
Scala集合繼承層級中的關鍵特質:
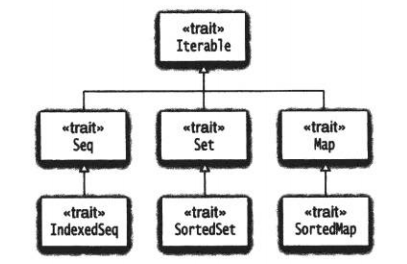
Iterable值的是那些能申城用來訪問集合中所有元素的Iterator的集合,類似于C++的迭代器。
val coll = ... //某種Iterable
val iter = coll.iterator
while (iter.hasNext) {
對iter.next() 履行某種操作
}Seq是1個有前后次序的值的序列,例如數字或列表。IndexedSeq允許我們通過使用下標的方式快速訪問元素。
Set是1組沒有前后次序的值的集合。在SortedSet中,元素是排序的。
Map是1組(key, value)對偶。 SortedMap依照鍵的排序的。
每一個Scala集合特質或類都有1個帶有apply方法的伴生對象,這個apply方法可以用來構建該集合的實例,而不用使用new,這樣的設計叫做”統1創建原則”。
Scala同時支持可變和不可變的集合。Scala優先采取不可變集合,因此你可以安全的同享其援用。任何對不可變集合的修改操作都返回的是1個新的不可變集合,它們同享大部份元素。
def digits(n: Int): Set[Int] = {
if (n < 0) digits(-n)
else if (n < 10) Set(n)
else digits(n / 10) + (n % 10)
}這個例子利用遞歸不斷的產生新的集合,但是要注意遞歸的深度。
最重要的不可變序列:
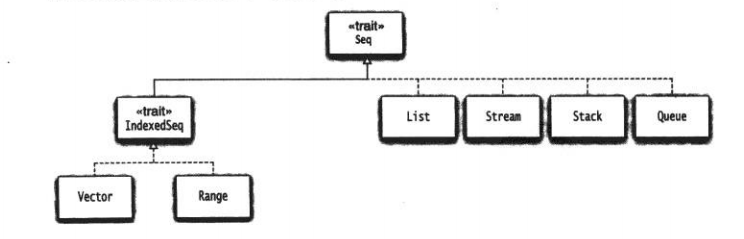
Vector是ArrayBuffer的不可變版本,和C++的Vector1樣,可以通過下標快速的隨機訪問。而Scala的Vector是以樹形結構的情勢實現的,每一個節點可以有不超過32個子節點。這樣對有100萬的元素的向量而言,只需要4層節點。
Range表示1個整數序列,例如0,1,2,3,4,5 或 10,20,30 . Rang對象其實不存儲所有值而只是起始值、結束值和增值。
最有用可變序列:
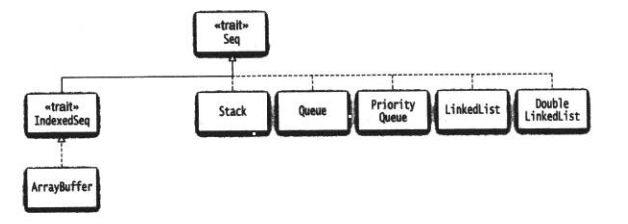
在Scala中,列表要末是Nil(空列表),要末是1個head元素加上1個tail,而tail又是1個列表。例如:
val digits = List(4,2)
digits.head // 4
digits.tail // List(2)
digits.tail.head // 2
digits.tail.tail // Nil:: 操作符從給定的頭和尾創建列表:
9 :: List(4, 2) // List(9,4,2)
// 同等于
9 :: 4 :: 2 :: Nil // 這里是又結合的遍歷鏈表:可使用迭代器、遞歸或模式匹配
def sum(lst: List[Int]): Int = {
if (lst == Nil) 0 else lst.head + sum(lst.tail)
}
def sum(lst: List[Int]): Int = lst match {
case Nil => 0
case h :: t => h + sum(t)
}可變的LinkedList既可以修改頭部(對elem援用賦值),也能夠修改尾部(對next援用賦值):
val lst = scala.collection.mutable.LinkedList(1, -2, 7, -9)
// 修改值
var cur = lst
while (cur != Nil) {
if (cur.elem < 0) cur.elem = 0
cur = cur.next
}
// 去除每兩個中的1個
var cur = lst
while (cur != Nil && cur.next != Nil) {
cur.next = cur.next.next
cur = cur.next
}注意: 如果你想要將列表中的某個節點變成列表的最后1個節點,你不能夠將next援用設為Nil,而應當將next援用設為LinkedList.empty。也不要設為null,不然在遍歷該鏈表時會遇到空指針毛病。
集是不重復的元素的集合,與C++中的set相同。集其實不保存元素插入的順序,默許情況下,集以哈希集實現。
而鏈式哈希集可以記住元素插入的順序,它會保護1個鏈表來到達這個目的。
val weekdays = scala.collection.mutable.LinkedHashSet("Mo", "Tu", "We", "Th", "Fr")對SortedSet已排序的集使用紅黑樹實現的。Scala沒有可變的已排序的集,前面已講過。
集的1些常見操作:
val digits = Set(1,7,2,9)
digits contains 0 // false
Set(1, 2) subsetOf digits // true
val primes = Set(2,3,5,7)
digits union primes // Set(1,2,3,5,7,9)
// 同等于
digits | primes // 或 digits ++ primes
digits intersect primes // Set(2, 7)
// 同等于
digits & primes
digits diff primes // Set(1, 9)
// 同等于
digits -- primes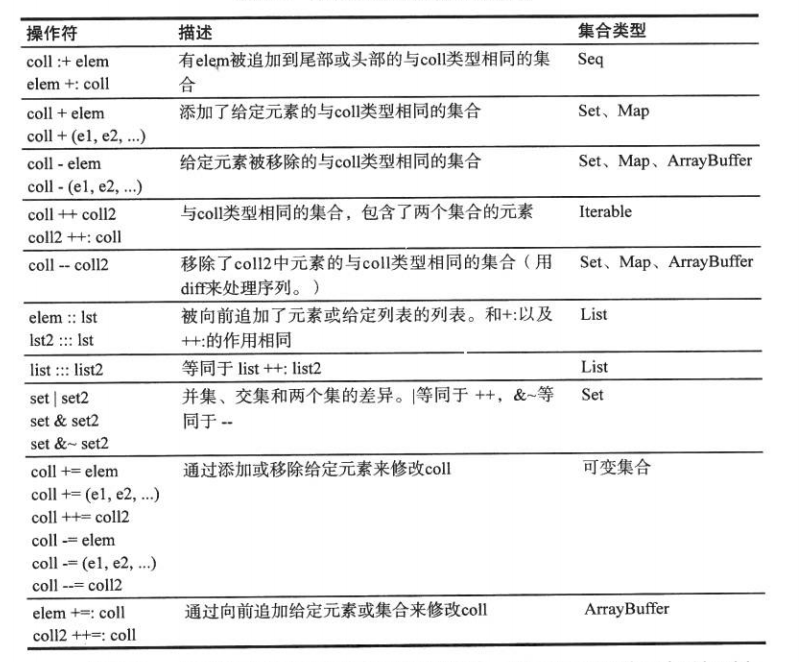
1般而言, + 用于將元素添加到無前后次序的集合,而+: 和 :+ 則是將元素添加到有前后次序的集合的開頭或是結尾。
Vector(1,2,3) :+ 5 // Vector(1,2,3,5)
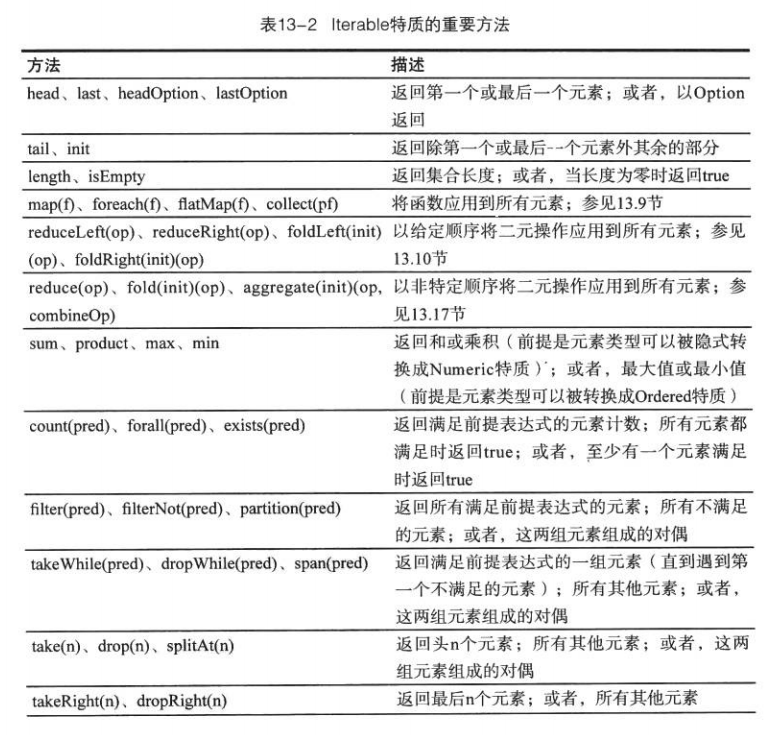
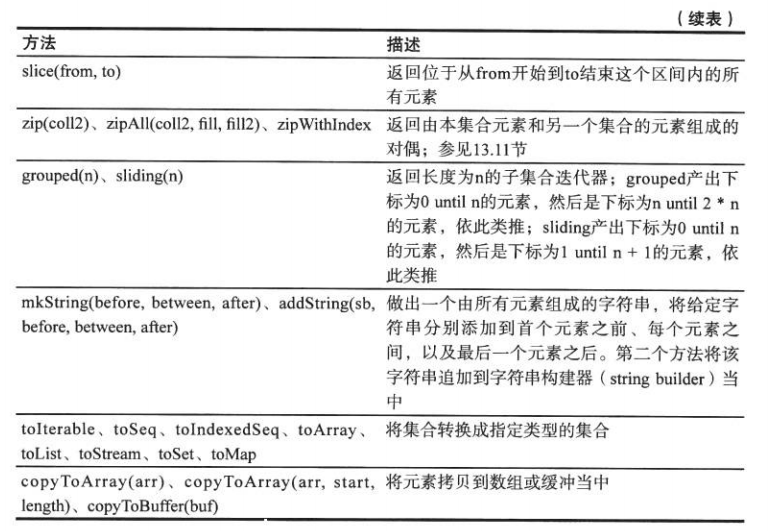
1 +: Vector(1,2,3) // Vector(1,1,2,3)Iterable特質最重要的方法:
Seq特質在Iterable特質的基礎上又增加的1些方法:


map方法可以將某個函數利用到集合的每個元素并產出其結果的集合。例如:
val names = List("Peter", "Paul", "Mary")
names.map(_.toUpperCase) // List("PETER", "PAUL", "MARY")
// 同等于
for (n <- names) yield n.toUpperCase如果函數產出1個集合而不是單個值得話,則使用flatMap將所有的值串接在1起。例如:
def ulcase(s: String) = Vector(s.toUpperCase(), s.toLowerCase())
names.map(ulcase) // List(Vector("PETER", "peter"), Vector("PAUL", "paul"), Vector("MARY", "mary"))
names.flatmap(ulcase) // List("PETER", "peter", "PAUL", "paul", "MARY", "mary")collect方法用于偏函數—并沒有對所有可能的輸入值進行定義的函數。例如:
"⑶+4".collect {case '+' => 1; case '-' => -1} // Vector(⑴,1)
"⑶+4".collect {case '-' => -1} // Vector(⑴)
"⑶+4".collect {case '+' => 1} // Vector(1)
"⑶+4".collect {case '*' => 1} // Vector()foreach方法將函數利用到各個元素但不關心函數的返回值。
names.foreach(println)reduceLeft、reduceRight、foldLeft、foldRight、scanLeft、scanRight方法將會用2元函數來組合集合中的元素:
List(1,7,2,9).reduceLeft(_ - _) // ((1 - 7) - 2) - 9
List(1,7,2,9).reduceRight(_ - _) // 1 - (7 - (2 - 9))
List(1,7,2,9).foldLeft(0)(_ - _) // 0 - 1 ⑺ - 2 - 9
List(1,7,2,9).foldRight(0)(_ - _) // 1 - (7 - (2 - (9 - 0)))
(1 to 10).scanLeft(0)(_ + _) // Vector(0, 1, 3, 6, 10, 15, 21, 28, 36, 45, 55)前面的章節已講過拉鏈操作。除zip方法外,還有zipAll和zipWithIndex方法
List(5.0, 20,0, 9.7, 3.1, 4.3).zipAll(List(10, 2), 0.0, 1) // List((5.0, 10), (20.0, 2), (9.7, 1), (3.1, 1), (4.3, 1))
"Scala".zipWithIndex // Vector(('S', 0), ('c', 1), ('a', 2), ('l', 3), ('a', 4) )迭代器的好處就是你不用將開消很大的集合全部讀進內存。例如讀取文件操作,Source.fromFile產出1個迭代器,使用hasNext和next方法來遍歷:
while (iter.hasNext)
對 iter.next() 履行某種操作這里要注意迭代器多指向的位置。在調用了map、filter、count、sum、length等方法后,迭代器將位于集合的尾端,你不能再繼續使用它。而對其他方法而言,比如find或take,迭代器位于已找到元素或已獲得元素以后。
流是1個尾部被懶計算的不可變列表—–也就是說,只有當你需要時它才會被計算。
def numsFrom(n: BigInt): Stream[BigInt] = n #:: numsFrom(n + 1)
val tenOrMore = numsFrom(10) // 得到1個 Stream(10, ?) 流對象,尾部未被求值
temOrMore.tail.tail.tail // Stream(13, ?)流的方法是懶履行的。例如:
val squares = numsFrom(1).map(x => x * x) // 產出 Stream(1, ?)
// 需要調用squares.tail來強迫對下1個元素求值
squares.tail // Stream(4, ?)
// 使用take和force強迫求指定數量的值
squares.take(5).force // Stream(1,4,9,16,25)注意: 不要直接使用 squares.force, 這樣將會是1個無窮的流的所有成員求值, 引發OutOfMemoryError 。
利用view方法也能夠實現懶履行,該方法產出1個其方法總是被懶履行的集合。例如:
val powers = (0 until 1000).view.map(pow(10, _))
powers(100) //pow(10, 100)被計算,其他值的冪沒有被計算和流不同,view連第1個元素都不求值,除非你主動計算。view不緩存任何值,每次調用都要重新計算。
懶集合對處理以多種方式進行變換的大型集合很有好處,由于它避免了構建出大型中間集合的需要。例如:
(0 to 1000).map(pow(10, _)).map(1 / _) // 1
(0 to 1000).view.map(pow(10, _)).map(1 / _).force // 2第1個式子 會產出兩個集合,第1個集合的每個元素是pow(10, n),第2個集合是第1個集合中每一個集合中的元素取倒數。 而第2個表達式使用了視圖view,當動作被強迫履行時,對每一個元素,這兩個操作是同時履行的,不需要額外構建中間集合。
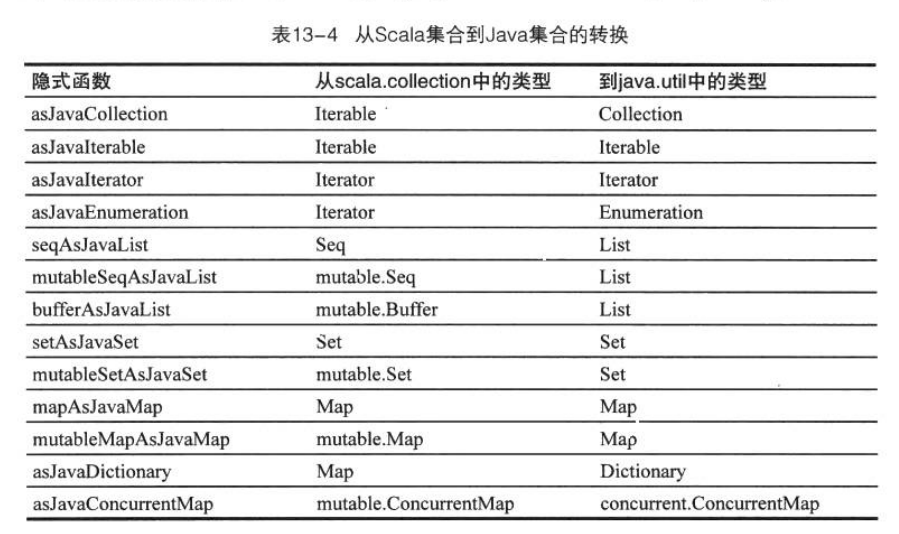
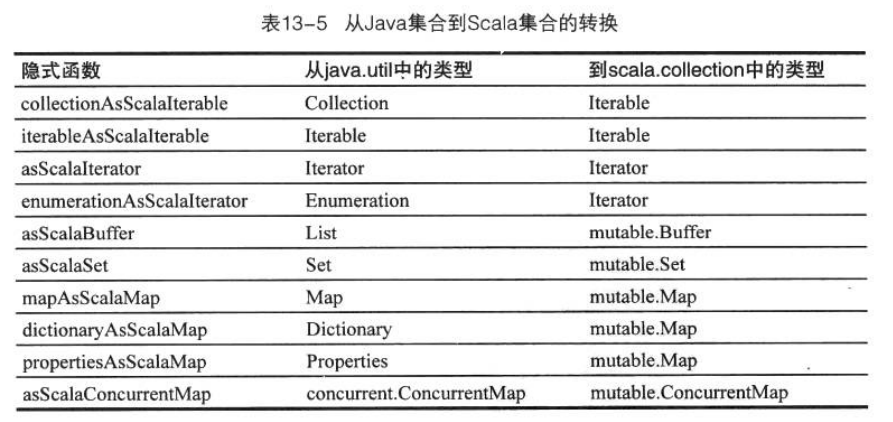
Scala類庫提供了6個特質,你可以將它們混入集合,讓集合的操作變成同步:
SynchronizedBuffer
SynchronizedMap
SynchronizedPriorityQueue
SynchronizedQueue
SynchronizedSet
SynchronizedStack
例如:
val scores = new scala.collection.mutable.HashMap[String, Int] with scala.collection.mutable.SynchronizedMap[String, Int]固然,還有更高效的集合,例如ConcurrentHashMap或ConcurrentSkipListMap,比簡單的用同步方式履行所有的方法更加有效。
集合的par方法產出當前集合的1個并行實現,例如sum求和,多個線程可以并發的計算不同區塊的和,在最后這部份結果被匯總到1起。
coll.par.sum你可以通過對要遍歷的集合利用par并行for循環
for(i <- (0 until 100).par) print(i + " ")
而在 for/yield循環中,結果是順次組裝的:
for(i <- (0 until 100).par) yield i + " "
這里要注意變量是同享變量,還是循環內的局部變量:
var count = 0
for (c <- coll.par) {if (c % 2 == 0) count += 1} // error**注意: **par方法返回的并行集合的類型為擴大自ParSeq、ParSet或ParMap特質的類型,所有這些特質都是ParIterable的子類型。這些其實不是Iterable的子類型,因此你不能將并行集合傳遞給預期Iterable、Seq、Set、Map方法。你可以用ser方法將并行集合轉換回串行集合,也能夠實現接受通用的GenIterable、GenSeq、GenSeq、GenMap類型的參數的方法。
說明: 其實不是所有的方法都可以被并行化。例如reduceLeft、reduceRight要求每一個操作符依照順序前后被利用。

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


