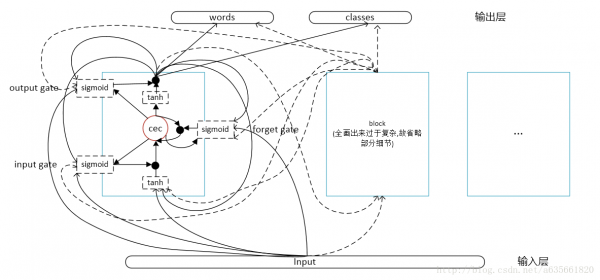
LSTM::LSTM(const int input_dimension,
const int output_dimension,
const int max_batch_size,
const int max_sequence_length,
const bool use_bias)
: Function(input_dimension,
output_dimension,
max_batch_size,
max_sequence_length),
sigmoid_(),
tanh_() {
//這里的1維數(shù)組依然是前面那種類似的結(jié)構(gòu)
int size = output_dimension * max_batch_size * max_sequence_length;
//lstm層的cell的輸出
b_ = FastMalloc(size);
//保存cec的輸入輸出
cec_b_ = FastMalloc(size);
//cell的輸入
cec_input_b_ = FastMalloc(size);
//保存輸入控制門的輸入輸出
input_gate_b_ = FastMalloc(size);
//保存遺忘控制門的輸入輸出
forget_gate_b_ = FastMalloc(size);
//保存輸出控制門的輸入輸出
output_gate_b_ = FastMalloc(size);
//_t_命名類指針都是會變動的,用于表示時間的變化
b_t_ = b_;
cec_input_b_t_ = cec_input_b_;
cec_b_t_ = cec_b_;
input_gate_b_t_ = input_gate_b_;
forget_gate_b_t_ = forget_gate_b_;
output_gate_b_t_ = output_gate_b_;
//這里不明白為啥要重新賦值,上面定義size時不就初始化為這個了嘛
size = output_dimension * max_batch_size * max_sequence_length;
//output gate的誤差信號
cec_epsilon_ = FastMalloc(size);
delta_ = FastMalloc(size);
//輸入控制門的誤差
input_gate_delta_ = FastMalloc(size);
//遺忘控制門的誤差
forget_gate_delta_ = FastMalloc(size);
//輸出控制門的誤差
output_gate_delta_ = FastMalloc(size);
//這里同上
cec_epsilon_t_ = cec_epsilon_;
delta_t_ = delta_;
input_gate_delta_t_ = input_gate_delta_;
forget_gate_delta_t_ = forget_gate_delta_;
output_gate_delta_t_ = output_gate_delta_;
//std::cout << "input_dimension: " << input_dimension << " output_dimension: " << output_dimension << std::endl;
//假定命令是myExample-i10-M12
//這里的input_dimension就是10,output_dimension就是12
size = input_dimension * output_dimension;
//這里的權(quán)值僅僅是輸入層到該lstm層的
weights_ = FastMalloc(size);
//下面控制門的權(quán)重僅僅是輸入層到控制門的
input_gate_weights_ = FastMalloc(size);
forget_gate_weights_ = FastMalloc(size);
output_gate_weights_ = FastMalloc(size);
momentum_weights_ = FastMalloc(size);
momentum_input_gate_weights_ = FastMalloc(size);
momentum_forget_gate_weights_ = FastMalloc(size);
momentum_output_gate_weights_ = FastMalloc(size);
//這部份權(quán)重是循環(huán)結(jié)構(gòu)的,即前1時刻lstm層到當前時刻lstm層的連接
size = output_dimension * output_dimension;
recurrent_weights_ = FastMalloc(size);
input_gate_recurrent_weights_ = FastMalloc(size);
forget_gate_recurrent_weights_ = FastMalloc(size);
output_gate_recurrent_weights_ = FastMalloc(size);
momentum_recurrent_weights_ = FastMalloc(size);
momentum_input_gate_recurrent_weights_ = FastMalloc(size);
momentum_forget_gate_recurrent_weights_ = FastMalloc(size);
momentum_output_gate_recurrent_weights_ = FastMalloc(size);
//從上面的分配來看,容易知道控制門的輸入來自于3部份: 1.輸入層的輸出 2.本層的前1時刻輸出 3.來自cec狀態(tài)的前1時刻輸出
//lstm層的輸入自于這兩部份:1.輸入層的輸出 2.本層的前1時刻輸出
//peephole connection,這是從cec到gate的連接
input_gate_peephole_weights_ = FastMalloc(output_dimension);
forget_gate_peephole_weights_ = FastMalloc(output_dimension);
output_gate_peephole_weights_ = FastMalloc(output_dimension);
momentum_input_gate_peephole_weights_ = FastMalloc(output_dimension);
momentum_forget_gate_peephole_weights_ = FastMalloc(output_dimension);
momentum_output_gate_peephole_weights_ = FastMalloc(output_dimension);
//從這里的分配來看,能夠知道lstm層內(nèi)部的結(jié)構(gòu):
//output_dimension的大小即是block的大小,每一個block大小包括1個cell,1個cell里面包括1個cec
//即output_dimension的大小就是cec個數(shù),每一個cec與3個gate連接
//bias的設(shè)置
bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
input_gate_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
forget_gate_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
output_gate_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
momentum_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
momentum_input_gate_bias_ = use_bias ?
FastMalloc(output_dimension) : nullptr;
momentum_forget_gate_bias_ = use_bias ?
FastMalloc(output_dimension) : nullptr;
momentum_output_gate_bias_ = use_bias ?
FastMalloc(output_dimension) : nullptr;
}
const Real *LSTM::Evaluate(const Slice &slice, const Real x[]) {
//形參x依然表示前層的輸入
//start為真表示起始時刻
const bool start = b_t_ == b_;
//OpenMP提供的并行功能
//下面兩個section同時并行
#pragma omp parallel sections
{
//在帶有peephole connection的lstm結(jié)構(gòu)中,前向計算的順序有要求
//1.先必須計算input gate和forget gate的輸出
//2.計算cell輸入和cec的狀態(tài)
//3.計算output gate的輸出
//4.計算cell的輸出
#pragma omp section
//注意這里start的作用,起始時刻時,gate輸入本來是包括peephole前1時刻cec的輸出,和前1時刻層的輸入兩部份的
//但由于起始時刻,它們⑴時刻的輸出狀態(tài)相當于0,這里不做計算
//只有t>0,即非起始時刻后,才會有前1時刻的輸出
//計算input gate的輸出
EvaluateSubUnit(slice.size(),
input_gate_weights_,
input_gate_bias_,
start ? nullptr : input_gate_recurrent_weights_,
start ? nullptr : input_gate_peephole_weights_,
x,
b_t_ - GetOffset(),
cec_b_t_ - GetOffset(),
input_gate_b_t_,
&sigmoid_);
#pragma omp section
//計算forget的輸出
EvaluateSubUnit(slice.size(),
forget_gate_weights_,
forget_gate_bias_,
start ? nullptr : forget_gate_recurrent_weights_,
start ? nullptr : forget_gate_peephole_weights_,
x,
b_t_ - GetOffset(),
cec_b_t_ - GetOffset(),
forget_gate_b_t_,
&sigmoid_);
}
//計算cell的輸入,它的輸入來自于兩部份,1部份是輸入層,1部份是前1時刻本層的輸出
EvaluateSubUnit(slice.size(),
weights_,
bias_,
start ? nullptr : recurrent_weights_,
nullptr,
x,
b_t_ - GetOffset(),
nullptr,
cec_input_b_t_,
&tanh_);
const int size = slice.size() * output_dimension();
//cec_b_t_ <= cec_input_b_t_ * input_gate_b_t_
//計算cec的輸入
FastMultiply(input_gate_b_t_, size, cec_input_b_t_, cec_b_t_);
//非起始時刻履行,這里這樣限制的緣由是cec的輸入來自于cell輸入的1部份,還有cec前1狀態(tài)的輸出
//如果并不是起始時刻,是不存在cec前1狀態(tài)的輸出的
//另外要注意,cec的結(jié)構(gòu)是線性的,即為了保證誤差的常數(shù)流,激活函數(shù)用的是f(x) = x
//所以計算cec的輸入后,自然也是它的輸出
if (!start) {
//cec_b_t_ <= cec_b_t_ + forget_gate_b_t_*cec_b_(t⑴)_
FastMultiplyAdd(forget_gate_b_t_,
size,
cec_b_t_ - GetOffset(),
cec_b_t_);
}
//計算output gate的輸出
EvaluateSubUnit(slice.size(),
output_gate_weights_,
output_gate_bias_,
start ? nullptr : output_gate_recurrent_weights_,
output_gate_peephole_weights_,
x,
b_t_ - GetOffset(),
cec_b_t_,
output_gate_b_t_,
&sigmoid_);
//這里將cec的輸出拷貝到b_t_上了
FastCopy(cec_b_t_, size, b_t_);
//cec的輸出經(jīng)過tanh函數(shù)的緊縮
tanh_.Evaluate(output_dimension(), slice.size(), b_t_);
//現(xiàn)在b_t_是全部cell的輸出
FastMultiply(b_t_, size, output_gate_b_t_, b_t_);
const Real *result = b_t_;
b_t_ += GetOffset();
cec_input_b_t_ += GetOffset();
cec_b_t_ += GetOffset();
input_gate_b_t_ += GetOffset();
forget_gate_b_t_ += GetOffset();
output_gate_b_t_ += GetOffset();
return result;
}
//該函數(shù)是計算lstm層的輸出
void LSTM::EvaluateSubUnit(const int batch_size,
const Real weights[],
const Real bias[],
const Real recurrent_weights[],
const Real peephole_weights[],
const Real x[],
const Real recurrent_b_t[],
const Real cec_b_t[],
Real b_t[],
ActivationFunction *activation_function) {
//存在偏置,復制過去,在下次計算時就相當于把偏置加上去了
if (bias) {
for (int i = 0; i < batch_size; ++i)
FastCopy(bias, output_dimension(), b_t + i * output_dimension());
}
//b_t <= b_t + weights * x
//這里計算層的輸入
FastMatrixMatrixMultiply(1.0,
weights,
false,
output_dimension(),
input_dimension(),
x,
false,
batch_size,
b_t);
//非起始時刻
//b_t <= b_t + recurrent_weights * recurrent_b_t
//這部份層的輸入來自上1時刻層的輸出乘以recurrent_weights
if (recurrent_weights) {
FastMatrixMatrixMultiply(1.0,
recurrent_weights,
false,
output_dimension(),
output_dimension(),
recurrent_b_t,
false,
batch_size,
b_t);
}
//非起始時刻
if (peephole_weights) {
#pragma omp parallel for
for (int i = 0; i < batch_size; ++i) {
//b_t <= b_t + peephole_weights * cec_b_t
//這里gate的輸入來自于cec的部份
FastMultiplyAdd(peephole_weights,
output_dimension(),
cec_b_t + i * output_dimension(),
b_t + i * output_dimension());
}
}
//上面計算的b_t_都是輸入,下面這步后經(jīng)過了相應激活函數(shù),變成了輸出
activation_function->Evaluate(output_dimension(), batch_size, b_t);
}
void LSTM::ComputeDelta(const Slice &slice, FunctionPointer f) {
//從時刻t到0
b_t_ -= GetOffset();
cec_input_b_t_ -= GetOffset();
cec_b_t_ -= GetOffset();
input_gate_b_t_ -= GetOffset();
forget_gate_b_t_ -= GetOffset();
output_gate_b_t_ -= GetOffset();
// cell outputs
//計算輸出層傳到lstm層的誤差delta_t_
f->AddDelta(slice, delta_t_);
//并不是句子末尾,如果當前時刻為t,要存在t+1時刻的相干計算
if (delta_t_ != delta_) {
//delta_t_ <= delta_t_ + recurrent_weights_ * delta_(t+1)_
//即計算t+1時刻lstm層的誤差傳到t時刻該層的誤差
FastMatrixMatrixMultiply(1.0,
recurrent_weights_,
true,
output_dimension(),
output_dimension(),
delta_t_ - GetOffset(),
false,
slice.size(),
delta_t_);
//delta_t_ <= delta_t_ + input_gate_recurrent_weights_ * input_gate_delta_(t⑴)_
//input gate在t+1時刻的誤差傳到t時刻該層
FastMatrixMatrixMultiply(1.0,
input_gate_recurrent_weights_,
true,
output_dimension(),
output_dimension(),
input_gate_delta_t_ - GetOffset(),
false,
slice.size(),
delta_t_);
//delta_t_ <= delta_t_ + forget_gate_recurrent_weights_ * forget_gate_delta_(t⑴)_
//forget gate在t+1時刻的誤差傳到t時刻該層
FastMatrixMatrixMultiply(1.0,
forget_gate_recurrent_weights_,
true,
output_dimension(),
output_dimension(),
forget_gate_delta_t_ - GetOffset(),
false,
slice.size(),
delta_t_);
//delta_t_ <= delta_t_ + output_gate_recurrent_weights_ * output_gate_delta_(t⑴)_
//output gate在t+1時刻的誤差傳到t時刻該層
FastMatrixMatrixMultiply(1.0,
output_gate_recurrent_weights_,
true,
output_dimension(),
output_dimension(),
output_gate_delta_t_ - GetOffset(),
false,
slice.size(),
delta_t_);
}
//到這里delta_t_表示到達lstm層的誤差,如果記L為目標函數(shù),b為lstm層cell的輸出
//現(xiàn)在delta_t_寄存的是?L/?b
// output gates, part I
const int size = slice.size() * output_dimension();
//將cec的輸出復制到output_gate_delta_t_
FastCopy(cec_b_t_, size, output_gate_delta_t_);
//cec的輸出經(jīng)過tanh函數(shù),依然寄存到output_gate_delta_t_
tanh_.Evaluate(output_dimension(), slice.size(), output_gate_delta_t_);
// states, part I
//cec_epsilon_t_ <= output_gate_b_t_ * delta_t_
//這行語句是計算到達輸出控制門那兒的激活函數(shù)前的誤差
FastMultiply(output_gate_b_t_, size, delta_t_, cec_epsilon_t_);
//下面計算的是到達cec的誤差,寄存在cec_epsilon_t_,這只是流向cec誤差的其中1部份
tanh_.MultiplyDerivative(output_dimension(),
slice.size(),
output_gate_delta_t_,
cec_epsilon_t_);
// output gates, part II
//output_gate_delta_t_ <= output_gate_delta_t_ * delta_t_
//這行語句是計算到達output gate的誤差
FastMultiply(output_gate_delta_t_,
size,
delta_t_,
output_gate_delta_t_);
//下面計算的是output gate的誤差信號,寄存在output_gate_delta_t_
sigmoid_.MultiplyDerivative(output_dimension(),
slice.size(),
output_gate_b_t_,
output_gate_delta_t_);
// states, part II
#pragma omp parallel for
for (int i = 0; i < (int) slice.size(); ++i) {
//cec_epsilon_t_ <= cec_epsilon_t_ + output_gate_peephole_weights_ * output_gate_delta_t_
//這部份是output gate的誤差信號流過來的
FastMultiplyAdd(output_gate_peephole_weights_,
output_dimension(),
output_gate_delta_t_ + i * output_dimension(),
cec_epsilon_t_ + i * output_dimension());
}
//即非最末時刻
if (delta_t_ != delta_) {
//cec_epsilon_t_ <= cec_epsilon_t_ + forget_gate_b_(t+1)_ * cec_epsilon_(t+1)_
//這部份是從cec的t+1時刻那兒流過來的誤差
FastMultiplyAdd(forget_gate_b_t_ + GetOffset(),
size,
cec_epsilon_t_ - GetOffset(),
cec_epsilon_t_);
#pragma omp parallel for
for (int i = 0; i < (int) slice.size(); ++i) {
//cec_epsilon_t_ <= cec_epsilon_t_ + input_gate_peephole_weights_ * input_gate_delta_(t+1)_
//從input gate那兒流過來的誤差
FastMultiplyAdd(input_gate_peephole_weights_,
output_dimension(),
input_gate_delta_t_ - GetOffset() + i * output_dimension(),
cec_epsilon_t_ + i * output_dimension());
//從forget gate那兒流過來的誤差
FastMultiplyAdd(
forget_gate_peephole_weights_,
output_dimension(),
forget_gate_delta_t_ - GetOffset() + i * output_dimension(),
cec_epsilon_t_ + i * output_dimension());
}
}
// cells
//delta_t_ <= input_gate_b_t_ * cec_epsilon_t_
//下面兩句計算cell輸入處的誤差信號
FastMultiply(input_gate_b_t_, size, cec_epsilon_t_, delta_t_);
tanh_.MultiplyDerivative(output_dimension(),
slice.size(),
cec_input_b_t_,
delta_t_);
//到現(xiàn)在delta_t_表示cell輸入處的誤差信號
#pragma omp parallel sections
{
#pragma omp section
{
// forget gates
if (b_t_ != b_) {
//forget_gate_delta_t_ <= cec_epsilon_t_ * cec_b_(t⑴)_
//流向forget gate的誤差
FastMultiply(cec_b_t_ - GetOffset(),
size,
cec_epsilon_t_,
forget_gate_delta_t_);
//計算forget gate的誤差信號
sigmoid_.MultiplyDerivative(output_dimension(),
slice.size(),
forget_gate_b_t_,
forget_gate_delta_t_);
}
}
#pragma omp section
{
// input gates
//input_gate_delta_t_ <= cec_epsilon_t_ * cec_input_b_t_
//流向input gate的誤差
FastMultiply(cec_epsilon_t_,
size,
cec_input_b_t_,
input_gate_delta_t_);
//計算input gate的誤差信號
sigmoid_.MultiplyDerivative(output_dimension(),
slice.size(),
input_gate_b_t_,
input_gate_delta_t_);
}
}
}
//計算流向輸入層的誤差
void LSTM::AddDelta(const Slice &slice, Real delta_t[]) {
//delta_t <= delta_t + weights_ * delta_t_
//這里cell輸入處的誤差信號,流向輸入層
FastMatrixMatrixMultiply(1.0,
weights_,
true,
input_dimension(),
output_dimension(),
delta_t_,
false,
slice.size(),
delta_t);
//delta_t <= input_gate_delta_t_ * input_gate_weights_ + delta_t
//input gate的誤差信號流向輸入層部份
FastMatrixMatrixMultiply(1.0,
input_gate_weights_,
true,
input_dimension(),
output_dimension(),
input_gate_delta_t_,
false,
slice.size(),
delta_t);
//delta_t <= forget_gate_delta_t_ * forget_gate_weights_ + delta_t
//forget gate的誤差信號流向輸入層部份
FastMatrixMatrixMultiply(1.0,
forget_gate_weights_,
true,
input_dimension(),
output_dimension(),
forget_gate_delta_t_,
false,
slice.size(),
delta_t);
//delta_t <= output_gate_delta_t_ * output_gate_weights_ + delta_t
//output gate的誤差信號流向輸入層部份
FastMatrixMatrixMultiply(1.0,
output_gate_weights_,
true,
input_dimension(),
output_dimension(),
output_gate_delta_t_,
false,
slice.size(),
delta_t);
//t+1時刻 -> t時刻
cec_epsilon_t_ += GetOffset();
delta_t_ += GetOffset();
input_gate_delta_t_ += GetOffset();
forget_gate_delta_t_ += GetOffset();
output_gate_delta_t_ += GetOffset();
}
const Real *LSTM::UpdateWeights(const Slice &slice,
const Real learning_rate,
const Real x[]) {
const int size = slice.size() * output_dimension();
//0到末尾時刻
cec_epsilon_t_ -= GetOffset();
delta_t_ -= GetOffset();
input_gate_delta_t_ -= GetOffset();
forget_gate_delta_t_ -= GetOffset();
output_gate_delta_t_ -= GetOffset();
#pragma omp parallel sections
{
#pragma omp section
{
if (bias_) {
for (size_t i = 0; i < slice.size(); ++i) {
//momentum_bias_ <= -learning_rate*delta_t_ + momentum_bias_
//這是對cell的bias的改變量累加
FastMultiplyByConstantAdd(-learning_rate,
delta_t_ + i * output_dimension(),
output_dimension(),
momentum_bias_);
}
}
}
#pragma omp section
{
if (input_gate_bias_) {
//momentum_input_gate_bias_ <= -learning_rate*input_gate_delta_t_ + momentum_input_gate_bias_
//這是對input gate的bias改變量累加
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyByConstantAdd(-learning_rate,
input_gate_delta_t_ + i * output_dimension(),
output_dimension(),
momentum_input_gate_bias_);
}
}
}
#pragma omp section
{
//momentum_forget_gate_bias_ <= -learning_rate*forget_gate_delta_t_ + momentum_forget_gate_bias_
//這是對 forget gate的bias改變量累加
if (forget_gate_bias_) {
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyByConstantAdd(-learning_rate,
forget_gate_delta_t_ + i * output_dimension(),
output_dimension(),
momentum_forget_gate_bias_);
}
}
}
#pragma omp section
{
//momentum_output_gate_bias_ <= -learning_rate*output_gate_delta_t_ + momentum_output_gate_bias_
//這是對 output gate的bias改變量累加
if (output_gate_bias_) {
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyByConstantAdd(-learning_rate,
output_gate_delta_t_ + i * output_dimension(),
output_dimension(),
momentum_output_gate_bias_);
}
}
}
//以上部份是計算各個bias的改變量,但并未真正改變bias
#pragma omp section
{
//momentum_weights_ <= -learning_rate * delta_t_ * x + momentum_weights_
//這是計算輸入層到lstm層權(quán)重的改變量
FastMatrixMatrixMultiply(-learning_rate,
delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_weights_);
}
#pragma omp section
{
//momentum_input_gate_weights_<= -learning_rate * input_gate_delta_t_ * x + momentum_input_gate_weights_
//這是計算輸入層到 input gate 權(quán)重的改變量
FastMatrixMatrixMultiply(-learning_rate,
input_gate_delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_input_gate_weights_);
}
#pragma omp section
{
//momentum_forget_gate_weights_<= -learning_rate * forget_gate_delta_t_ * x + momentum_forget_gate_weights_
//這是計算輸入層到 forget gate 權(quán)重的改變量
FastMatrixMatrixMultiply(-learning_rate,
forget_gate_delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_forget_gate_weights_);
}
#pragma omp section
{
//momentum_output_gate_weights_<= -learning_rate * output_gate_delta_t_ * x + momentum_output_gate_weights_
//這是計算輸入層到 output gate 權(quán)重的改變量
FastMatrixMatrixMultiply(-learning_rate,
output_gate_delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_output_gate_weights_);
}
#pragma omp section
{
//momentum_recurrent_weights_<= -learning_rate * delta_t_ * b_(t⑴)_ + momentum_recurrent_weights_
//這是計算t⑴時刻lstm層到 t時刻本身權(quán)重的改變量
if (b_t_ != b_) {
FastMatrixMatrixMultiply(-learning_rate,
delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_recurrent_weights_);
}
}
#pragma omp section
{
//momentum_input_gate_recurrent_weights_<= -learning_rate * input_gate_delta_t_ * b_(t⑴)_ + momentum_input_gate_recurrent_weights_
//這是計算t⑴時刻lstm層到 t時刻 input gate權(quán)重的改變量
if (b_t_ != b_) {
FastMatrixMatrixMultiply(-learning_rate,
input_gate_delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_input_gate_recurrent_weights_);
}
}
#pragma omp section
{
//momentum_forget_gate_recurrent_weights_<= -learning_rate * forget_gate_delta_t_ * b_(t⑴)_ + momentum_forget_gate_recurrent_weights_
//這是計算t⑴時刻lstm層到 t時刻 forget gate權(quán)重的改變量
if (b_t_ != b_) {
FastMatrixMatrixMultiply(-learning_rate,
forget_gate_delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_forget_gate_recurrent_weights_);
}
}
#pragma omp section
{
//momentum_output_gate_recurrent_weights_<= -learning_rate * output_gate_delta_t_ * b_(t⑴)_ + momentum_output_gate_recurrent_weights_
//這是計算t⑴時刻lstm層到 t時刻 output gate權(quán)重的改變量
if (b_t_ != b_) {
FastMatrixMatrixMultiply(-learning_rate,
output_gate_delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_output_gate_recurrent_weights_);
}
}
//注意上面改變分為3部份:1.計算bias的改變量 2.計算輸入層到cell各部份的權(quán)值改變量 3.計算t⑴時刻cell到t時刻cell各部份權(quán)重改變量
}
#pragma omp parallel sections
{
#pragma omp section
{
if (b_t_ != b_) {
// destroys ..._gate_delta_t_, but this will not be used later anyway
//input_gate_delta_t_ <= -learning_rate*input_gate_delta_t_
//下面計算后,就破壞了input gate的誤差信號值了,不過后面也不會再使用了。
FastMultiplyByConstant(input_gate_delta_t_,
size,
-learning_rate,
input_gate_delta_t_);
for (size_t i = 0; i < slice.size(); ++i) {
//momentum_input_gate_peephole_weights_ <= momentum_input_gate_peephole_weights_ + input_gate_delta_t_ * cec_b_(t⑴)_
//計算 input gate到cec的權(quán)值改變量
FastMultiplyAdd(input_gate_delta_t_ + i * output_dimension(),
output_dimension(),
cec_b_t_ - GetOffset() + i * output_dimension(),
momentum_input_gate_peephole_weights_);
}
}
}
#pragma omp section
{
if (b_t_ != b_) {
//forget_gate_delta_t_ <= -learning_rate*forget_gate_delta_t_
FastMultiplyByConstant(forget_gate_delta_t_,
size,
-learning_rate,
forget_gate_delta_t_);
//momentum_forget_gate_peephole_weights_ <= momentum_forget_gate_peephole_weights_ + forget_gate_delta_t_ * cec_b_(t⑴)_
//計算 forget gate到cec的權(quán)值改變量
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyAdd(forget_gate_delta_t_ + i * output_dimension(),
output_dimension(),
cec_b_t_ - GetOffset() + i * output_dimension(),
momentum_forget_gate_peephole_weights_);
}
}
}
#pragma omp section
{
//output_gate_delta_t_ <= -learning_rate*output_gate_delta_t_
FastMultiplyByConstant(output_gate_delta_t_,
size,
-learning_rate,
output_gate_delta_t_);
//momentum_output_gate_peephole_weights_ <= momentum_output_gate_peephole_weights_ + output_gate_delta_t_ * cec_b_(t⑴)_
//計算 forget gate到cec的權(quán)值改變量
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyAdd(output_gate_delta_t_ + i * output_dimension(),
output_dimension(),
cec_b_t_ + i * output_dimension(),
momentum_output_gate_peephole_weights_);
}
}
}
const Real *result = b_t_;
// let b_t_ point to next time step
//朝下1個時刻走
b_t_ += GetOffset();
cec_input_b_t_ += GetOffset();
cec_b_t_ += GetOffset();
input_gate_b_t_ += GetOffset();
forget_gate_b_t_ += GetOffset();
output_gate_b_t_ += GetOffset();
return result;
}