
做集群運(yùn)維的同學(xué)可能都會遇到這樣1個問題:Hadoop集群使用久了,各個節(jié)點(diǎn)上的數(shù)據(jù)會變得不均衡,多的到達(dá)70,80%,少的就10,20%.面對這類場景,我們的辦法1般就是用HDFS自帶的Balancer工具對其進(jìn)行數(shù)據(jù)平衡.但有的時候,你會發(fā)現(xiàn)雖然節(jié)點(diǎn)間數(shù)據(jù)平衡了,但是節(jié)點(diǎn)內(nèi)各個磁盤塊的數(shù)據(jù)出現(xiàn)了不平衡的現(xiàn)象.這可是Balancer工具所干不了的事情.通過這個場景,我們引入本文的1個話題點(diǎn):HDFS節(jié)點(diǎn)內(nèi)數(shù)據(jù)平衡.這個問題很早的時候其實(shí)就被提出了,詳見issue HDFS⑴312(Re-balance disks within a Datanode).我相信大家在使用Hadoop集群的時候或多或少都遇到過這個問題.本文就來好好聊聊這個話題,和社區(qū)目前對此的解決方案.
磁盤間數(shù)據(jù)不均衡的現(xiàn)象源自于長時間寫操作時數(shù)據(jù)大小不均衡.由于每次寫操作你可以保證寫磁盤的順序性,但是你沒法保證每次寫入的數(shù)據(jù)量都是1個大小.比如A,B,C,D4塊盤,你用默許的RoundRobin磁盤選擇策略去寫,最后4塊盤都寫過了,但是A,B可能寫的block塊就1M,而C,D可能就是128M.
如果磁盤間數(shù)據(jù)不均衡現(xiàn)象確切出現(xiàn)了,它會給我們造成甚么影響呢?有人可能會想,它不就是1個普通磁盤嘛,又不是系統(tǒng)盤,系統(tǒng)盤使用空間太高是會影響系統(tǒng)性能,但是普通盤應(yīng)當(dāng)問題不大吧.這個觀點(diǎn)聽上去是沒問題,但是只能說它斟酌的太淺了.我們從HDFS的讀寫層面來對這個現(xiàn)象做1個分析.這里歸納出了以下2點(diǎn):
第1點(diǎn),磁盤間數(shù)據(jù)不均衡間接引發(fā)了磁盤IO壓力的不同.我們都知道,HDFS上的數(shù)據(jù)訪問頻率是很高的,這就會觸及到大量讀寫磁盤的操作,數(shù)據(jù)多的盤自然的就會有更高頻率的訪問操作.如果1塊盤的IO操作非常密集的話,必將會對它的讀寫性能造成影響.
第2點(diǎn),高使用率磁盤致使節(jié)點(diǎn)可選存儲目錄減少.HDFS在寫B(tài)lock數(shù)據(jù)的時候,會挑選剩余可用空間滿足待寫B(tài)lock的大小的情況下時,才會進(jìn)行挑選,如果高使用率磁盤目錄過量,會致使這樣的候選塊變少.所以這方面其實(shí)偏向的是對HDFS的影響.
磁盤間數(shù)據(jù)不均衡現(xiàn)象出現(xiàn)了,目前我們有甚么辦法解決呢?下面是2種現(xiàn)有解決方案:
方案1:節(jié)點(diǎn)下線再上線.將節(jié)點(diǎn)內(nèi)數(shù)據(jù)不均衡的機(jī)器進(jìn)行Decommision下線操作,下線以后再次上線.上線以后相當(dāng)因而1個全新的節(jié)點(diǎn)了,數(shù)據(jù)也將會重新存儲到各個盤上.這類做法給人感覺會比較暴力,當(dāng)集群范圍比較小的時候,代價太高,此時下線1個節(jié)點(diǎn)會對集群服務(wù)造成不小的影響.
方案2:人工移動部份數(shù)據(jù)block存儲目錄.此方案比方案1更加靈活1些,但是數(shù)據(jù)目錄的移動要保證準(zhǔn)確性,否則會造成移動完目錄后數(shù)據(jù)找不到的現(xiàn)象.下面舉1個實(shí)際的例子,比如我們想將磁盤1上的數(shù)據(jù)挪到磁盤2上.現(xiàn)有磁盤1的待移動存儲目錄以下:
/data/1/dfs/dn/ current/BP⑴788246909-xx.xx.xx.xx⑴412278461680/current/ finalized/subdir0/subdir1/
我移動到目標(biāo)盤上的路徑應(yīng)當(dāng)保持這樣的路徑格式不變,只變化磁盤所在的目錄,目標(biāo)路徑以下:
/data/2/dfs/dn/current/BP⑴788246909-xx.xx.xx.xx⑴412278461680/current/finalized/subdir0/subdir1/
如果上述目錄結(jié)構(gòu)出現(xiàn)變化,就會造成HDFS找不到此數(shù)據(jù)塊的情況.
前面鋪墊了這么多的內(nèi)容,就是為了引出本節(jié)要重點(diǎn)論述的內(nèi)容:DiskBalancer.DiskBalancer從名字上,我們可以看出,它是1個類似于Balancer的數(shù)據(jù)平衡工具.但是它的作用范圍是被限制在了Disk上.首先這里要說明1點(diǎn),DiskBalancer目前是未發(fā)布的功能特性,所以你們在現(xiàn)有發(fā)布版中是找不到此工具的.下面我將會全方面的介紹DiskBalancer,讓大家認(rèn)識,了解這個強(qiáng)大的工具.
首先我們先來了解DiskBalancer的設(shè)計核心,這里與Balancer有1點(diǎn)點(diǎn)的區(qū)分.Balancer的核心點(diǎn)在于數(shù)據(jù)的平衡,數(shù)據(jù)平衡好就OK了.而DiskBalancer在設(shè)計的時候提出了2點(diǎn)目標(biāo):
第1.Data Spread Report.數(shù)據(jù)散布式的匯報.這是1個report匯報的功能.也就是說,DiskBalancer工具能支持各個節(jié)點(diǎn)匯報磁盤塊使用情況的功能,通過這個功能我可以了解到目前集群內(nèi)使用率TopN的節(jié)點(diǎn)磁盤.
第2.Disk Balancing.第2點(diǎn)才是磁盤數(shù)據(jù)的平衡.但是在磁盤內(nèi)數(shù)據(jù)平衡的時候,要斟酌到各個磁盤storageType的不同,由于之條件到過HDFS的異構(gòu)存儲,不同盤可能存儲介質(zhì)會不同,目前DiskBalancer不支持跨存儲介質(zhì)的數(shù)據(jù)轉(zhuǎn)移,所以目前都是要求在1個storageType下的.
以上2點(diǎn)取自于DiskBalancer的設(shè)計文檔(DiskBalancer相干設(shè)計文檔可見文章末尾的參考鏈接).
此部份來討論討論DiskBalancer的架構(gòu)設(shè)計.通過架構(gòu)設(shè)計,我們能更好的了解它的1個整體情況.DiskBalancer的核心架構(gòu)思想以下圖所示:
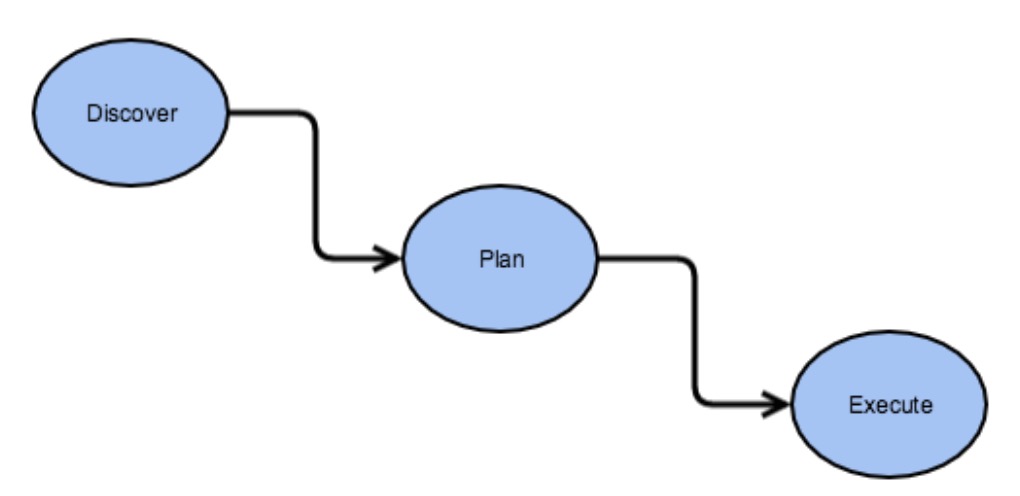
上面進(jìn)程經(jīng)過了3個階段,Discover(發(fā)現(xiàn))到Plan(計劃),再從Plan(計劃)到Execute(履行).下面來詳細(xì)解釋這3個階段:
發(fā)現(xiàn)階段做的事情實(shí)際上就是通過計算各個節(jié)點(diǎn)內(nèi)的磁盤使用情況,然后得出需要數(shù)據(jù)平衡的磁盤列表.這里會通過Volume Data Density磁盤使用密度的概念作為1個評判的標(biāo)準(zhǔn),這個標(biāo)準(zhǔn)值將會以節(jié)點(diǎn)總使用率作為比較值.舉個例子,如果1個節(jié)點(diǎn),總使用率為75%,就是0.75,其中A盤使用率0.5(50%),那末A盤的volumeDataDensity密度值就等于0.75-0.5=0.25.同理,如果超越的話,則密度值將會為負(fù)數(shù).因而我們可以用節(jié)點(diǎn)內(nèi)各個盤的volumeDataDensity的絕對值來判斷此節(jié)點(diǎn)內(nèi)磁盤間數(shù)據(jù)的平衡情況,如果總的絕對值的和越大,說明數(shù)據(jù)越不平衡,這有點(diǎn)類似于方差的概念.Discover階段將會用到以下的連接器對象:
1.DBNameNodeConnector
2.JsonConnector
3.NullConnector
其中第1個對象會調(diào)用到Balancer包下NameNodeConnector對象,以此來讀取集群節(jié)點(diǎn),磁盤數(shù)據(jù)情況
拿到上1階段的匯報結(jié)果數(shù)據(jù)以后,將會進(jìn)行履行計劃的生成.Plan其實(shí)不是1個最小的履行單元,它的內(nèi)部由各個Step組成.Step中會指定好源,目標(biāo)磁盤.這里的磁盤對象是1層經(jīng)過包裝的對象:DiskBalancerVolume,其實(shí)不是原來的FsVolume.這里順便提1下DiskBalancer中對磁盤節(jié)點(diǎn)等概念的轉(zhuǎn)化:
最后1部份是履行階段,所有的plan計劃生成好了以后,就到了履行階段.這些計劃會被提交到各自的DataNode上,然后在DiskBalancer類中進(jìn)行履行.DiskBalancer類中有專門的類對象來做磁盤間數(shù)據(jù)平衡的工作,這個類名稱叫做DiskBalancerMover.在磁盤間數(shù)據(jù)平衡的進(jìn)程中,高使用率的磁盤會移動數(shù)據(jù)塊到相對低使用率的磁盤,等到滿足1定閾值關(guān)系的情況下時,DiskBalancer會漸漸地退出.在DiskBalancer的履行階段,有以下幾點(diǎn)需要注意:
DiskBalancer內(nèi)部提供了許多種別的命令操作,比以下面的查詢命令:
hdfs diskbalancer -query nodename.mycluster.com我們也能夠履行相應(yīng)的plan命令來生成plan計劃文件.
hdfs diskbalancer -uri hdfs://mycluster.com -plan node1.mycluster.com然后我們可以用生成好后的json文件進(jìn)行DiskBalancer的履行
hdfs diskbalancer -execute /system/diskbalancer/nodename.plan.json固然,如果我們發(fā)現(xiàn)我們履行了毛病的plan,我們也能夠通過cancel命令進(jìn)行清除:
hdfs diskbalancer -cancel /system/diskbalancer/nodename.plan.json或
hdfs diskbalancer -cancel <planID> -node <nodename>在DiskBalancer中會觸及到比較多的object-json的關(guān)系轉(zhuǎn)換,所以你會看到1些帶.json后綴的文件
總而言之,DiskBalancer是1個很實(shí)用的功能特性.在Hadoop中,有專門的分支用于開發(fā)此功能,就是HDFS⑴312,感興趣的同學(xué)可以下載Hadoop的最新代碼進(jìn)行學(xué)習(xí).本人非常榮幸地也向此功能提交了1個小patch, issue編號,HDFS⑴0560.這個new feature很快就要在新版的Hadoop中發(fā)布了,相信會對Hadoop集群管理人員非常有幫助.
1.https://issues.apache.org/jira/secure/attachment/12755226/disk-balancer-proposal.pdf
2.https://issues.apache.org/jira/secure/attachment/12810720/Architecture_and_test_update.pdf
2.https://issues.apache.org/jira/browse/HDFS⑴312
3.https://issues.apache.org/jira/browse/HDFS⑴0560

上一篇 撲克牌順子
下一篇 Java對象的序列化和反序列化
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


