
在介紹GC之前有必要先了解1下JVM的內(nèi)存劃分,這樣在后面介紹GC和各種不同的GC collector的時(shí)候更容易理解。
下面這張圖是“偷”的他人的,很經(jīng)典的描寫了jvm的體系結(jié)構(gòu),我們只需要關(guān)注最大的那1塊――運(yùn)行時(shí)數(shù)據(jù)區(qū)域。
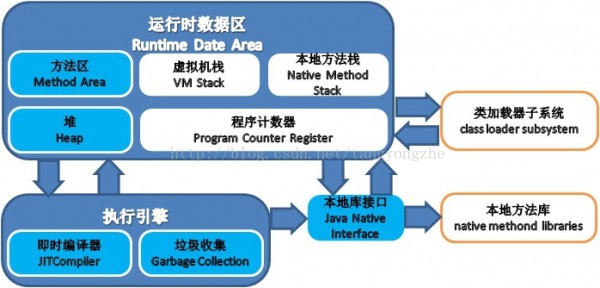
運(yùn)行時(shí)區(qū)顧名思義是jvm在運(yùn)行時(shí)的內(nèi)存結(jié)構(gòu),主要有以下5種。
1.方法區(qū)
方法區(qū)是各個(gè)線程同享的1塊內(nèi)存區(qū)域,當(dāng)虛擬機(jī)裝載1個(gè)class文件時(shí),它會從2進(jìn)制數(shù)據(jù)中解析類型的信息,這些信息便是存儲在方法區(qū),包括類的靜態(tài)變量也會存儲到該區(qū)域。虛擬機(jī)規(guī)范把該區(qū)域劃分為堆的1部份,但是實(shí)際上它還有個(gè)別名Non-Heap,很明顯是用來和堆做辨別的。在討論GC時(shí)我們習(xí)慣把這個(gè)區(qū)域叫做永久代,本質(zhì)上它倆不是1個(gè)概念,對HotSpot來講,永久代僅僅是實(shí)現(xiàn)方法區(qū)的1種方式。并且HotSpot后續(xù)的版本計(jì)劃移除永久代,如果該區(qū)域內(nèi)存不足時(shí),會產(chǎn)生OOM。
2.堆
堆和方法區(qū)1樣也是各個(gè)線程同享的1塊內(nèi)存區(qū)域,所有的對象實(shí)例包括數(shù)組都在這里分配內(nèi)存。比如當(dāng)我們new Object()的時(shí)候便是在這里分配的內(nèi)存,java堆可以說是jvm管理的最大的1塊內(nèi)存區(qū)域,需要注意的1點(diǎn)是和方法區(qū)1樣jvm規(guī)范并沒有要求堆是連續(xù)的,jvm可以在運(yùn)行時(shí)動態(tài)的擴(kuò)大和收縮堆。為了更好的實(shí)現(xiàn)GC,現(xiàn)代的jvm針對堆又做了細(xì)化,將1整塊堆分成不同的區(qū)域。下面這張圖來自oracle官方網(wǎng)站,詳細(xì)的畫出了堆的詳細(xì)情況。
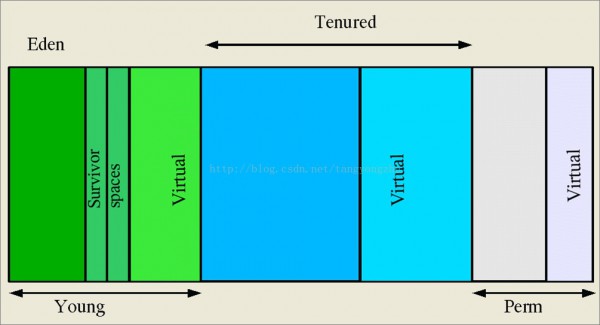
圖倒是蠻大的- -,還是橫著的,湊合著看吧,全部堆分為3個(gè)區(qū)域,Young區(qū)、Tenured區(qū)(也就是Old區(qū))、Perm區(qū),習(xí)慣上我們稱為年輕代,年老代,永久代(實(shí)際上GC就是依照這3個(gè)代進(jìn)行分代搜集的)。仔細(xì)的朋友可能會注意到每一個(gè)區(qū)域都有1塊virtual,有必要說明1下virtual是做甚么,我們知道堆可以在運(yùn)行時(shí)擴(kuò)充,比如在配置虛擬機(jī)參數(shù)的時(shí)候通常會指定-Xmx,-Xms最大堆和初始堆,這里的virtual就是預(yù)留的內(nèi)存區(qū)域,其值為最大堆減去初始堆的值,實(shí)際上操作系統(tǒng)1開始就會劃分-Xmx大小的內(nèi)存給jvm,只不過jvm1開始可能不需要那末大的空間,因此jvm將1部份內(nèi)存標(biāo)記為virtual區(qū),留著后面擴(kuò)大用。3種內(nèi)存區(qū)域中Young區(qū)略微復(fù)雜些,這里又分為3個(gè)區(qū)域分別為1個(gè)Eden和兩個(gè)Survivor區(qū)(1個(gè)to survivor1個(gè)from survivor),名字很成心思,1個(gè)是伊甸園1個(gè)是幸存區(qū),關(guān)于這幾個(gè)區(qū)具體寄存的是甚么后面做進(jìn)1步解釋。
3.虛擬機(jī)棧
虛擬機(jī)棧為線程私有,因此處于這個(gè)區(qū)域的值不需要斟酌并發(fā)的問題。jvm為每一個(gè)java線程都分配1個(gè)棧,為該線程私有,棧內(nèi)存隨著線程的燒毀而釋放。jvm為每一個(gè)方法都會生成1個(gè)棧幀用于保存局部變量表,操作數(shù)棧(這些概念在我之前的博客中也提到過)等信息。基本類型和對象的援用都可以在棧中存儲。該區(qū)域有可能拋出StackOverflowerror和OOM異常。
4.本地方法棧
本地方法棧類似虛擬機(jī)棧,只不過虛擬機(jī)棧是為java方法服務(wù),本地方法棧為本地的Native方法服務(wù)。
5.程序計(jì)數(shù)器
程序計(jì)數(shù)器是1塊非常小的內(nèi)存區(qū)域,它是當(dāng)前線程履行的字節(jié)碼的行號唆使器,總是指向下1個(gè)要履行的指令,該區(qū)域是唯1不會產(chǎn)生OOM的內(nèi)存區(qū)。
上面說過虛擬機(jī)棧,本地方法棧和程序計(jì)數(shù)器它們的內(nèi)存分配在編譯期基本就能夠肯定,并且內(nèi)存隨著線程的方法結(jié)束或線程結(jié)束而燒毀,因此這部份內(nèi)存不需要斟酌回收的問題。堆和方法區(qū)的內(nèi)存分配相比來講就具有了不肯定性,而且這部份的內(nèi)存分配和回收都是動態(tài)的,因此jvm需要針對這兩塊內(nèi)存做GC。
趁熱打鐵,剛剛講完堆的分代,正好來看下為何要分代和各個(gè)代中存儲的對象有何不同。
之所以要分代很明顯的1個(gè)緣由是方便做垃圾搜集,由于垃圾搜集只是針對那些沒有被援用的孤對象進(jìn)行的,而研究表明java中大多數(shù)的對象都是短命的,但也有1些對象存活的時(shí)間比較長。因此為了針對這些生命不1的對象做搜集,將堆劃分為不同的代來寄存這些對象,也就是說Young區(qū)中的對象都是比較“年輕的”,同理可理解Old區(qū)。這就是為何叫做Young和Old的緣由。
實(shí)際上GC其實(shí)不是java獨(dú)有的,GC的歷史要比java悠久。關(guān)于GC的基本原理比如援用計(jì)數(shù)法,可達(dá)性分析法等等就不作介紹了。GC主要有兩種,1種是minor gc另外一種是major gc也有稱為young gc和old gc的。minor gc產(chǎn)生在Young區(qū),并且時(shí)間通常非常短,major gc產(chǎn)生在Old區(qū),時(shí)間較長,需要控制major gc的次數(shù)和GC時(shí)間。
jvm依照對象存活的時(shí)間,給對象1個(gè)類似我們?nèi)祟悺澳挲g的概念”,實(shí)際上每經(jīng)過1次GC,存活下來的對象年齡便+1,大多數(shù)情況下對象優(yōu)先分配到Eden區(qū),這就是為何這里叫Eden區(qū)的緣由,當(dāng)Eden區(qū)的沒有足夠內(nèi)存分配的時(shí)候,便會觸發(fā)1次Minor GC。此時(shí)存活下來的對象年齡+1,當(dāng)?shù)竭_(dá)1定年齡的時(shí)候,表明該對象存活比較穩(wěn)定,會把該部份對象移到年老代(我們可以通過參數(shù)-XX:MaxTenuringThreshold 控制經(jīng)過量少次Minor gc后便進(jìn)入old區(qū),默許為15),如果在Minor GC的時(shí)候發(fā)現(xiàn)to survivor寄存不下這些對象,則會直接寄存到年老代。需要注意的1點(diǎn)是當(dāng)要分配大對象(比如數(shù)組和長字符串)的時(shí)候,也是直接將他們分配到年老代的,因此我們盡可能避免大對象特別是短命大對象的使用,由于這很容易引發(fā)old區(qū)的內(nèi)存不夠分配,從而提早觸發(fā)full gc。當(dāng)年老代沒有足夠內(nèi)存的時(shí)候便會觸發(fā)Major GC,通常minor gc的時(shí)間非常短對程序影響可以疏忽,但是major gc的進(jìn)程則要比minor gc長很多,因此要盡可能避免major gc的產(chǎn)生(當(dāng)產(chǎn)生gc的時(shí)候會暫停所有的利用線程履行,官方稱為stop the world,這里的時(shí)間指的就是stop the world的時(shí)間)。
來看1下目前幾種主要的GC算法,之所以這些算法并存是由于針對不同的區(qū)域通常需要使用特定的算法。
1.標(biāo)記-清除
很明顯該算法分為兩步,第1步是標(biāo)記出需要回收的對象,第2步針對這些對象做清算動作。該算法的缺點(diǎn)主要有兩個(gè):1是效力問題,標(biāo)記和清除的效力都不高,2是清除以后會產(chǎn)生大量不連續(xù)的內(nèi)存碎片,這會致使運(yùn)行進(jìn)程中如果需要分配較大的對象,會由于找不到足夠的連續(xù)內(nèi)存而提早觸發(fā)1次垃圾搜集。
2.復(fù)制算法
復(fù)制算法將內(nèi)存分為大小相等的兩塊,每次使用1塊,當(dāng)1塊使用完時(shí),將還存活的對象全部復(fù)制到另外一塊區(qū)域中,然后清算第1塊的內(nèi)存,該算法的好處不言而喻,不會產(chǎn)生內(nèi)存碎片,但是只使用1塊內(nèi)存未免代價(jià)太大,并且在存活對象非常多的時(shí)候,效力肯定會低下。實(shí)際上在java中絕大多數(shù)的對象都是“短命的”,因此不需要依照1:1來劃份內(nèi)存,HotSpot默許將Eden區(qū)和兩個(gè)survivor區(qū)依照8:2的比例進(jìn)行劃分,也就是Eden:survivor=8:1(固然我們可以通過-XX:SurvivorRatio設(shè)置Survivor的大小,該值如果為8,則表示Eden區(qū)占Young的10分之8,兩個(gè)Survivor占Young區(qū)的10分之2),該算法非常合適在minor gc時(shí)使用。
3.標(biāo)記-整理
復(fù)制算法針對有大量存活的對象時(shí)效力低下,因此不合適對年老代的回收,但是標(biāo)記清除又有碎片的問題,因此產(chǎn)生了標(biāo)記整理算法。標(biāo)記整理算法和標(biāo)記清除算法類似,第1步都是標(biāo)記,而第2步整理階段是將存活的對象移向1端,然后直接清算邊界之外的內(nèi)存,這樣不會產(chǎn)生碎片效力也不算太差。
針對上面幾種算法,HotSpot主要提供了以下幾種實(shí)現(xiàn):
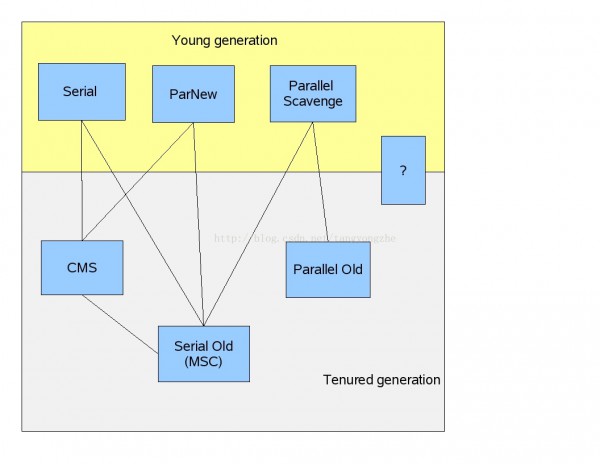
圖中黃色背景是年輕代的搜集器,淺灰色背景是年老代的搜集器,藍(lán)色背景表示垃圾搜集器,兩兩直線相連表示兩種搜集器可以共用。下面分別介紹1下這6種搜集器:
1."Serial"會引發(fā)stop the world,基于拷貝的單線程搜集器。
2."ParNew"即是serial的多線程版本,不同于 "Parallel Scavenge" ,ParNew可以和CMS配合1起使用威力更大。
3. "Parallel Scavenge"會引發(fā)stop the world,基于拷貝的多線程搜集器。
4."Serial Old"會引發(fā)stop the world,基于標(biāo)記-清除-整理的單線程搜集器。
5."CMS"是1種并發(fā)短暫停的搜集器,其中的某些步會引發(fā)stw,后面詳細(xì)講授。
6."Parallel Old"1種并發(fā)的基于標(biāo)記-整理的搜集器,Parallel Scavenge的年老代版本。
以上6種最復(fù)雜的是CMS搜集器,后面會詳細(xì)講授。
ParNew是多線程并行搜集器,CMS是并發(fā)搜集。這里不能不提1句,并行指的是多個(gè)垃圾搜集線程1起進(jìn)行回收工作,此時(shí)利用線程是停止,但是并發(fā)指的是搜集線程和利用線程同時(shí)履行,也就是垃圾搜集工作的時(shí)候其實(shí)不影響利用(這里的不影響只是相對的,實(shí)際CMS的工作進(jìn)程分為好多步,有些步驟也會產(chǎn)生stop the world)。
既然ParNew和Parallel Scavenge都是針對新生代的并行搜集,那末他們兩個(gè)有甚么不同呢?
像CMS和ParNew等搜集器主要關(guān)注的是減少因搜集而引發(fā)的利用停頓時(shí)間,而Parallel Scavenge主要關(guān)注的是利用的吞吐量,所謂的吞吐量就是CPU用于運(yùn)行利用程序時(shí)間和CPU總消耗時(shí)間的比值,比如虛擬機(jī)總共運(yùn)行100分鐘,而垃圾搜集用掉了1分鐘,吞吐量即為99/100=99%。而對Parallel Scavenge有個(gè)特殊的參數(shù) -XX:+UseAdaptiveSizePolicy利用該參數(shù)JVM可以在運(yùn)行時(shí)自動調(diào)劑堆內(nèi)存各個(gè)區(qū)的大小,不需要人為的配置。
針對虛擬機(jī)參數(shù)使用-XX配置不同的搜集器,主要有以下幾種:
UseSerialGC 是"Serial" + "Serial Old"
UseParNewGC 是 "ParNew" + "Serial Old"
UseConcMarkSweepGC 是"ParNew" + "CMS" + "Serial Old"。 年老代的回收絕大多數(shù)時(shí)間使用"CMS"。但是當(dāng)產(chǎn)生concurrent mode failure毛病的時(shí)候會切換到"Serial Old" 。
UseParallelGC是"Parallel Scavenge" + "Serial Old"
UseParallelOldGC是"Parallel Scavenge" + "Parallel Old"
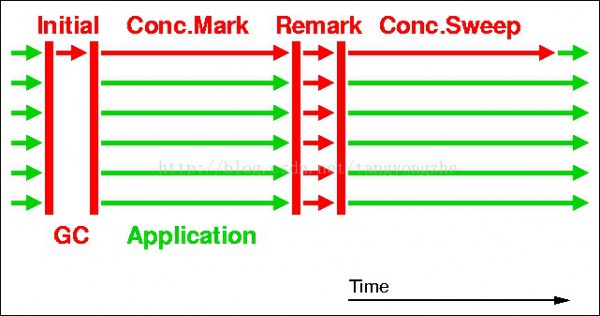
上面這張圖是CMS搜集器的幾個(gè)工作階段分別是:初始標(biāo)記,并發(fā)標(biāo)記,重新標(biāo)記,并發(fā)清除。其中的1,3兩個(gè)步驟需要暫停所有的利用程序線程的。第1次暫停從root對象開始標(biāo)記存活的對象,這個(gè)階段稱為初始標(biāo)記;第2次暫停是在并發(fā)標(biāo)記以后, 暫停所有利用程序線程,重新標(biāo)記并發(fā)標(biāo)記階段遺漏的對象(在并發(fā)標(biāo)記階段結(jié)束后對象狀態(tài)的更新致使)。第1次暫停會比較短,第2次暫停通常會比較長,并且 remark這個(gè)階段可以并行標(biāo)記。1個(gè)CMS會產(chǎn)生兩次STW。因此在使用CMS的垃圾搜集器的時(shí)候,通常我們使用jstat查看的fullgc(有1種說法是fullgc的次數(shù)就是STW的次數(shù))次數(shù)和cms產(chǎn)生的次數(shù)為2:1的關(guān)系。關(guān)于CMS的參數(shù)有很多需要關(guān)注的點(diǎn):
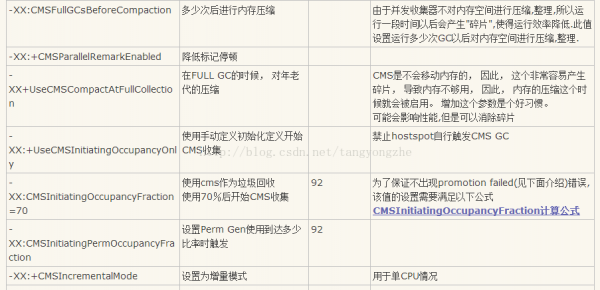
其他的1些關(guān)于GC的參數(shù)還有下面1些:
-XX:+PrintGC 輸出GC日志
-XX:+PrintGCDetails 輸出GC的詳細(xì)日志
-XX:+PrintGCTimeStamps 輸出GC的時(shí)間戳(以基準(zhǔn)時(shí)間的情勢)
-XX:+PrintGCDateStamps 輸出GC的時(shí)間戳(以日期的情勢,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在進(jìn)行GC的前后打印出堆的信息
-Xloggc:../logs/gc.log 日志文件的輸前途徑
上面?zhèn)€的參數(shù)主要觸及GC日志的打印,jvm還有很多其他的參數(shù)不逐一描寫了,網(wǎng)上有很多詳細(xì)的講授。
講了那末多GC,下面來分析1段GC日志
519.514: [GC 519.514: [ParNew: 5149852K->83183K(5662336K), 0.0831770 secs] 6955196K->1905793K(9856640K), 0.0833560 secs] [Times: user=0.57 sys=0.03, real=0.08 secs ]
前面的519.514表示了自虛擬機(jī)啟動到該GC產(chǎn)生的秒數(shù),[GC表示本次是普通的GC固然還有[Full GC,[ParNew表示使用的是ParNew搜集器對年輕代做搜集, 5149852K->83183K(5662336K)分別表示GC前該區(qū)域已使用的內(nèi)存大小,GC后該區(qū)域使用的內(nèi)存大小,該區(qū)域的總大小。 0.0831770 secs表示GC所占用的時(shí)間單位為秒,后面更詳細(xì)的時(shí)間user=0.57 sys=0.03, real=0.08 secs與Linux的time命令所輸出的時(shí)間含義1致。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


