
1.1、Kafka Consumer提供了2種API:high level與low level(SimpleConsumer)。
(1)high level consumer的API較為簡單,不需要關心offset、partition、broker等信息,kafka會自動讀取zookeeper中該consumer group的last offset。
(2)low level consumer也叫SimpleConsumer,這個接口非常復雜,需要自己寫代碼去實現對offset、partition、broker和broker的切換,能不用就不用,那什么時候必須用?
1、Read a message multiple times
2、Consume only a subset of the partitions in a topic in a process
3、Manage transactions to make sure a message is processed once and only once
Flink提供了high level的API來消費kafka的數據:flink-connector-kafka-0.8_2.10。注意,這里的0.8代表的是kafka的版本,你可以通過maven來導入kafka的依賴,具體以下:
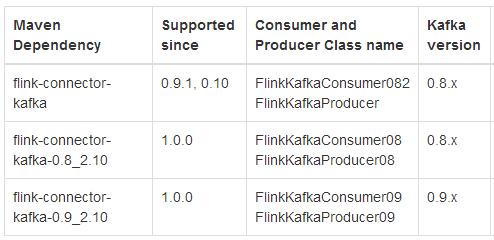
例如你的kafka安裝版本是“kafka_2.10-0.8.2.1”,即此版本是由scala2.10編寫,kafka的本身版本是0.8.2.1.那此時你需要添加以下的內容到maven的pom.xml文件中:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.8_2.10</artifactId>
<version>${flink.version}</version>
</dependency>注意:
$${flink.version}是個變量,自己調劑下代碼,例如可以直接寫1.0.0。我的項目里采取的是添加了properties來控制${flink.version}:
<properties>
<project.build.sourceEncoding>UTF⑻</project.build.sourceEncoding>
<flink.version>1.0.0</flink.version>
</properties>這里主要是介紹下Flink集群與kafka集群的搭建。
基礎的軟件安裝包括JDK、scala、hadoop、zookeeper、kafka和flink就不介紹了,直接看下flink的集群配置和kafka的集群配置。
zookeeper–3.4.6
hadoop–2.6.0
kafka–2.10-0.8.2.1
flink–1.0.3
3.1.1、環境變量
添加FLINK_HOME和path的內容:
export FLINK_HOME=/usr/local/flink/flink-1.0.3
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin:${KAFKA_HOME}/bin:${FLINK_HOME}/bin:$PATH
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib3.1.2、修改conf/flink-conf.yaml
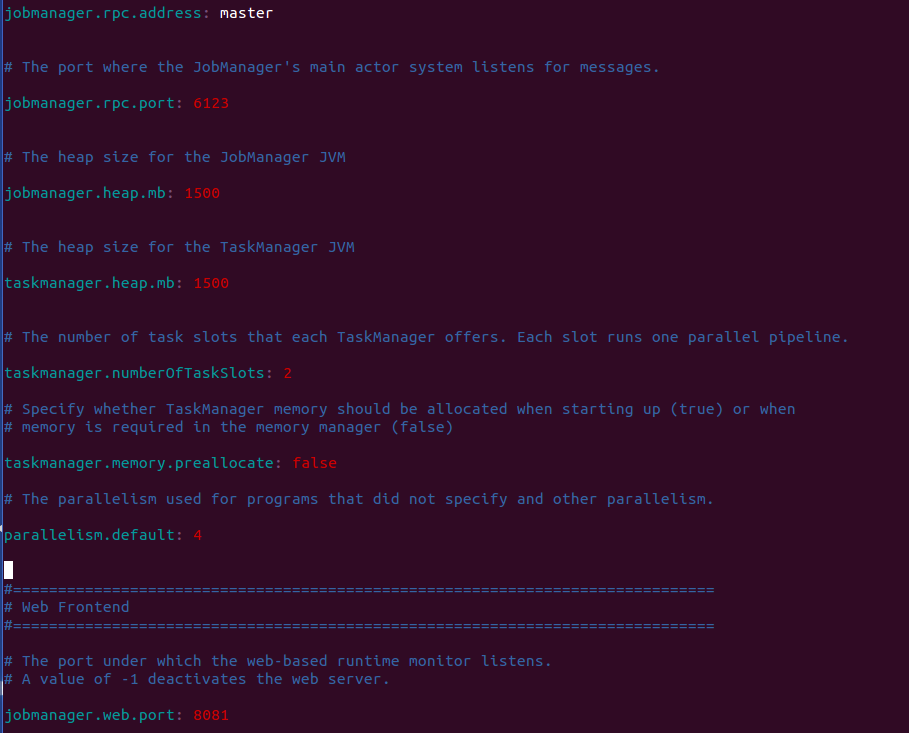
這幾近是最簡單的配置方式了,主要注意要修改jobmanager.rpc.address為集群中jobManager的IP或hostname。檢查點和HA的參數都沒有配置。
3.1.3、slaves文件

這個文件中寄存的信息是taskmanager的hostname。
3.1.4、復制flink目錄和.bashrc文件到集群中其他的機器,并使bashrc生效
root@master:/usr/local/flink# scp -r flink⑴.0.3/ root@worker1:/usr/local/flink/
root@master:/usr/local/flink# scp -r flink⑴.0.3/ root@worker2:/usr/local/flink/
root@master:/usr/local/flink# scp ~/.bashrc root@worker1:~/.bashrc
root@master:/usr/local/flink# scp ~/.bashrc root@worker2:~/.bashrc
root@worker1:~# source ~/.bashrc
root@worker2:~# source ~/.bashrc 3.2.1、環境變量
省略
3.2.2、配置config/zookeeper.properties
由于kafka集群依賴于zookeeper集群,所以kafka提供了通過kafka去啟動zookeeper集群的功能,固然也能夠手動去啟動zookeeper的集群而不通過kafka去啟動zookeeper的集群。

注意這里的dataDir最好不要指定/tmp目錄下,由于機器重啟會刪除此目錄下的文件。且指定的新路徑必須存在。
3.2.3、配置config/server.properties
這個文件是啟動kafka集群需要指定的配置文件,注意2點:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The port the socket server listens on
#port=9092
listeners=PLAINTEXT://:9092broker.id在kafka集群的每臺機器上都不1樣,我這里3臺集群分別是0、1、2.
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=master:2181,worker1:2181,worker2:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
zookeeper.connect要配置kafka集群所依賴的zookeeper集群的信息,hostname:port。
3.2.4、復制kafka路徑及環境變量到其他kafka集群的機器,并修改server.properties中的broker_id.
復制進程省略
3.3.1、首先啟動zookeeper集群(3臺zookeeper機器都要啟動):
root@master:/usr/local/zookeeper/zookeeper-3.4.6/bin# zkServer.sh start
root@worker1:/usr/local/zookeeper/zookeeper-3.4.6/bin# zkServer.sh start
root@worker2:/usr/local/zookeeper/zookeeper-3.4.6/bin# zkServer.sh start驗證zookeeper集群:
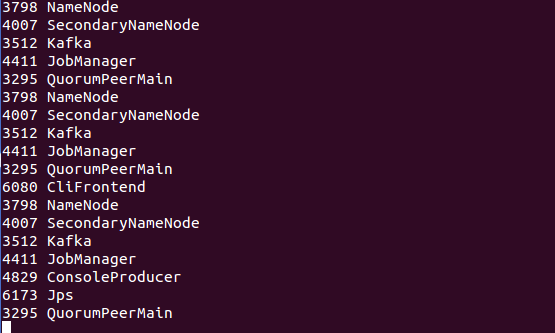
進程是不是啟動;zookeeper集群中是不是可以正常顯示leader和follower。
root@master:/usr/local/zookeeper/zookeeper-3.4.6/bin# jps
3295 QuorumPeerMain
root@master:/usr/local/zookeeper/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
root@master:/usr/local/zookeeper/zookeeper-3.4.6/bin#
root@worker1:/usr/local/zookeeper/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
root@worker1:/usr/local/zookeeper/zookeeper-3.4.6/bin#
root@worker2:/usr/local/zookeeper/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
root@worker2:/usr/local/zookeeper/zookeeper-3.4.6/bin# 3.3.2、啟動kafka集群(3臺都要啟動)
root@master:/usr/local/kafka/kafka_2.10-0.8.2.1/bin# kafka-server-start.sh ../config/server.properties &
root@worker1:/usr/local/kafka/kafka_2.10-0.8.2.1/bin# kafka-server-start.sh ../config/server.properties &
root@worker2:/usr/local/kafka/kafka_2.10-0.8.2.1/bin# kafka-server-start.sh ../config/server.properties &驗證:
進程;日志
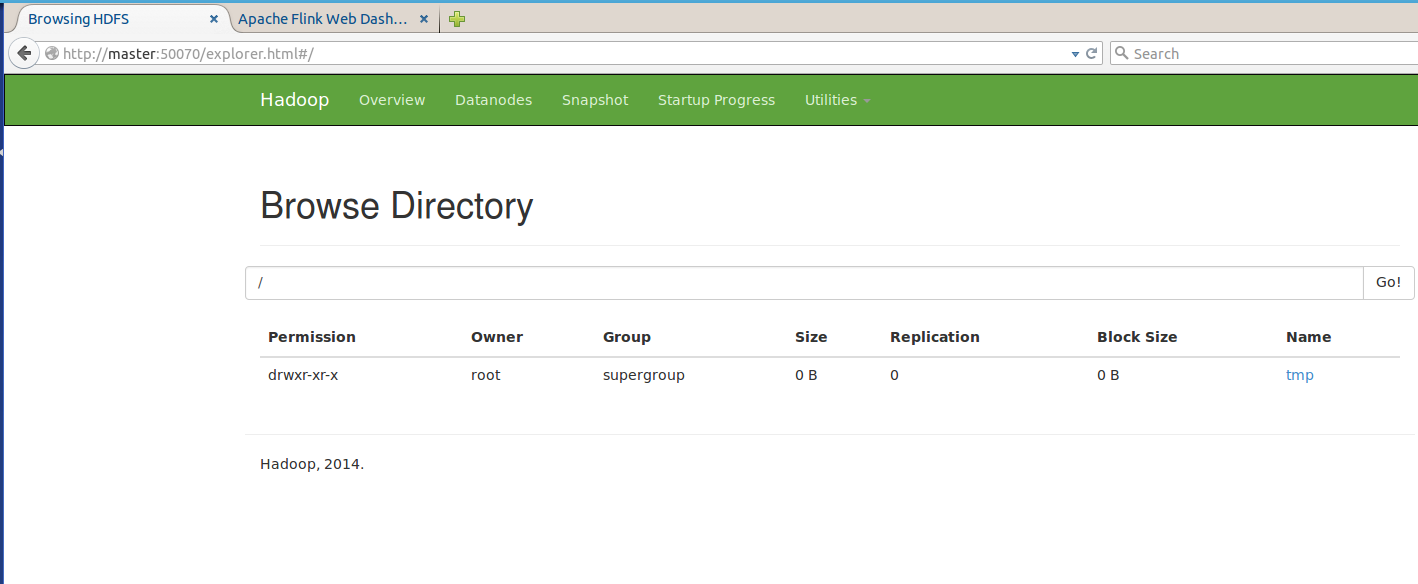
3512 Kafka3.3.3、啟動hdfs(master上啟動便可)
root@master:/usr/local/hadoop/hadoop-2.6.0/sbin# start-dfs.sh 驗證:進程及webUI
root@master:/usr/local/hadoop/hadoop-2.6.0/sbin# jps
3798 NameNode
4007 SecondaryNameNode
root@worker1:/usr/local/hadoop/hadoop-2.6.0/sbin# jps
3843 DataNode
root@worker2:/usr/local/hadoop/hadoop-2.6.0/sbin# jps
3802 DataNodewebUI:50070,默許可配置
3.3.4、啟動Flink集群(master便可)
root@master:/usr/local/flink/flink-1.0.3/bin# start-cluster.sh 驗證:進程及WebUI
root@master:/usr/local/flink/flink-1.0.3/bin# jps
4411 JobManager
root@worker1:/usr/local/flink/flink-1.0.3/bin# jps
4151 TaskManager
root@worker2:/usr/local/flink/flink-1.0.3/bin# jps
4110 TaskManagerWebUI:8081(默許,可配置)
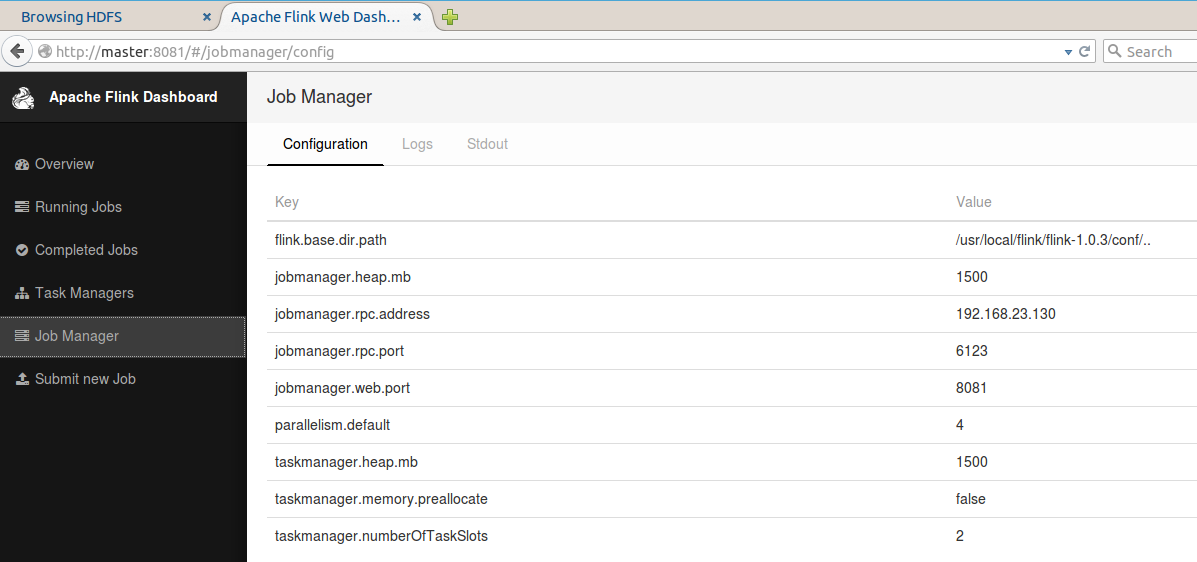
4.1、代碼
這里就是簡單的實現接收kafka的數據,要指定zookeeper和kafka的集群配置,并指定topic的名字。
最后將consume的數據直接打印出來。
import java.util.Properties
import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
/**
* 用Flink消費kafka
*/
object ReadingFromKafka {
private val ZOOKEEPER_HOST = "master:2181,worker1:2181,worker2:2181"
private val KAFKA_BROKER = "master:9092,worker1:9092,worker2:9092"
private val TRANSACTION_GROUP = "transaction"
def main(args : Array[String]){
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.enableCheckpointing(1000)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// configure Kafka consumer
val kafkaProps = new Properties()
kafkaProps.setProperty("zookeeper.connect", ZOOKEEPER_HOST)
kafkaProps.setProperty("bootstrap.servers", KAFKA_BROKER)
kafkaProps.setProperty("group.id", TRANSACTION_GROUP)
//topicd的名字是new,schema默許使用SimpleStringSchema()便可
val transaction = env
.addSource(
new FlinkKafkaConsumer08[String]("new", new SimpleStringSchema(), kafkaProps)
)
transaction.print()
env.execute()
}
}4.2、打包:
mvn clean package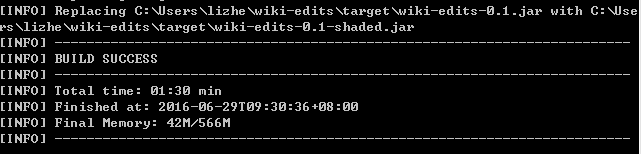
看到成功標志,否則會提示error的地方。
4.3、發布到集群
root@master:/usr/local/flink/flink-1.0.3/bin# flink run -c wikiedits.ReadingFromKafka /root/Documents/wiki-edits-0.1.jar 驗證:進程及WebUI
root@master:/usr/local/flink/flink-1.0.3/bin# jps
6080 CliFrontend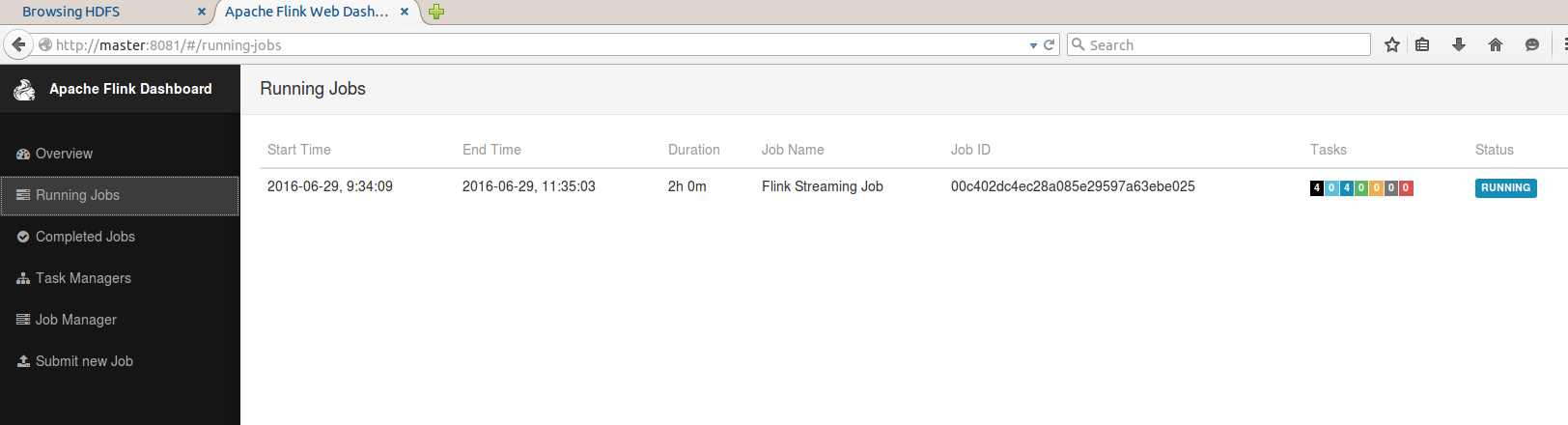
5.1、通過kafka console produce數據
之前已在kafka中創建了名字為new的topic,因此直接produce new的數據:
root@master:/usr/local/kafka/kafka_2.10-0.8.2.1/bin# kafka-console-producer.sh --broker-list master:9092,worker1:9092,worker2:9092 --topic new生產數據:
5.2、查看flink的標準輸出中,是不是已消費了這部份數據:
root@worker2:/usr/local/flink/flink-1.0.3/log# ls -l | grep out
-rw-r--r-- 1 root root 254 6月 29 09:37 flink-root-taskmanager-0-worker2.out
root@worker2:/usr/local/flink/flink-1.0.3/log# 我們在worker2的log中發現已有了數據,下面看看內容:
OK,沒問題,flink正常消費了數據。
kafka作為1個消息系統,本身具有高吞吐、低延時、持久化、散布式等特點,其topic可以指定replication和partitions,使得可靠性和性能都可以很好的保證。
Kafka+Flink的架構,可使flink只需關注計算本身。
參考
http://www.tuicool.com/articles/fI7J3m
https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming/connectors/kafka.html
http://kafka.apache.org/082/documentation.html
http://dataartisans.github.io/flink-training/exercises/toFromKafka.html
http://data-artisans.com/kafka-flink-a-practical-how-to/

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


