
點擊原有虛擬機–>管理–>克隆–>下1步–>創建完成克隆–>寫入名稱hadoop-senior02–>選擇目錄
1)啟動克隆虛擬機(內存配置:01:2G;02:1.5G;03:1.5G)
2)修改主機名:改兩處
3)修改網卡名稱
編輯 /etc/udev/rules.d/70-persistent-net.rules
—>注釋掉包括eth0的行
—>把包括eth1行中的eth1改成eth0

編輯 /etc/sysconfig/network-script/ifcfg-eth0
—>將mac地址改成虛擬機設置的地址

5)配置完后重啟
6)設置固定IP

7)將3臺機器都連接到crt
1)首先將/tmp目錄下的所有東東都刪掉
$cd /tmp
$sudo rm -rf ./*
2)將hadoop⑵.5.0,maven,m2所有刪除
$cd /opt/modules/
3)將所有機器的主機名和IP映照好
編輯/opt/hosts
將所有機器添加每臺機器的映照,即在每臺虛擬機上打開該文件,并以下添加:

在windows中Hosts文件也一樣配置映照

如此在任1機器上都可以連接集群中的其他有機器。
4)在所有機器的opt目錄下添加1個目錄/app/并修改歸屬,所有集群都在這下面做(集群的安裝目錄必須統1!)
$sudo mkdir /opt/app
$sudo chown -R beifeng:beifeng /opt/app/
5)將hadoop⑵.5.0解壓到app目錄下(將1臺機器配好,然后發送給其他機器)
$tar -zxf /opt/softwares/hadoop⑵.5.0.tar.gz -C /opt/app/
散布式架構都采取主從架構,若為偽散布式則主從都在1臺機器,若散布式則主節點在1臺機器,從節點在多臺機器。1般把datanode和nodermanager放在1臺機器上,前者使用電腦磁盤空間去存儲數據,后者使用內存與CPU去計算分析數據。
若使用3臺虛擬機則可配置以下
| 3臺 | hadoop-senior | hadoop-senior02 | hadoop-senior03 |
|---|---|---|---|
| 內存 | 2G | 1.5G | 1.5G |
| CPU | 1核 | 1核 | 1核 |
| 硬盤 | 20G | 20G | 20G |
| 服務組件 | namenode | ||
| resourcemanager | |||
| datanode | datanode | datanode | |
| nodemanager | nodemanager | nodemanager | |
| MRHistoryserver | secondarynamenode |
若使用2臺虛擬機則可配置以下(本次練習只使用兩臺機器)
| 2臺 | hadoop-senior | hadoop-senior02 |
|---|---|---|
| 內存 | 2G | 1.5G |
| CPU | 1核 | 1核 |
| 硬盤 | 20G | 20G |
| 服務組件 | resoucemanager | |
| namenode | ||
| datanode | datanode | |
| nodemanager | nodemanager | |
| secondarynamenode | MRHistoryserver |
打開hadoop-evn.sh,mapred-env,yarn-env.sh
配置jdk的目錄給JAVA_HOME

創建tmp目錄:
$mkdir -p /opt/app/hadoop2.5.0/data/tmp
打開core-site.xml,添加配置以下:

打開slaves,配置以下

打開hdfs-site.xml
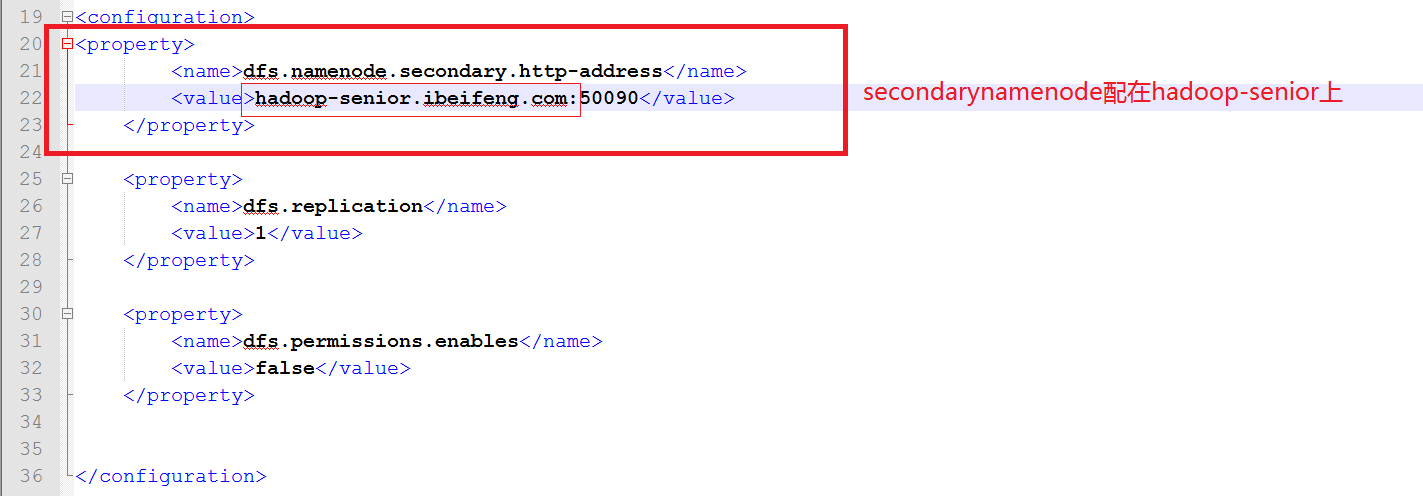
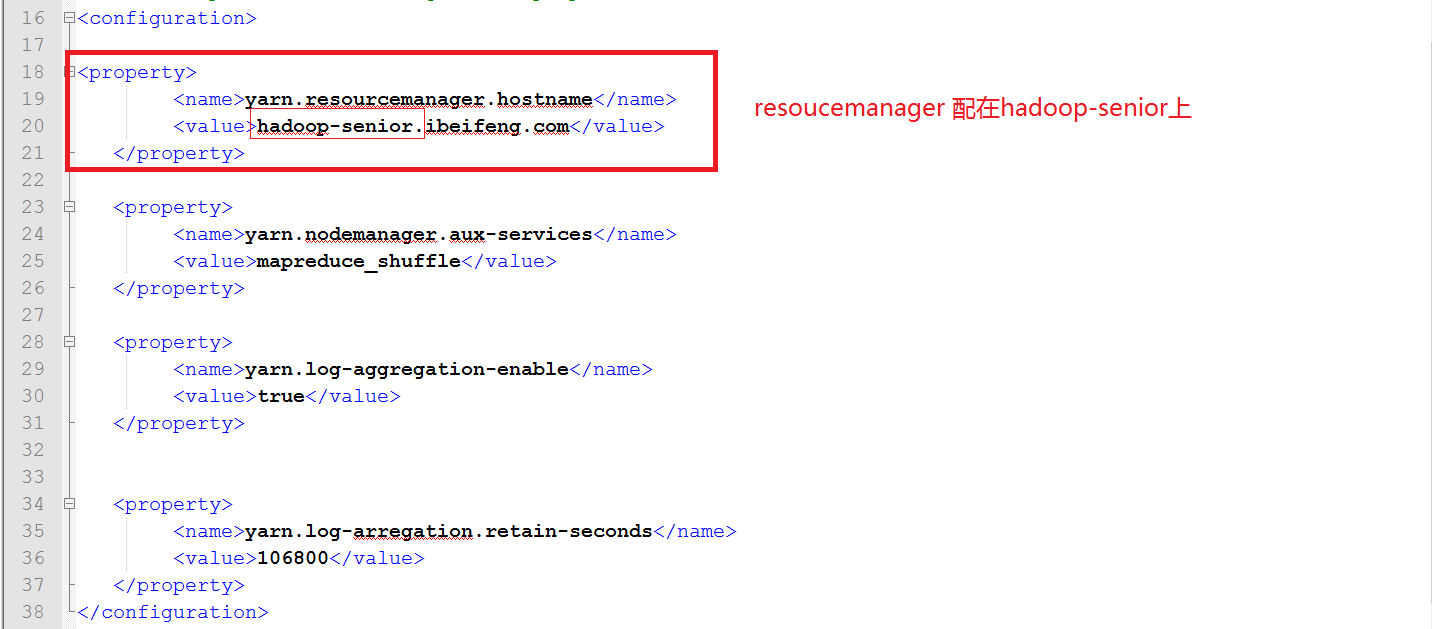
打開yarn-site.xml, 配置以下:
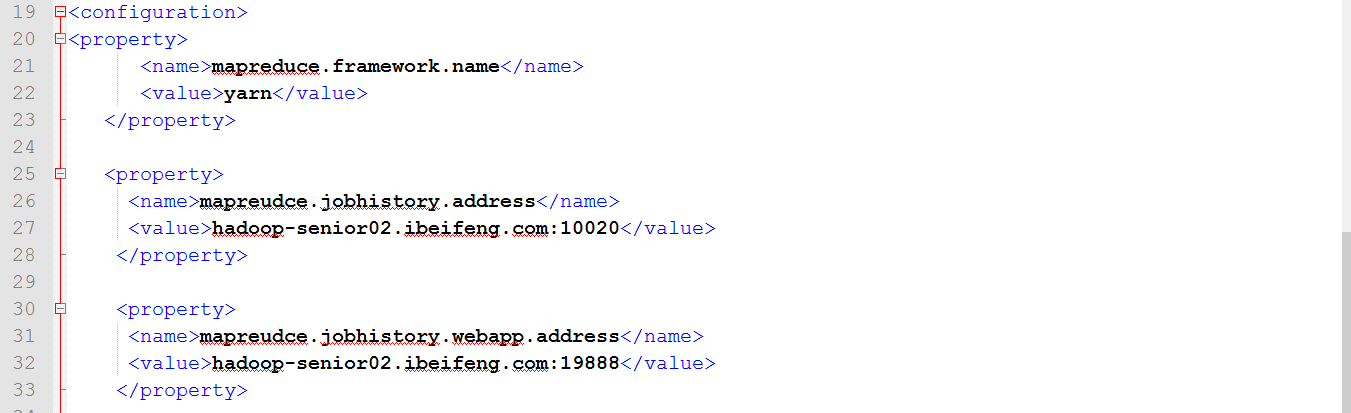
打開mapred.site.xml,配置以下:
$scp -r hadoop-2.5.0/ beifeng@hadoop-senior02.ibeifeng.com:/opt/app/1)先格式化hdfs
2)啟動 senior02的namenode,兩臺datanode
3)啟動senior的resourcemanager,兩臺nodemanager
4)啟動senior02的Jobserver
5)啟動senior的secondarynamenode


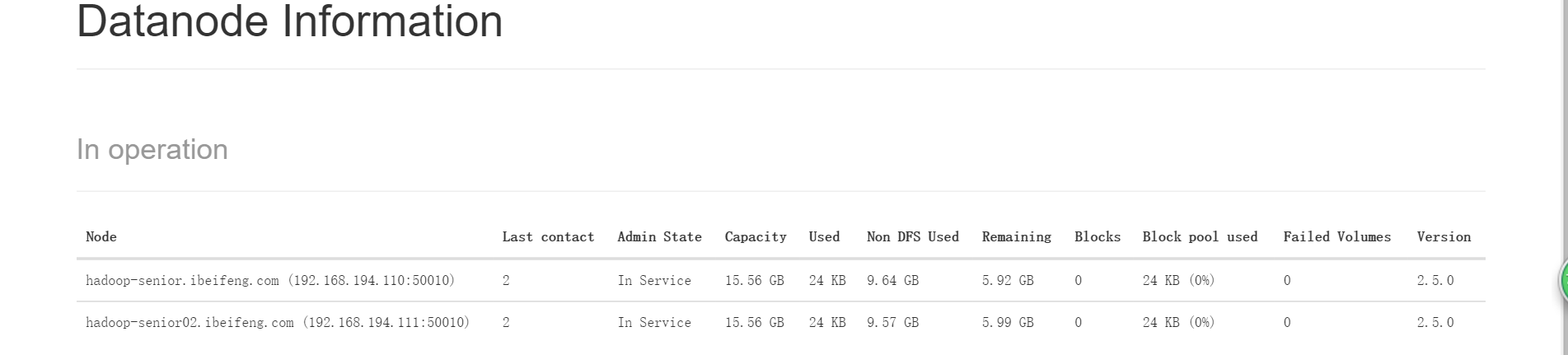
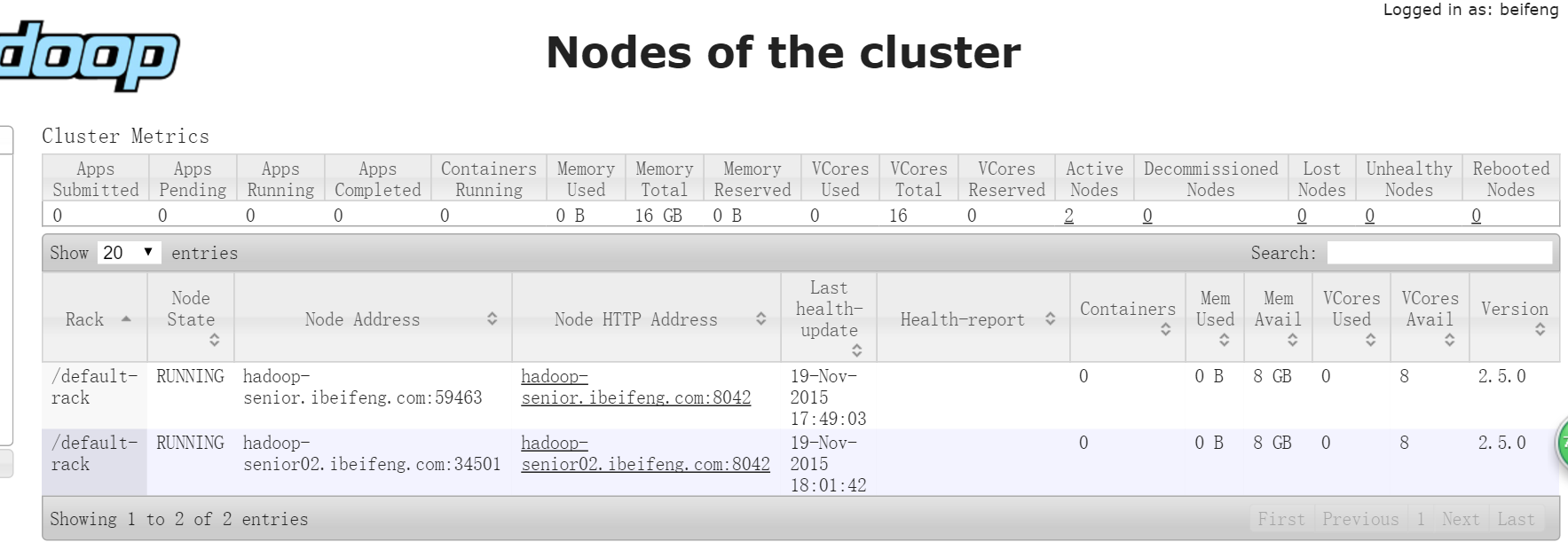
WEB UI查看datanode已生成了2個
WEB UI查看 nodemanager也有兩個
新建目錄
$bin/hdfs dfs -mkdir -p tmp/conf上傳文件
$bin/hdfs dfs -put etc/hadoop/*-site.xml tmp/conf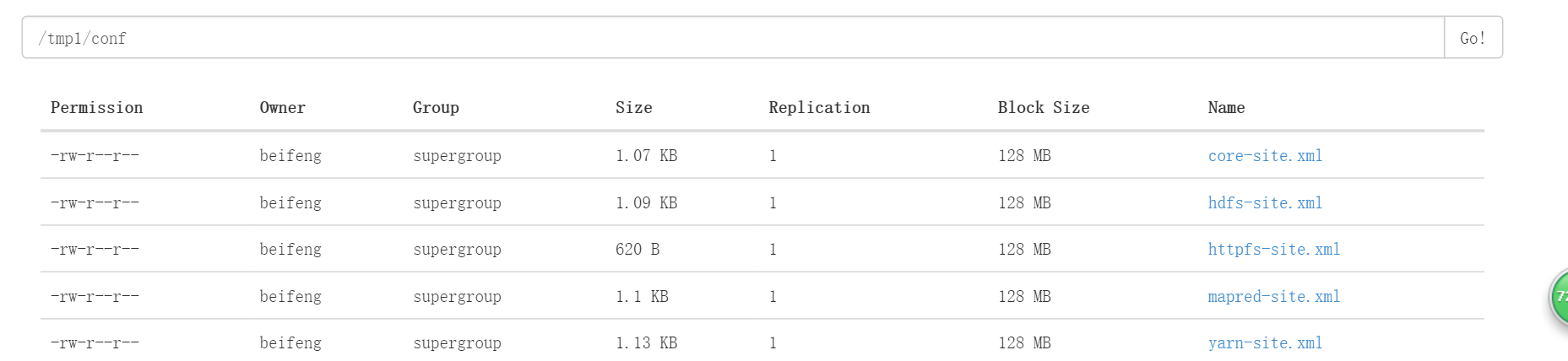
讀取文件
$bin/hdfs dfs -text tmp/conf/core-site.xml
1)新建目錄
$bin/hdfs dfs -mkdir -p mapreduce/wordcount/input2)上傳文件到目錄
bin/hdfs dfs -put /opt/datas/wc.input mapreduce/wordcount/input
3)運行wordcount程序
$bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount mapreduce/wordcount/input mapreduce/wordcount/output
4)讀取文件
$bin/hdfs dfs -text mapreduce/wordcount/output/par*
測試磁盤內存
1)
$bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar2)
$bin/yarn jar hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.5.0.jar現將原本的全刪掉:
$cd .ssh/
$rm -rf ./*在主節點上分別配置nodemanager 和 resourcemanage兩個主節點:
1)生成1對公鑰與密鑰
$ssh-keygen -t rsa2)拷貝公鑰到各個機器上
$ssh-copy-id bigdata-senior.ibeifeng.com
$ssh-copy-id bigdata-senior02.ibeifeng.com3)shh鏈接
$ssh bigdata-senior.ibeifeng.com
$ssh hadoop-senior02.ibeifeng.com如圖
集群時間同步
如在01機上:
1)查看時間服務器是不是安裝:
sudo rmp -qa|grep ntp2)查看時間服務器運行狀態
sudo service ntp status 3)開啟時間服務器
sudo chkconfig ntpd start4)設置隨機啟動
sudo chkconfig ntpd on5)查看啟動狀態
sudo chkconfig --list|grep ntpd6)配置文件
sudo vi /etc/ntp.conf3處修改:
(1)刪除下1行的注釋,并修改網段(IP地址的前3串,后面為.0)
restrict 192.168.194.0 mask 255.255.255.0 nomodify notrap
(2)將時間服務器server注釋掉
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
(3)去掉以下兩行注釋
server 127.127.1.0....
fudge 127.127.1.1.0.....
7)重啟服務器
sudo service ntpd restart8)時間服務器與bios同步
$sudo vi /etc/sysconfig/ntpd添加內容:
SYNC_HWLOCK=yes
等待5分鐘
1)配置所有機器與這臺hadoop-senior機器同步
sudo /usr/sbin/ntpdate hadoop-senior.ibeifeng.com2)寫1個定時任務,每過1段時間與時間服務器進行同步時間
首先切換到root
設置每過10分鐘更新1次同步
$sudo crontab -e加入:0⑸9/10* * * */user/sbin/ntpdate hadoop-senior.ibeifeng.com
3)設置時間
sudo date -s 2015-11-17
sudo date -s 17:54:00
上一篇 [置頂] 打印1到最大的n位數
下一篇 Podfile文件詳解
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


