
數據的生命周期1般包括“生成、傳輸、消費”3個階段。在有些場景下,我們需要將數據的變化快速地反饋到在線服務中,因此出現了實時數據流的概念。如何衡量數據流是不是“可靠”,不同的業務之間關注的指標差別很大。根據對大量業務場景的視察,我們發現對數據流要求最嚴格的業務場景常常和錢有關。
在廣告平臺業務中,廣告的預算和消費數據。
- 廣告主修改廣告預算,投放系統首先將新的預算更新到數據庫,然后需要將其同步到檢索端。檢索端將廣告的預算和已消費金額作對照,重新決定廣告是不是有效。如果沒有及時更新,會致使廣告超預算消費或沒有及時上線,不管哪一種情況,損失都將由廣告平臺承當。
- 廣告的消費數據1般在廣告產生特定事件的時候產生(展現,點擊,轉化等)。當產生消費數據時,需要將其同步到檢索端,檢索端更新廣告的已消費金額,并和廣告的預算做對照,重新決定廣告是不是有效。如果沒有及時更新,會致使廣告超預算消費,損失將由廣告平臺承當。
在電商業務中,商品的庫存和價格。當商品庫存變少時,如果沒有及時同步到服務端,會使用戶在結算時才發現商品已無貨,傷害用戶體驗,乃至致使用戶流失。1個極真個業務場景是秒殺。一樣,如果商品的價格變高時沒有及時同步到服務端,會致使用戶在付款的時候發現價格變高,傷害用戶體驗,乃至致使用戶流失。另外,如果庫存增加或價格下降時,沒有及時同步到服務端,會流失可能帶來的交易,帶來的損失也只能是電商平臺承當。
在電商業務中,用戶的消費數據。有些電商業務中允許用戶預充值,用戶的賬戶可能會有余額。如果用戶產生了消費,但定單和余額并沒有及時更新,可想而知會致使用戶產生很大的疑惑。
因此,本文重點討論1下這些業務場景下對實時數據流的要求。相信在這些場景下都可以認為是可靠的實時數據流,可以很容易適應其他業務。在這些場景下的實時數據流中,常常最關心3個指標:可用性,準確性,實時性。
可用性
最基本的要求,可靠的實時數據流必須要高可用的。
準確性
準確性表示數據流的消費端接收的數據,和數據流發送端發送的數據保持嚴格1致。也就是常說的“不重不漏”。在有些場景下,如果消費真個操作滿足“冪等性”,那末對“不重”的要求可以放寬。但是對“不漏”的要求常常1般是不能讓步的。
?
實時性
實時性表示數據的傳輸要滿足低延時。延時1般定義為,1條數據從被發送端發送到被消費端接收之間的時間。不同的場景對實時性的要求不同,1般分為秒級和分鐘級。
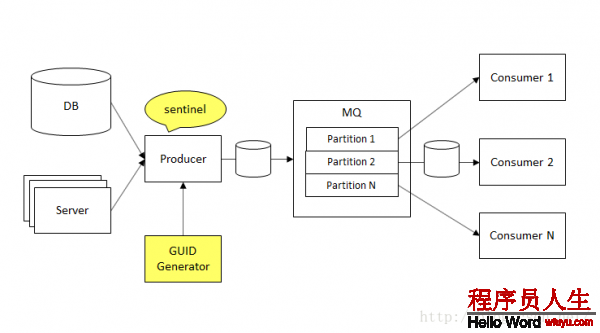
為了方便討論,我們以1個最簡單的實時數據流系統為例,其包括3個模塊:生產者,傳輸模塊,消費者。復雜的實時數據流系統可以認為是這3個模塊的屢次組合。1般來講,我們會使用 Message Queue 作為數據的傳輸模塊,因此在下文中使用MQ來代替傳輸模塊。接下來我們從3個方面討論如何保證實時數據流的可靠。
可用性
成熟的 MQ 系統(例如kafka)都用保障高可用性的方案。生產者和消費者我們1般是使用集群來提高可用性。
在生產者端,對可用性的定義包括兩重含義:
具體分兩種情況。1種情況是數據量非常大,但是能容忍在極端情況,有很小1部份的丟失(例如廣告的消費數據)。另1種情況是數據量不是特別大,但對準確性要求非常高,數據是嚴格不能丟失的(例如用戶充值數據)。兩種情況的處理方案有所不同。
第1種情況,在消息生成的時候,生產者1般都會先落地到本地磁盤,再由1個單獨的程序從磁盤讀取數據并發送到 MQ。這樣有幾個好處:
第2種情況,生產者1般是將數據直接寫入1個可靠的存儲系統中(例如數據庫),再由1個單獨的程序將數據從存儲系統中讀出并寫入到 MQ。
一樣,在消費者端,也是先使用 Flume 將數據落地到本地磁盤。如果消費者產生了宕機,也其實不影響 Flume 繼續從 MQ 讀取數據。在消費者重啟或遷移到備用機器以后,可以繼續之前的工作。
這樣,生產者和消費者都可以認為是在使用磁盤作為介質和 MQ 在通訊,而不是網絡,而磁盤的可靠性常常比網絡更高。另外一方面,生產者和消費者可以更專注于其本職工作,使用 Flume -> Kafka -> Flume 的開源方案,也避免重復開發。
雖然 Flume 在使用進程中非常穩定,但如果是對可用性要求非常高的系統,我們依然要斟酌在 Flume 程序崩潰乃至磁盤破壞時的恢復方案。特別在磁盤產生破壞時,我們常常沒法準肯定位生產者哪些已生產的數據沒有被發送到 MQ。1個典型的方案是重做,行將我們沒法肯定是不是已發送到 MQ 的數據全部重發1次。因此,在消費者端,保證操作的冪等性是非常重要的。
準確性
準確性可以簡單表述為“不重不漏”。“不重”的保證比較困難,在上文已討論,在數據流產生異常的某些情況下,我們是沒法或相當麻煩才能定位哪些數據已發送到 MQ 中,因此需要批量重做,這就會致使 MQ 中有重復的數據。因此,1般的方案常常都是將消費者設計成操作冪等性的,這樣就可以夠容忍數據重復的情況。
“不漏”在設計到財務的系統中常常不能讓步,可以延遲,但不能遺漏。
基于防御性編程的思想,我們做好任何上下游交互的模塊都可能出錯的準備,并提供更高層次的協議保證業務的正確性。例如,在向 MQ 寫入數據時,我們要假定及時 MQ API 返回成功狀態,數據在 MQ 中依然是可能被丟失的,message id 機制也不是100%可靠的。那末,我們如何驗證生產者發送的數據,經過 MQ 以后1定能夠到達消費者?我們需要在生產者和消費者之間建立新的協議。
協議的第1步是為每條數據做1個唯1的標示,即 GUID。更進1步,我們希望 GUID 能夠可讀,并且能表示數據的前后順序。為了滿足這個需求,我們需要1個高可用的能夠產生嚴格遞增的 ID 的服務。這是另外一個很大的話題,在這里不展開。有了這個服務,在生產者發送數據前,先向這個服務要求1個 ID,附加到1條數據上,然后再傳輸。
在消費者端,有兩個方案進行驗證。1個方案是生產者要保證發送到數據 ID 是嚴格遞增的。消費者驗證前后兩條數據的 ID 是不是連續。如果不連續,即認為是數據有丟失,停止繼續消費,通知生產者進行到毛病恢復流程。待生產者恢復后,通知消費者繼續消費。
另外一個方案生產者在發送數據時,除給每條數據附加上自己的 ID,還要附加上其前1條數據的 ID。這樣消費者通過兩個 ID 可以驗證數據是不是有丟失。這個方案的好處是,不需要生產者保證數據的 ID 是連續的。
在實戰中,生產者常常將數據寫入到1個 Topic 的多個 Partition,每一個消費者只消費指定 Partition 的數據,因此同1個 Partition 內的數據 ID 常常是不連續的。因此,這類方案更多的被采用。
實時性
實時性對系統帶來的影響常常弱于準確性。從文章開頭的案例討論可以看出,實時性不好常常也致使業務上的經濟損失,特別在1些流水很大的系統中,可能致使非常可觀的經濟損失。
為了提高實時性,我們1般通過幾個手段:
減少網絡通訊
上下游服務盡可能同機房乃至同機架部署
如果1定出現跨機房(特別是異地機房)的通訊,在機房間使用專線
盡量少地拆分服務是最有效的方法。這需要在系統的擴大性、伸縮性和本錢之間做好權衡,根據業務需要設計方案,避免過度優化。
實時性的另外一個問題是我們如何監控數據的延遲,并在延遲太高的能及時發現并處理。1個常見的方案是使用“哨兵數據”。生產者定期(例如每5分鐘)向 MQ 寫入1條固定格式的數據,這條數據必須包括的字段是數據生成的時間,這條數據成為哨兵數據。消費者需要監控,是不是在經過1個指定的時間間隔能接收到“哨兵數據”。如果接收不到,說明生產者或 MQ 出現了問題。如果接收到了,將數據的生成時間和接收時間做對照,如果時間間隔超越閾值,說明延遲過大。不管哪一種情況,都應當觸發報警,乃至有些依賴于數據流實時性的服務都要同時停止服務。
對絕大多數實時數據流系統來講,可用性、準確性、實時性,3個指標斟酌的是優先級順次下降,實現的代價也是順次增長。在不同的業務場景中,對“可靠”的定義也有所不同。可能有些系統數據丟失1%對業務的影響不大,如果要保證100%準確帶來的本錢會大幅增加;也可能有些系統分鐘級實時和秒級實時對業務的影響不大,但如果從分鐘級提高到秒級本錢會大幅增加。因此,在架構設計中,1定要結合具體業務場景,綜合斟酌和權衡服務質量、用戶體驗、系統本錢等多方面因素。

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


