
前言:
本文闡述的是一款經(jīng)過生產(chǎn)環(huán)境檢驗的千萬級數(shù)據(jù)全文檢索(搜索引擎)架構(gòu)。本文只列出前幾章的內(nèi)容節(jié)選,不提供全文內(nèi)容。
在DELL PowerEdge 6850服務(wù)器(四顆64 位Inter Xeon MP 7110N處理器 / 8GB內(nèi)存)、RedHat AS4 Linux操作系統(tǒng)、MySQL 5.1.26、MyISAM存儲引擎、key_buffer=1024M環(huán)境下實測,單表1000萬條記錄的數(shù)據(jù)量(這張MySQL表擁有int、datetime、varchar、text等類型的10多個字段,只有主鍵,無其它索引),用主鍵(PRIMARY KEY)作為WHERE條件進(jìn)行SQL查詢,速度非常之快,只耗費0.01秒。
出自俄羅斯的開源全文搜索引擎軟件 Sphinx ,單一索引最大可包含1億條記錄,在1千萬條記錄情況下的查詢速度為0.x秒(毫秒級)。Sphinx創(chuàng)建索引的速度為:創(chuàng)建100萬條記錄的索引只需3~4分鐘,創(chuàng)建1000萬條記錄的索引可以在50分鐘內(nèi)完成,而只包含最新10萬條記錄的增量索引,重建一次只需幾十秒。
基于以上幾點,我設(shè)計出了這套搜索引擎架構(gòu)。在生產(chǎn)環(huán)境運行了一周,效果非常不錯。有時間我會專為配合Sphinx搜索引擎,開發(fā)一個邏輯簡單、速度快、占用內(nèi)存低、非表鎖的MySQL存儲引擎插件,用來代替MyISAM引擎,以解決MyISAM存儲引擎在頻繁更新操作時的鎖表延遲問題。另外,分布式搜索技術(shù)上已無任何問題。
一、搜索引擎架構(gòu)設(shè)計:
1、搜索引擎架構(gòu)圖:
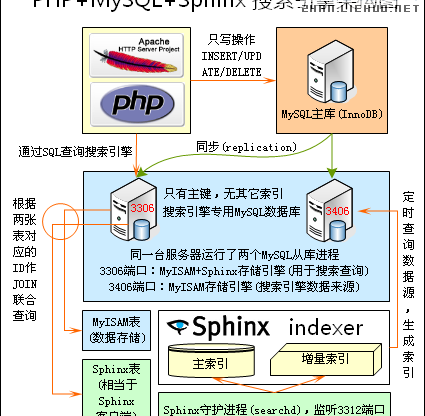
2、搜索引擎架構(gòu)設(shè)計思路:
(1)、調(diào)用方式最簡化:
盡量方便前端Web工程師,只需要一條簡單的SQL語句“SELECT ... FROM myisam_table JOIN sphinx_table ON (sphinx_table.sphinx_id=myisam_table.id) WHERE query='...';”即可實現(xiàn)高效搜索。
(2)、創(chuàng)建索引、查詢速度快:
①、Sphinx Search 是由俄羅斯人Andrew Aksyonoff 開發(fā)的高性能全文搜索軟件包,在GPL與商業(yè)協(xié)議雙許可協(xié)議下發(fā)行。
Sphinx的特征:
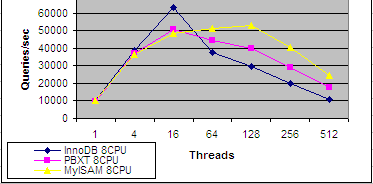
②、通過國外《High Performance MySQL》專家組的測試可以看出,根據(jù)主鍵進(jìn)行查詢的類似“SELECT ... FROM ... WHERE id = ...”的SQL語句(其中id為PRIMARY KEY),每秒鐘能夠處理10000次以上的查詢,而普通的SELECT查詢每秒只能處理幾十次到幾百次:
③、Sphinx不負(fù)責(zé)文本字段的存儲。假設(shè)將數(shù)據(jù)庫的id、date、title、body字段,用sphinx建立搜索索引。根據(jù)關(guān)鍵字、時間、類別、范圍等信息查詢一下sphinx,sphinx只會將查詢結(jié)果的ID號等非文本信息告訴我們。要顯示title、body等信息,還需要根據(jù)此ID號去查詢MySQL數(shù)據(jù)庫,或者從Memcachedb等其他的存儲中取得。安裝SphinxSE作為MySQL的存儲引擎,將MySQL與Sphinx結(jié)合起來,是一種便捷的方法。
創(chuàng)建一張Sphinx類型表,將MyISAM表的主鍵ID和Sphinx表的ID作一個JOIN聯(lián)合查詢。這樣,對于MyISAM表來所,只相當(dāng)于一個WHERE id=...的主鍵查詢,WHERE后的條件都交給Sphinx去處理,可以充分發(fā)揮兩者的優(yōu)勢,實現(xiàn)高速搜索查詢。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


