
所謂IO,也就是Input與Output的縮寫。在java中,IO觸及的范圍比較大,這里主要討論針對文件內(nèi)容的讀寫
其他知識點將放置后續(xù)章節(jié)
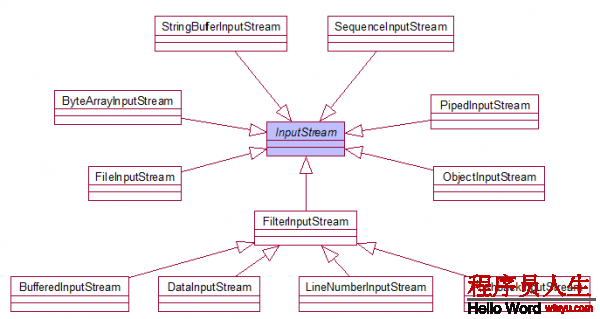
對文件內(nèi)容的操作主要分為兩大類
分別是:
其中,字符流有兩個抽象類:Writer Reader
其對應子類FileWriter和FileReader可實現(xiàn)文件的讀寫操作
BufferedWriter和BufferedReader能夠提供緩沖區(qū)功能,用以提高效力
一樣,字節(jié)流也有兩個抽象類:InputStream OutputStream
其對應子類有FileInputStream和FileOutputStream實現(xiàn)文件讀寫
BufferedInputStream和BufferedOutputStream提供緩沖區(qū)功能
概念:
字符流處理的單元為2個字節(jié)的Unicode字符,分別操作字符、字符數(shù)組或字符串,而字節(jié)流處理單元為1個字節(jié), 操作字節(jié)和字節(jié)數(shù)組。所以字符流是由Java虛擬機將字節(jié)轉(zhuǎn)化為2個字節(jié)的Unicode字符為單位的字符而成的,所以它對多國語言支持性比較好!如果是 音頻文件、圖片、歌曲,就用字節(jié)流好點,如果是關系到中文(文本)的,用字符流好點.
字節(jié)流可用于任何類型的對象,包括2進制對象,而字符流只能處理字符或字符串; 2. 字節(jié)流提供了處理任何類型的IO操作的功能,但它不能直接處理Unicode字符,而字符流就能夠。
轉(zhuǎn)換:
在從字節(jié)流轉(zhuǎn)化為字符流時,實際上就是byte[]轉(zhuǎn)化為String時,
public String(byte bytes[], String charsetName)
有1個關鍵的參數(shù)字符集編碼,通常我們都省略了,那系統(tǒng)就用操作系統(tǒng)的lang
而在字符流轉(zhuǎn)化為字節(jié)流時,實際上是String轉(zhuǎn)化為byte[]時,
byte[] String.getBytes(String charsetName)
也是1樣的道理
參考鏈接
字節(jié)流與字符流的區(qū)分 - hintcnuie - ITeye技術網(wǎng)站
俺當初學IO的時候犯了很多迷糊,網(wǎng)上有些代碼也沒法通過編譯,乃至風格都很大不同,所以新手請注意:
1.本文代碼較長,不該省略的都沒省略,主要是由于作為1個新手需要養(yǎng)成良好的代碼編寫習慣
2.本文在linux下編譯,類似于File.pathSeparator和File.separator這類表示方法是出于跨平臺性和硬朗性斟酌
3.代碼中有些操作有多種履行方式,我采取了方式1…方式2…的表述,只需輕輕解開注釋即可編譯
4.代碼中并沒有在主方法上拋出異常,而是分別捕捉,造成代碼太長,如果僅是測試,或不想有好的編程習慣,那你就隨意拋吧……
5.功能類似的地方就沒有重復寫注釋了,如果新手看不懂下面的代碼,那肯定是上面的沒有理解清楚
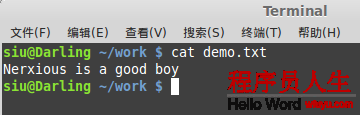
實例1:字符流的寫入
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
//創(chuàng)建要操作的文件路徑和名稱
//其中,F(xiàn)ile.separator表示系統(tǒng)相干的分隔符,Linux下為:/ Windows下為:\\
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
//由于IO操作會拋出異常,因此在try語句塊的外部定義FileWriter的援用
FileWriter w = null;
try {
//以path為路徑創(chuàng)建1個新的FileWriter對象
//如果需要追加數(shù)據(jù),而不是覆蓋,則使用FileWriter(path,true)構造方法
w = new FileWriter(path);
//將字符串寫入到流中,\r\n表示換行想有好的
w.write("Nerxious is a good boy\r\n");
//如果想馬上看到寫入效果,則需要調(diào)用w.flush()方法
w.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
//如果前面產(chǎn)生異常,那末是沒法產(chǎn)生w對象的
//因此要做出判斷,以避免產(chǎn)生空指針異常
if(w != null) {
try {
//關閉流資源,需要再次捕捉異常
w.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
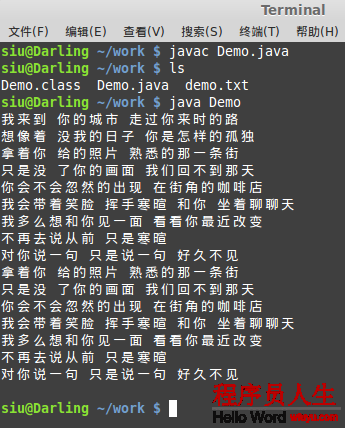
實例2:字符流的讀取
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class Demo2 {
public static void main(String[] args ) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
FileReader r = null;
try {
r = new FileReader(path);
//方式1:讀取單個字符的方式
//每讀取1次,向下移動1個字符單位
int temp1 = r.read();
System.out.println((char)temp1);
int temp2 = r.read();
System.out.println((char)temp2);
//方式2:循環(huán)讀取
//read()方法讀到文件末尾會返回⑴
/*
while (true) {
int temp = r.read();
if (temp == ⑴) {
break;
}
System.out.print((char)temp);
}
*/
//方式3:循環(huán)讀取的簡化操作
//單個字符讀取,當temp不等于⑴的時候打印字符
/*int temp = 0;
while ((temp = r.read()) != ⑴) {
System.out.print((char)temp);
}
*/
//方式4:讀入到字符數(shù)組
/*
char[] buf = new char[1024];
int temp = r.read(buf);
//將數(shù)組轉(zhuǎn)化為字符串打印,后面參數(shù)的意思是
//如果字符數(shù)組未滿,轉(zhuǎn)化成字符串打印后尾部或許會出現(xiàn)其他字符
//因此,讀取的字符有多少個,就轉(zhuǎn)化多少為字符串
System.out.println(new String(buf,0,temp));
*/
//方式5:讀入到字符數(shù)組的優(yōu)化
//由于有時候文件太大,沒法肯定需要定義的數(shù)組大小
//因此1般定義數(shù)組長度為1024,采取循環(huán)的方式讀入
/*
char[] buf = new char[1024];
int temp = 0;
while((temp = r.read(buf)) != ⑴) {
System.out.print(new String(buf,0,temp));
}
*/
} catch (IOException e) {
e.printStackTrace();
} finally {
if(r != null) {
try {
r.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
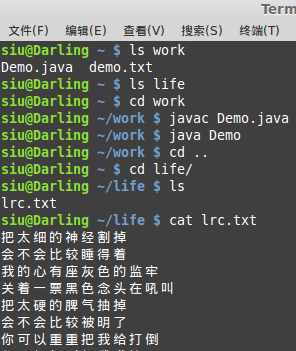
實例3:文本文件的復制
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String doc = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
String copy = File.separator + "home" + File.separator + "siu" +
File.separator + "life" + File.separator + "lrc.txt";
FileReader r = null;
FileWriter w = null;
try {
r = new FileReader(doc);
w = new FileWriter(copy);
//方式1:單個字符寫入
int temp = 0;
while((temp = r.read()) != -1) {
w.write(temp);
}
//方式2:字符數(shù)組方式寫入
/*
char[] buf = new char[1024];
int temp = 0;
while ((temp = r.read(buf)) != ⑴) {
w.write(new String(buf,0,temp));
}
*/
} catch (IOException e) {
e.printStackTrace();
} finally {
//分別判斷是不是空指針援用,然后關閉流
if(r != null) {
try {
r.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(w != null) {
try {
w.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
實例4:利用字符流的緩沖區(qū)來進行文本文件的復制
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String doc = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
String copy = File.separator + "home" + File.separator + "siu" +
File.separator + "life" + File.separator + "lrc.txt";
FileReader r = null;
FileWriter w = null;
//創(chuàng)建緩沖區(qū)的援用
BufferedReader br = null;
BufferedWriter bw = null;
try {
r = new FileReader(doc);
w = new FileWriter(copy);
//創(chuàng)建緩沖區(qū)對象
//將需要提高效力的FileReader和FileWriter對象放入其構造函數(shù)內(nèi)
//固然,也能夠使用匿名對象的方式 br = new BufferedReader(new FileReader(doc));
br = new BufferedReader(r);
bw = new BufferedWriter(w);
String line = null;
//讀取行,直到返回null
//readLine()方法只返回換行符之前的數(shù)據(jù)
while((line = br.readLine()) != null) {
//使用BufferWriter對象的寫入方法
bw.write(line);
//寫完文件內(nèi)容以后換行
//newLine()方法根據(jù)平臺而定
//windows下的換行是\r\n
//Linux下則是\n
bw.newLine();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//此處不再需要捕捉FileReader和FileWriter對象的異常
//關閉緩沖區(qū)就是關閉緩沖區(qū)中的流對象
if(br != null) {
try {
r.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bw != null) {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
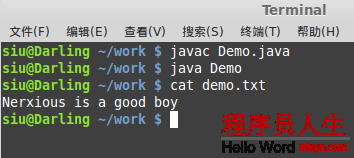
}實例5:字節(jié)流的寫入
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
FileOutputStream o = null;
try {
o = new FileOutputStream(path);
String str = "Nerxious is a good boy\r\n";
byte[] buf = str.getBytes();
//也能夠直接使用o.write("String".getBytes());
//由于字符串就是1個對象,能直接調(diào)用方法
o.write(buf);
} catch (IOException e) {
e.printStackTrace();
} finally {
if(o != null) {
try {
o.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
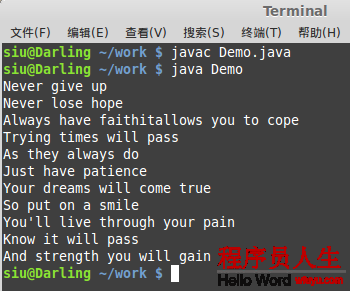
實例6:字節(jié)流的讀取
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
FileInputStream i = null;
try {
i = new FileInputStream(path);
//方式1:單個字符讀取
//需要注意的是,此處我用英文文本測試效果良好
//但中文就悲劇了,不過下面兩個方法效果良好
int ch = 0;
while((ch=i.read()) != -1){
System.out.print((char)ch);
}
//方式2:數(shù)組循環(huán)讀取
/*
byte[] buf = new byte[1024];
int len = 0;
while((len = i.read(buf)) != ⑴) {
System.out.println(new String(buf,0,len));
}
*/
//方式3:標準大小的數(shù)組讀取
/*
//定1個1個恰好大小的數(shù)組
//available()方法返回文件的字節(jié)數(shù)
//但是,如果文件過大,內(nèi)存溢出,那就悲劇了
//所以,親們要慎用!!!上面那個方法就不錯
byte[] buf = new byte[i.available()];
i.read(buf);
//由于數(shù)組大小恰好,所以轉(zhuǎn)換為字符串時無需在構造函數(shù)中設置起始點
System.out.println(new String(buf));
*/
} catch (IOException e) {
e.printStackTrace();
} finally {
if(i != null) {
try {
i.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
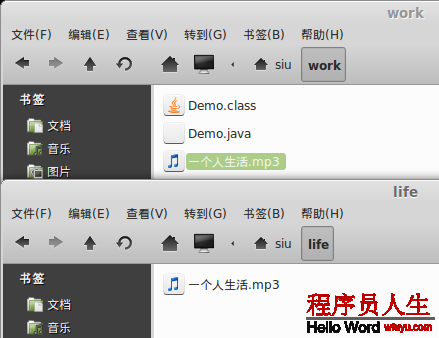
實例7:2進制文件的復制
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String bin = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "1個人生活.mp3";
String copy = File.separator + "home" + File.separator + "siu" +
File.separator + "life" + File.separator + "1個人生活.mp3";
FileInputStream i = null;
FileOutputStream o = null;
try {
i = new FileInputStream(bin);
o = new FileOutputStream(copy);
//循環(huán)的方式讀入寫出文件,從而完成復制
byte[] buf = new byte[1024];
int temp = 0;
while((temp = i.read(buf)) != -1) {
o.write(buf, 0, temp);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if(i != null) {
try {
i.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(o != null) {
try {
o.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
實例8:利用字節(jié)流的緩沖區(qū)進行2進制文件的復制
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args ) {
String bin = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "1個人生活.mp3";
String copy = File.separator + "home" + File.separator + "siu" +
File.separator + "life" + File.separator + "1個人生活.mp3";
FileInputStream i = null;
FileOutputStream o = null;
BufferedInputStream bi = null;
BufferedOutputStream bo = null;
try {
i = new FileInputStream(bin);
o = new FileOutputStream(copy);
bi = new BufferedInputStream(i);
bo = new BufferedOutputStream(o);
byte[] buf = new byte[1024];
int temp = 0;
while((temp = bi.read(buf)) != -1) {
bo.write(buf,0,temp);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if(bi != null) {
try {
i.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bo != null) {
try {
o.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
初學者在學會使用字符流和字節(jié)流以后未免會產(chǎn)生疑問:甚么時候該使用字符流,甚么時候又該使用字節(jié)流呢?
其實仔細想一想就應當知道,所謂字符流,肯定是用于操作類似文本文件或帶有字符文件的場合比較多
而字節(jié)流則是操作那些沒法直接獲得文本信息的2進制文件,比如圖片,mp3,視頻文件等
說白了在硬盤上都是以字節(jié)存儲的,只不過字符流在操作文本上面更方便1點而已
另外,為何要利用緩沖區(qū)呢?
我們知道,像迅雷等下載軟件都有個緩存的功能,硬盤本身也有緩沖區(qū)
試想1下,如果1有數(shù)據(jù),不論大小就開始讀寫,必將會給硬盤造成很大負擔,它會感覺很不爽
人不也1樣,1頓飯不讓你1次吃完,每分鐘喂1勺,你怎樣想?
因此,采取緩沖區(qū)能夠在讀寫大文件的時候有效提高效力
最后解決的1個問題是字節(jié)流和字符流的轉(zhuǎn)化,使用的是InputStreamReader和OutputStreamWriter,它們本身屬于的是reader和writer字符流,我們之所以會用到這些轉(zhuǎn)化流是由于系統(tǒng)有時候只給我們提供了字節(jié)流,為了方便操作,要用到字符流。比如說System.in標準輸入流就是字節(jié)流。你想從那里得到用戶在鍵盤上的輸入,只能是以轉(zhuǎn)換流將它轉(zhuǎn)換為Reader以方便自己的程序讀取輸入。再比如說Socket里的getInputStream()很明顯只給你提供字節(jié)流,你要想讀取字符,就得給他套個InputStreamReader()用來讀取。
package com.zaojiahua.iodemo;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class Test {
public static void main(String[] args) throws IOException {
//字節(jié)流和字符流的相互轉(zhuǎn)化
FileInputStream fileInputStream = new FileInputStream("input.txt");
//inputSreamReader本來就是reader對象,創(chuàng)建的時候需要傳入1個InputStream對象,將字節(jié)流轉(zhuǎn)化為字符流
BufferedReader reader = new BufferedReader(new InputStreamReader(fileInputStream));
//將字符流轉(zhuǎn)化為字節(jié)流
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream("output.txt"));
BufferedWriter writer = new BufferedWriter(outputStreamWriter);
//實現(xiàn)拷貝文件的操作
String buf;
while((buf = reader.readLine()) != null)
{
writer.write(buf);
writer.newLine();
System.out.println(buf);
}
//關閉流
reader.close();
writer.close();
}
}java中的IO操作總結(1) - Nerxious - 博客園
java中的IO操作|皂莢花
Java之美[從菜鳥到高手演化]之Java中的IO - 智慧演繹,無處不在 - 博客頻道 - CSDN.NET

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學習,原版權很多不明,如有侵權請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


