
之前博文中關(guān)于CNN的模型訓(xùn)練功能上是能實(shí)現(xiàn),但是研究CNN模型內(nèi)部結(jié)構(gòu)的時候,對各個權(quán)重系數(shù)
# Input Layer
x = tf.placeholder('float',[None,784])
y_ = tf.placeholder('float',[None,10])
# First Layer
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x,[-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# Second Layer
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# Connect Layer
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1) + b_fc1)
# Dropout Layer
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)
# Output Layer
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])這段程序,是mnist_test2.py中關(guān)于Tensorflow Graph建立的代碼,里面為所有使用到的Variables都分配了指定的大小。例如x通過placeholder預(yù)留了None*784大小的shape(None會隨著batch獲得的數(shù)據(jù)個數(shù)而改變),第1層的卷積系數(shù)W_conv1是5*5*1*32大小的shape,后面不再贅述。
有些shape比如輸入的xNone*784的784是28*28個8位灰度值的shape,y_是None*10個數(shù)字分類的shape,輸出的b_fc2是對應(yīng)10個輸出種別的偏差。但是對其他參數(shù)的話,我就不由要問:①這么做是為何呢?②如果不這么設(shè)置參數(shù)行不行呢?③如果我換1套數(shù)據(jù)集,參數(shù)還是這么設(shè)置么?
先回答第2個問題吧,不行。如果隨便更換參數(shù),換的對可能能跑通,但是影響性能,但是更多的時候會是下面的結(jié)果:


在回答第1個問題之前,建議大家瀏覽1下2012年NIPS上做ImageNet的文獻(xiàn)1和解釋LaNet5的CNN模型的PPT,如果時間不夠用的話,也能夠直接看1下qiaofangjie的中文參數(shù)解析。里面可以先對LeNet5的參數(shù)有個大概了解。下面我對比著經(jīng)典的圖,大體歸納1下:

CNN里的層,除輸入/輸出層以外,把隱含層又分成了卷積層、池化層、和全連接層。3者的作用及介紹也能夠參考小新的貓的理解。卷積層會對原始輸入數(shù)據(jù)做加權(quán)求和的處理,學(xué)過通訊的同學(xué)1定對1維線性卷積里面“錯位相乘相加”很熟習(xí)(諒解我強(qiáng)行奶1口原來的專業(yè)),這里就是線性卷積在2維里面的推行。池化層是為了減小模型復(fù)雜度,通過降采樣(又是通訊里有概念我會亂講?)縮小特點(diǎn)圖的尺寸。全連接層是將終究高度抽象化的特點(diǎn)圖與輸出直接進(jìn)行的全連接,這與入門級MNIST庫的模型訓(xùn)練做的事兒是1樣的,1個簡單的全映照。
具體的看,第1個卷積層C1對32*32的輸入數(shù)據(jù)(假定成1個矩陣,其中每一個元素代表當(dāng)前位置像素點(diǎn)灰度值的強(qiáng)弱)進(jìn)行2維加權(quán)相加
其中上標(biāo)
(此處補(bǔ)零采取了VALID模式,這個問題后面會接著說)。我們假定卷積器的權(quán)重矩陣是1個5*5的,相當(dāng)于對5*5的輸入數(shù)據(jù),與5*5的卷積器卷積后,得到了1*1的數(shù)值,如果是5*6的原始數(shù)據(jù),卷積后會得到1*2的輸出,所以推行到32*32的數(shù)據(jù),輸出會得到28*28的尺寸。再推行1下就會得到:
輸出寬度=輸入寬度-(卷積器寬度⑴)
輸出高度=輸入高度-(卷積器高度⑴)
至于為何1幅輸入會得到6組對應(yīng)的卷積輸出呢?這個問題對我來講還說不清楚,只能暫時理解為1幅輸入的6個不同的特點(diǎn)(Hinton老師講家譜樹的時候就用了6個對應(yīng)特點(diǎn)表示是英國人還是意大利,是爺爺輩兒還是孫子輩兒等),比如輸入是不是有圓圈形狀,邊沿是不是明確,是不是有紋理特點(diǎn)等。這個問題后面的話有可能會可視化驗(yàn)證1下,目前只能這么理解了。
接下來第2個池化層S2,對6*28*28的特點(diǎn)圖進(jìn)行下采樣得到了6*14*14的池化層特點(diǎn)圖,主要是由于其中采取每2*2的塊兒進(jìn)行1次容和統(tǒng)計,并且塊與塊兒直接不交疊,掐指1算還真是(28/2*28/2),池化操作并沒有增加特點(diǎn)維度,只是單純的下采樣。
在后面的那層卷積層C3的shape也能夠理解了,對14*14的特點(diǎn)輸入,輸出10*10的特點(diǎn)圖,并且此時把6個特點(diǎn)抽象到了更多的16個特點(diǎn)。下面的S4就不說了。
看1下C5,這里又來了問題了,暫時還不能理解,為何會出現(xiàn)120這個數(shù)字,暫且擱置。1般CNN中的全連接層,我見到的都是1⑵層,并且兩個層的shape是1致的。比如這里都是120,文獻(xiàn)1中全是2048。
ok,以上就是對LeNet5的參數(shù)理解,下面我們來看1下MNIST程序中的各個參數(shù)。首先,建議使用以下代碼,在跑通的程序中,方便查看每一個變量的shape,具體代碼以下:
def showSize():
print "x size:",batch[0].shape
#print "x_value",batch[0]
print "y_ size:",batch[1].shape
#print "y_example",batch[1][0]
#print "y_example",batch[1][9]
#print "y_example",batch[1][10]
print "w_conv1 size:",W_conv1.eval().shape
print "b_conv1 size:",b_conv1.eval().shape
print "x_image size:",x_image.eval(feed_dict={x:batch[0]}).shape
print "h_conv1 size:",h_conv1.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "h_pool1 size:",h_pool1.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "w_conv2 size:",W_conv2.eval().shape
print "b_conv2 size:",b_conv2.eval().shape
print "h_conv2 size:",h_conv2.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "h_pool2 size:",h_pool2.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "w_fc1 size:",W_fc1.eval().shape
print "b_fc1 size:",b_fc1.eval().shape
print "h_pool2_flat size:",h_pool2_flat.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "h_fc1 size:",h_fc1.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "h_fc1_drop size:",h_fc1_drop.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "w_fc2 size:",W_fc2.eval().shape
print "b_fc2 size:",b_fc2.eval().shape
print "y_conv size:",y_conv.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
像這樣插在每次循環(huán)中,然后,我們可以試運(yùn)行1下看看結(jié)果
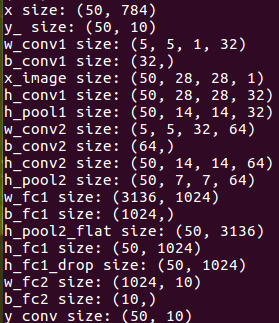
這個小函數(shù)寫的時候要注意,對Tensor類型的Variable,并沒有shape這個屬性,必須在每一個Tensor.eval()才可使用.shape屬性,而Tensor.eval()的話,就需要feed_dict1個依賴值才可以取得tensor實(shí)例,否則Tensor對象只是1個代號而已。
在輸入50個batch的時候可以看到輸入,輸出shape不說了,w_conv1觸及到tf.conv2d的用法,具體可以參考官方文檔,這里的前兩個5對應(yīng)的卷及系數(shù)shape,第3個參數(shù)1表示輸入通道,對應(yīng)輸入數(shù)據(jù)只有灰度值1個特點(diǎn),或說是對應(yīng)LeNet分析中1幅圖,最后1個32是輸出通道數(shù),表示輸出32組特點(diǎn)。
稍等,對MNIST的28*28的輸入數(shù)據(jù),經(jīng)過第1層卷積C1,為什么輸出的h_conv1還是28*28的維度,而不是剛剛推論中的24*24呢?這我也研究了好久,緣由在于tf.conv2d函數(shù)的參數(shù)指定了padding類型為“SAME”,這個參數(shù)的作用在官方文檔中直接決定了輸出的shape,截選以下:

這只是數(shù)值上說明了,具體的緣由小新的貓的理解說的非常明白,他還對照了Matlab和Tensorflow對Padding參數(shù)的不同選項(xiàng),可以視具體的利用環(huán)境在做測試。
最后看1下全連接層的參數(shù)w_fc1,對接上面的卷基層輸出,第1個參數(shù)是池化后7*7的尺寸*64組特點(diǎn),第2個參數(shù)與LeNet的1201致,是輸出給全連接的參數(shù)。
現(xiàn)在看來,與卷積,池化相干的shape變化應(yīng)當(dāng)是可以理解了,不過還有兩種參數(shù)不理解:
①是卷積層的特點(diǎn)數(shù),為何LeNet里面兩層卷積層的特點(diǎn)會是6和16,而MNIST是32和64,按道理MNIST是28*28的數(shù)據(jù)輸入,還小于LeNet的32*32呢,卻有著更高的特點(diǎn)維度。
②全連接層的參數(shù),LeNet里面用的2個120參數(shù)的,而MNIST里面全連接卻有1024個參數(shù)。
這些問題也問過Tensorflow群里群友,問到的都說是經(jīng)驗(yàn)問題,需要自己掌控,真的是這樣哇?這兩個參數(shù)的選擇難道只是個工程經(jīng)驗(yàn)問題嘛?我目前的理解的話只能1邊繼續(xù)看資料,1邊工程做實(shí)驗(yàn)測試1下模型收斂速度啦。結(jié)合TensorBoard可視化應(yīng)當(dāng)后者會給我個答案。
這篇文章,對CNN的網(wǎng)絡(luò)中參數(shù)的shape做了分析,希望能對大家理解起來有所幫助,至于文中說到的兩個參數(shù)遺留問題,也希望有大神能不吝指教呀。
PS:我必須要吐槽!CSDN為何只能保存1個草稿,我寫第1篇博文的時候突然覺得應(yīng)當(dāng)把這個問題剝離出來先講1講,結(jié)果之前那篇的草稿就沒有了!那也是1個半小時的思路整理啊!不過也怪自己沒有備份。TAT

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


