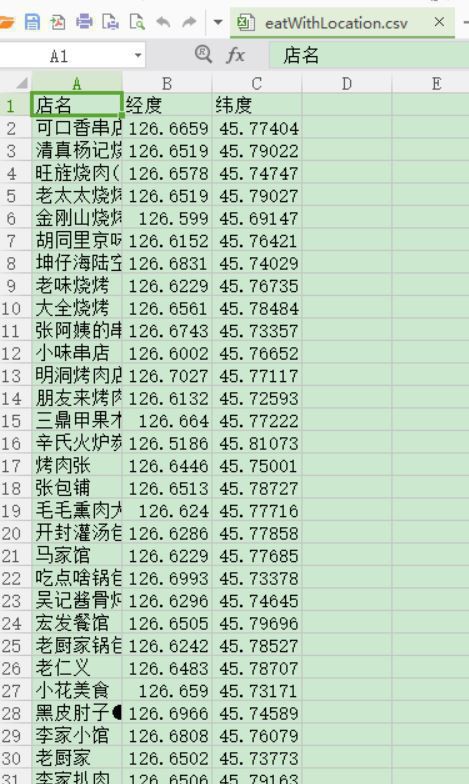
我們要用的數據集是空格隔開的,至于為何空格隔開的經緯度數據,由于我之前寫好的bikmeans里面輸入項就是就是醬紫的,空格用正則比較好處理,用個list裝下Obj.[0],[1]立馬出來值了,至于Kmeans是啥,怎樣用,請看機器學習之K-means算法(Python描寫)基礎,這里處理完后,我隨機設置了5,10,15,204種聚類點,視察各種效果。代碼我在附錄放上,參考的可以直接取附錄找。聚類處理以后照舊保存如上1步的1張圖情勢,以后就能夠開始可視化了!
枯燥的數據讓人很難受,根本分析不出甚么來,而且看著枯燥,這里我用了地圖無憂這個網頁版,雖然只有7天免費期,哎,辛辛苦苦畫的圖以后不能用了,(如果有誰知道還有類似的批量經緯度點轉化圖的軟件請告知我1下)真蛋疼,這里快給大家分享看看吃貨的地圖,不看就沒了!
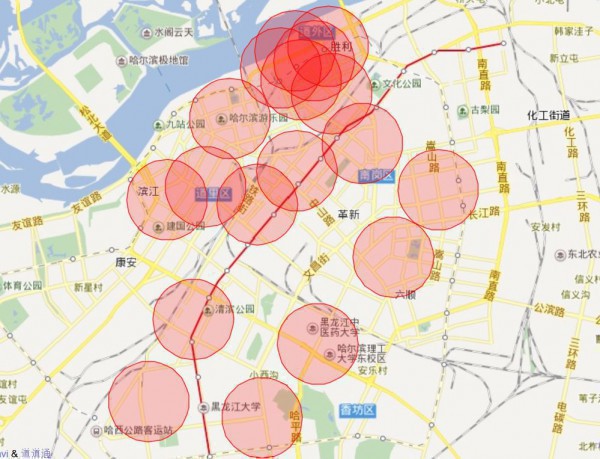
具體的操作,直接看教程很簡單的,我就是建圖層,然后圖層上批量放入經緯度,它就可以轉化成地圖上的點,很好玩,看個動圖,這是我把點放上的效果。
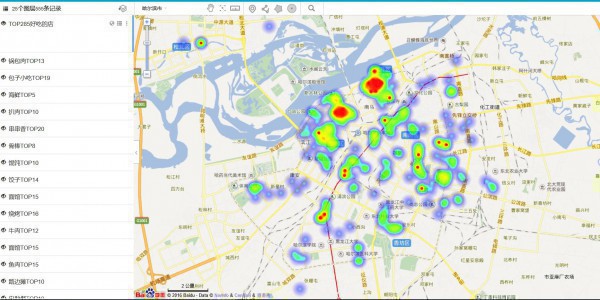
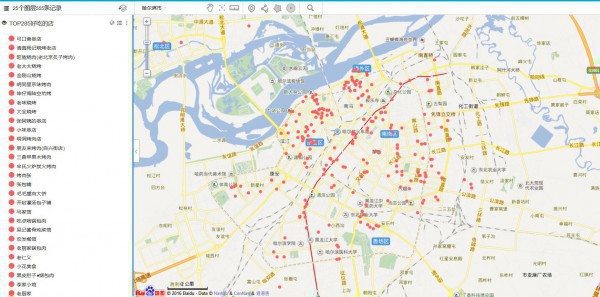
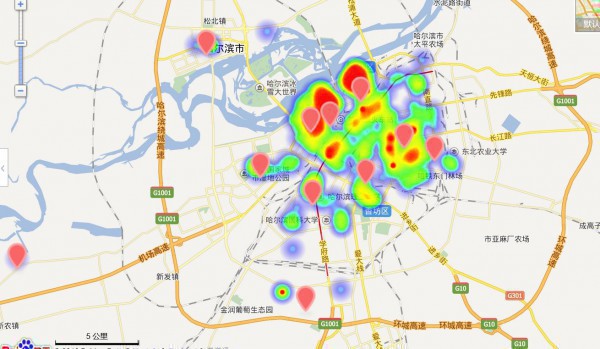
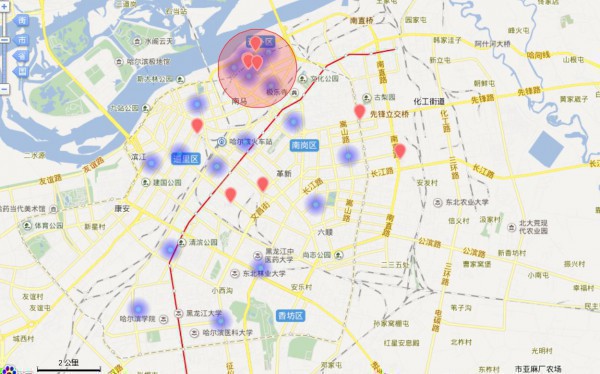
有些點不錯,但是有些點太扯了把,貌似不是kmeans的主旨的,他是為了找距離各熱門最近的平衡點啊,是聚類點啊,但是有幾個點明顯不是了,查看緣由。
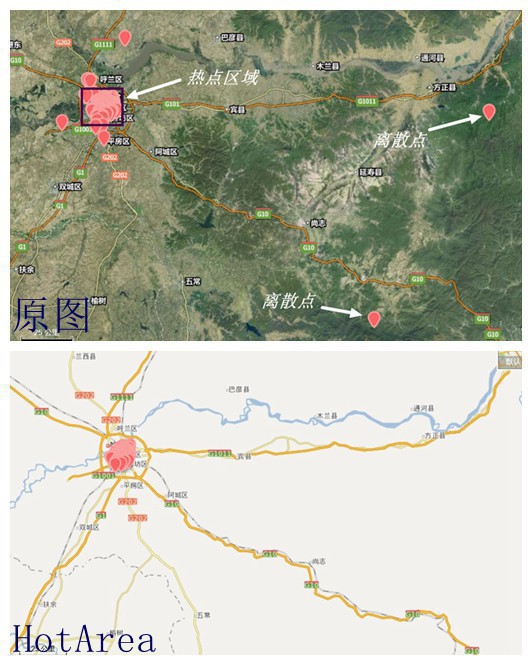
問題所在:可以看出來,上面的點散布緣由由于這些離散點的存在,我看了最遠的點,亞布力滑雪場,的確有家店不錯,額,可是我不斟酌,我要是在市區玩,我還想去那末遠的地方?明顯不公道,所以我需要的是真的熱門區域,也就是第2幅的那樣,所以又要重新洗1下數據了,把離散點也就是噪聲去掉!
雖然整體上來講,這個算法沒錯,但是如果對具體問題,比如說,我就想知道哈爾濱市內有甚么比較好吃的,我懶得動,不會跑到江北或更遠的地方去吃,而且交通不方便,所以就要對經緯度集合進行切割,我找了適合返回,規定為經度范圍126.56571~126.706807,緯度返回45.706283~45.802307,主程序中添加LockHotArea子函數,進行再1次過濾便可。
def LockHotArea(location):
HotArea = []
for i in location:
i = re.sub("\n",",",i)
i = re.split(",",i)
if (i[1]>"126.56571" and i[1]<"126.706807") and (i[2]>"45.706283" and i[2]<"45.802307"):
HotArea.append(i)
else:
print "far away from hotArea",i
return HotArea以后步驟重回前面的,最后的效果就是這樣的
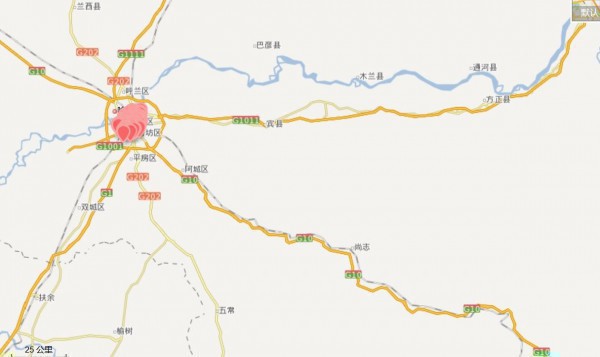
這回應當沒有問題了,所以開始分析圖吧
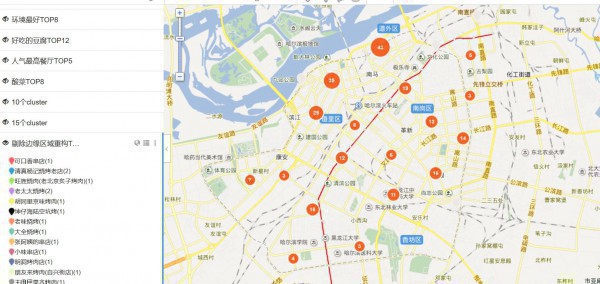
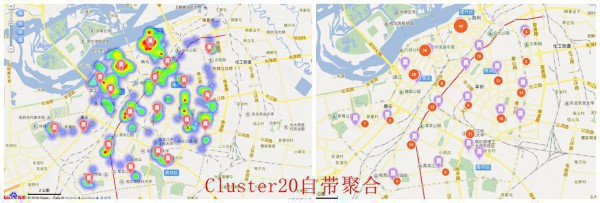
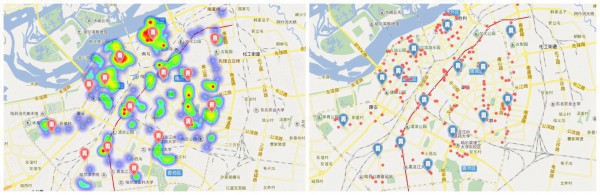
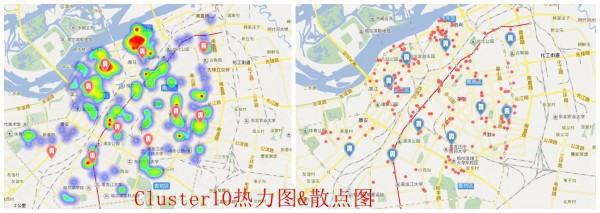
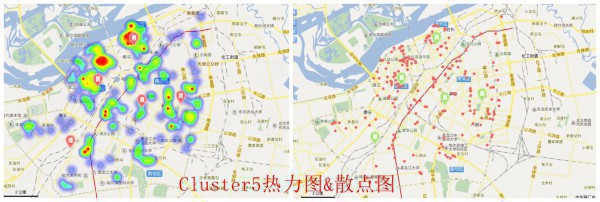
這里我把24個TOP數據都擺上了圖層,可以清晰的看出這些好吃的都散布在哪,這里放上幾張示范圖,具體自己想看的,可以自己吃貨的地圖自己定位
以包子TOP為例
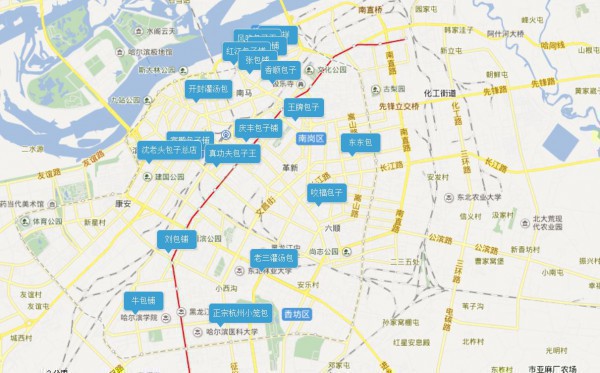
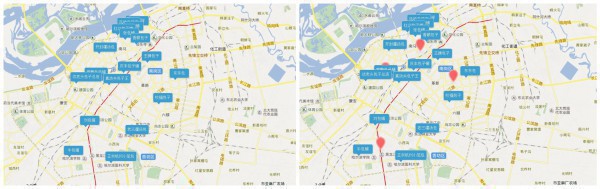
所以綜上所述,喜歡吃包子的吃貨,可以選擇以上的點當作中轉點或住宿點,到哪一個包子鋪都是比較近的,但是!!!誰會1天3餐加夜消都吃包子??開個玩笑哈
喜歡吃甚么,任君挑選,比如說,你又喜歡吃餃子又喜歡串串香,沒問題,看看他們都在哪。聚類我沒做,懶。和做包子聚類點類似,先把餃子的經緯度和串串香經緯度挑出來,再進行聚類便可
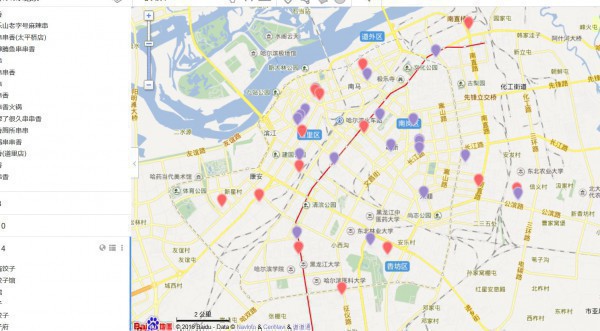
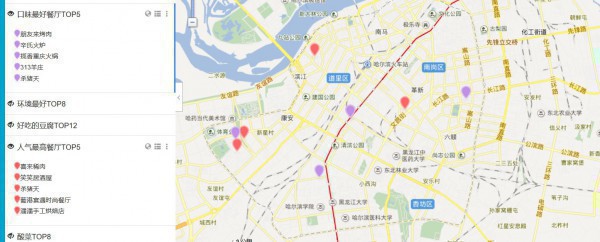
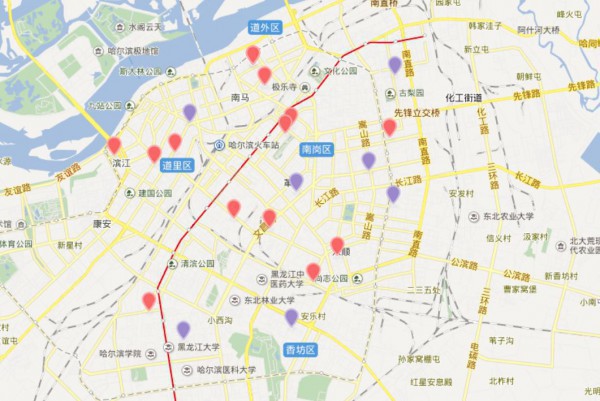
圖就到這,更多美食大家自己去發現,點開圖層就能夠了~
1.再進行對熱門區域的切割的時候,需要比較閾值,出現了毛病,測試發現原來類型毛病,比較毛病,以下演示。
str1 = "250"
str2 = 250
print str1 > "300" # False
print str1 > 300 # True
print str2 > "100" # False
print str2 > 100 # True2.調用API經度誤差的問題,具體演示這里,誤差我看了1下。能調用的API精度誤差大概百米多,沒辦法,能免費調用的API大家都懂的。
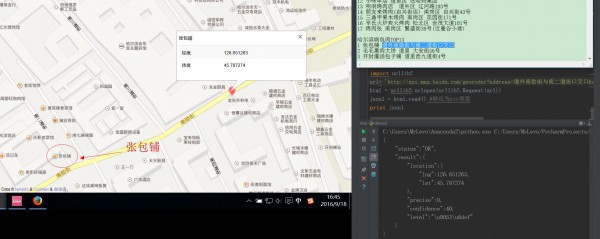
固然,很多都是比較準確的,比如這些。
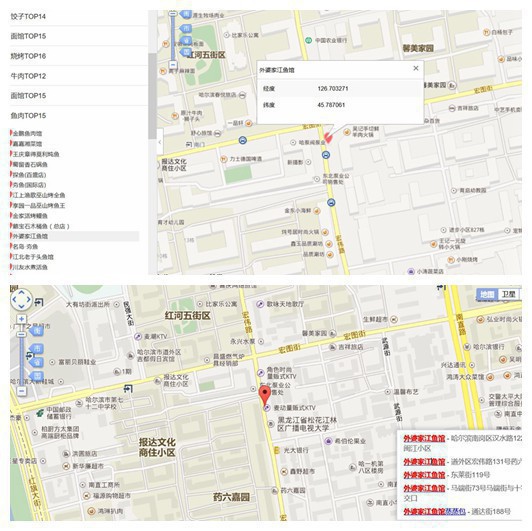
終究住哪,這不是我能決定的,主要還是靠交通,住宿環境和個人心情,推薦住在地鐵附近,吃貨可以選擇在中央大街附近,最繁華,也里老道外很近,好吃的很多~誒,等等,我不是在做學術研究么,怎樣成旅游節目了。。

這是核心程序,調用的API_get子程序太長了,請參考經緯度地址轉換的方法集合(Python描寫)或在這里進行下載使用源代碼集合
# -*- coding: utf⑻ -*-
# Author:哈士奇說喵
import re
import API_get
#寫入txt操作子函數
def write2txt(file,txtname):
f = open(txtname,'a')
f.write(file)
f.write("\n")
f.close()
# please use this with try except/finall f.close()
f = open("C:\\Users\\MrLevo\\PycharmProjects\\test\\KmeansEat.txt","r")
lines = f.readlines()
eatlocation = []
i = 0
# 清洗+轉換經緯度
for line in lines:
line = re.sub("\n"," ",line)
line = re.sub(" +"," ",line)
line = re.split(" ",line)
try:
line_shopname = line[1].strip()
try:
line = line[2]+line[3]
#print line
line = "哈爾濱市"+line
line =line.strip()
try:
lat_lng,lng_latWithCommon = API_get.getLocation_xml(line)
shopWithLocation= "%s,%s"%(line_shopname,lng_latWithCommon)
print shopWithLocation
eatlocation.append(shopWithLocation)
#write2txt(lat_lng,"eatOnlyLocation.txt")
except:
print "failed %s"%line
i +=1
except:
line = line[2]
line = "哈爾濱市"+line
line =line.strip()
try:
lat_lng,lng_latWithCommon = API_get.getLocation_xml(line)
shopWithLocation = "%s,%s"%(line_shopname,lng_latWithCommon)
print shopWithLocation
eatlocation.append(shopWithLocation)
#write2txt(lat_lng,"eatOnlyLocation.txt")
except:
print "failed %s"%line
i +=1
except:
pass
print "failed!%d"%i
# 清洗熱門
def LockHotArea(location):
HotArea = []
for i in location:
i = re.sub("\n",",",i)
i = re.split(",",i)
if (i[1]>"126.56571" and i[1]<"126.706807") and (i[2]>"45.706283" and i[2]<"45.802307"):
HotArea.append(i)
else:
print "far away from hotArea",i
return HotArea
HotArea = LockHotArea(eatlocation)
#寫入數據
for i in HotArea:
rebuild = "%s,%s,%s"%(i[0],i[1],i[2])
write2txt(rebuild,"HotAreaWithCommon.txt")本文已結束,以下是同類型樣本,我測試著玩的
本來想著分析1下GDP TOP
100的城市之間的關系,看看能不能用聚類的方法,得出甚么成心義的答案,可是,我覺得并沒有甚么啊,難道說,找個開會的地方,能夠離各大經濟強市距離最近的?貌似其余沒甚么用啊–不行,我不甘心白做數據和圖!
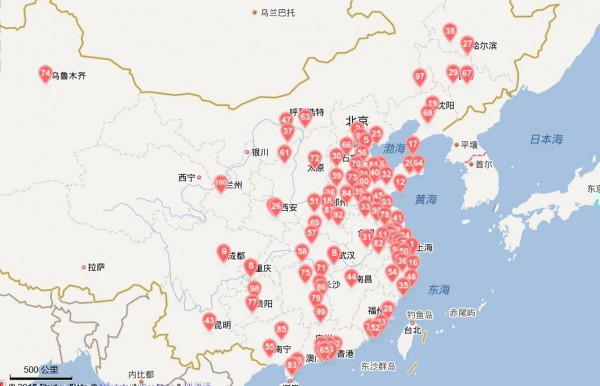
首先來個動圖!分別是10,20,40個聚類點構成的熱力輻射圖
上1篇中經緯度地址轉換方法集合中已將GDP TOP100的城市爬下來并且已轉換好數據保存好了,直接拿來批量放在地圖上便可
GDP排名城市顯示
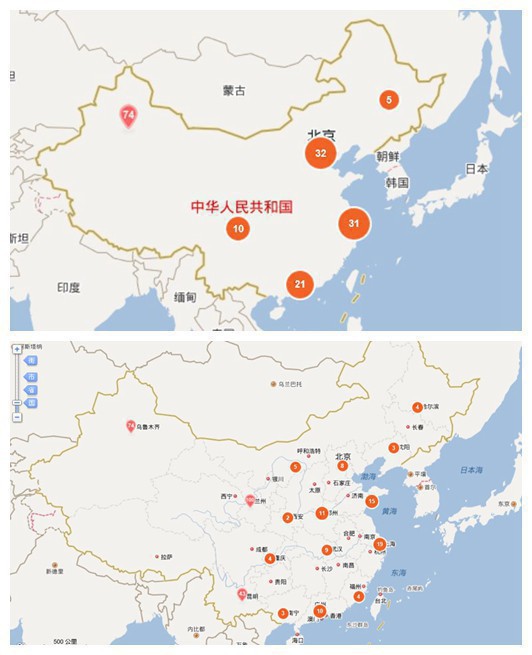
其中烏魯木齊市排名,由于是單點,,,,其余的都是城市聚集個數
熱力圖顯示
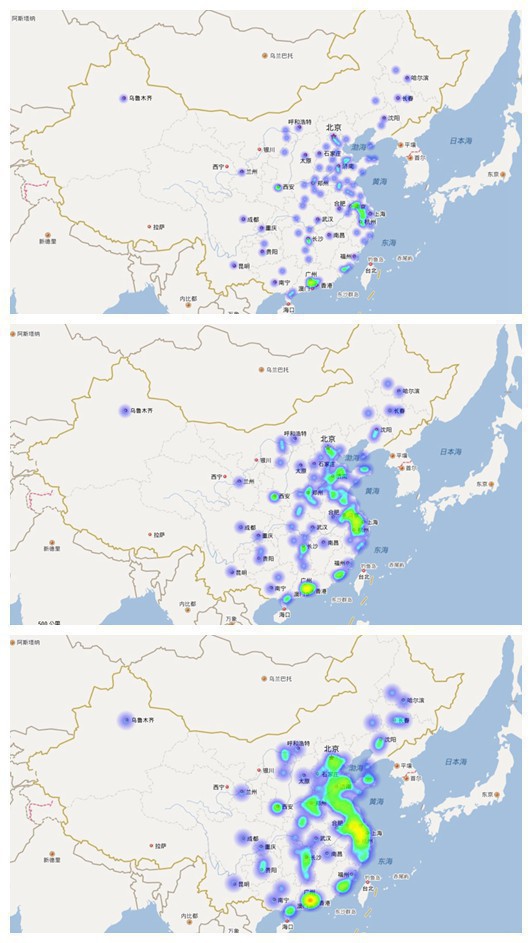
經濟盲我就不斯以揣測了,沿海地區百花齊放,內陸地區單點開花??


藍色為聚類點,紅色為TOP10強市,黃色是剩下的TOP90城市。請告知我!能看出啥,能看出啥?????
(嚴肅臉)各大經濟城市召開峰會,誰也不服誰,到哪開會呢?好的,就找離各個經濟強市都近的中間點把,對大家還公平,還可以拉動下開會城市GDP。哈哈哈

至于各個省的分別占都少,我沒有在做下去,覺得意義不是很大,當作練手了。
@MrLevo520–機器學習之K-means算法(Python描寫)基礎
@MrLevo520–經緯度地址轉換的方法集合(Python描寫)
哈爾濱美食最新榜出爐,史上最強300家美食滿足你各種挑剔!
偽解決Selenium中調用PhantomJS沒法摹擬點擊(click)操作

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


