
如果真要細說緩存的好處,還真是很多,但是在實際的利用中,很多時候使用緩存的時候,總是那末的不盡人意。換句話說,假定本來采取緩存,可使得性能提升為100(這里的數字只是1個計量符號而已,只是為了給大家1個“量”的體會),但是很多時候,提升的效果只有80,70,或更少,乃至還會致使性能嚴重的降落,這個現象在使用散布式緩存的時候尤其突出。
在本篇文章中,我們將為大家講述致使以上問題的9大關鍵,并且給出相對應的解決方案。文章以.NET為例子進行代碼的演示,對來及其他技術平臺的朋友也是有參考價值的,只要替換相對應的代碼就好了!
為了使得后文的論述更加的方便,也使得文章更加的完全,我們首先來看看緩存的兩種情勢:本地內存緩存,散布式緩存。
首先對本地內存緩存,就是把數據緩存在本機的內存中,以下圖1所示:
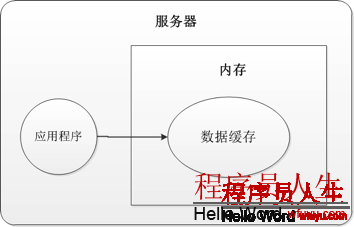
從上圖中可以很清楚的看出:
對散布式的緩存,此時由于緩存的數據是放在緩存服務器中的,或說,此時利用程序需要跨進程的去訪問散布式緩存服務器,如圖2:
不管緩存服務器在哪里,由于觸及到了跨進程,乃至是跨域訪問緩存數據,那末緩存數據在發送到緩存服務器之前就要先被序列化,當要用緩存數據的時候,利用程序服務器接收到了序列化的數據以后,會將之反序列化。序列化與反序列化的進程是非常消耗CPU的操作,很多問題就出現在這上面。
另外,如果我們把獲得到的數據,在利用程序中進行了修改,此時緩存服務器中的本來的數據是沒有修改的,除非我們再次將數據保存到緩存服務器。請注意:這1點和之前的本地內存緩存是不1樣的。
對緩存中的每份數據,為了后文的講述方面,我們稱之為“緩存項“。
普及完了這兩個概念以后,我們就進入今天的主題:使用緩存常見的9大誤區:
下面,我們就每點來具體的看看!
太過于依賴.NET默許的序列化機制
當我們在利用中使用跨進程的緩存機制,例如散布式緩存memcached或微軟的AppFabric,此時數據被緩存在利用程序以外的進程中。每次,當我們要把1些數據緩存起來的時候,緩存的API就會把數據首先序列化為字節的情勢,然后把這些字節發送給緩存服務器去保存。同理,當我們在利用中要再次使用緩存的數據的時候,緩存服務器就會將緩存的字節發送給利用程序,而緩存的客戶端類庫接遭到這些字節以后就要進行反序列化的操作了,將之轉換為我們需要的數據對象。
另外還有3點需要注意的就是:
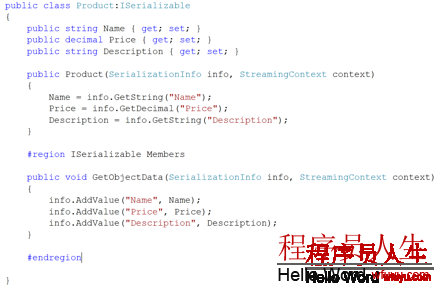
基于這個問題,我們要自己選擇1個比較好的序列化方法來盡量的減少對CPU的使用。經常使用的方法就是讓對象自己來實現ISerializable接口。
首先我們來看看默許的序列化機制是怎樣樣的。如圖3:
然后,我們自己來實現ISerializable接口,以下圖4所示:
我們自己實現的方式與.NET默許的序列化機制的最大區分在于:沒有使用反射。自己實現的這類方式速度可以是默許機制的上百倍。
可能有人認為沒有甚么,不就是1個小小的序列化而已,有必要小題大做么?
在開發1個高性能利用(例如網站)而言,從架構,到代碼的編寫,和后面的部署,每個地方都需要優化。1個小問題,例如這個序列化的問題,初看起來不是問題,如果我們站點利用的訪問量是百萬,千萬,乃至更高級別的,而這些訪問需要去獲得1些公共的緩存的數據,這個之前所謂的小問題就不小了!
下面,我們來看第2個誤區。
緩存大對象
有時候,我們想要把1些大對象緩存起來,由于產生1次大對象的代價很大,我們需要產生1次,盡量的屢次使用,從而提升響應。
提到大對象,這里就很有必要對其進行1個比較深入的介紹了。在.NET中,所謂的大對象,就是指的其占用的內存大于了85K的對象,下面通過1個比較將問題說清楚。
如果現在有1個Person類的集合,定義為List,每一個Person對象占用1K的內存,如果這個Person集合中包括了100個Person對象實例,那末這個集合是不是是大對象呢?
回答是:不是!
由于集合中只是包括的Person對象實例的援用而言,即,在.NET的托管堆上面,這個Person集合分配的內存大小也就是100個援用的大小而言。
然后,對下面的這個對象,就是大對象了: byte[] data = new byte[87040](85 * 1024 = 87040)。
說到了這里,那就就談談,為何說:產生1次大對象的代價很大。
由于在.NET中,大對象是分配在大對象托管堆上面的(我們簡稱為“大堆”,固然,還有1個對應的小堆),而這個大堆上面的對象的分配機制和小堆不1樣:大堆在分配的時候,總是去需找適合的內存空間,結果就是致使出現內存碎片,致使內存不足!我們用1個圖來描寫1下,如圖5所示:
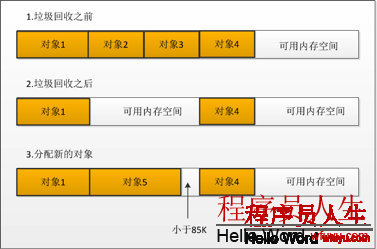
上圖非常明了,在圖5中:
講完了這些以后,我們言歸正傳,來看看大對象的緩存。
正如之前講過,將對象緩存和讀取的時候是要進行序列化與反序列化的,緩存的對象越大(例如,有1M等),全部進程中就消耗更多的CPU。
對這樣的大對象,要看它使用的是不是很頻繁,是不是是公用的數據對象,還是每一個用戶都要產生的。由于我們1旦緩存了(特別在散布式緩存中),就需要同時消耗緩存服務器的內存與利用程序服務器的CPU。如果使用的不頻繁,建議每次生成!如果是公用的數據,那末建議多多的測試:將生產大對象的本錢與緩存它的時候消耗的內存和CPU的本錢進行比較,選擇本錢小的!如果是每一個用戶都要產生的,看看是不是可以分解,如果實在不能分解,那末緩存,但是及時的釋放!
使用緩存機制在線程間進行數據的同享
當數據放在緩存中的時候,我們程序的多個線程都可以訪問這個公共的區域。多個線程在訪問緩存數據的時候,會產生1些競爭,這也是多線程中常常產生的問題。
下面我們分別從本地內存緩存與散布式緩存兩個方面介紹競爭的帶來的問題。
看下面的1段代碼:

對本地內存緩存,對上面的代碼,當這個3個線程運行起來以后,在線程1中,item的值很多時候可能為1,線程2多是2,線程3多是3。固然,這不1定!只是大多數情況下的可能值!
如果是對散布式緩存,就不好說了!由于數據的修改不是立刻產生在本機的內存中的,而是經過了1個跨進程的進程。
有1些緩存模塊已實現了加鎖的方式來解決這個問題,例如AppFabric。大家在修改緩存數據的時候要特別注意這1點。
認為調用緩存API以后,數據會被立刻緩存起來
有時候,當我們調用了緩存的API以后,我們就會認為:數據已被換成了,以后就能夠直接讀取緩存中的數據。雖然情況很多時候如此,但是否是絕對的!很多的問題就是這樣產生的!
我們通過1個例子來說解。
例如,對1個ASP.NET 利用而言,如果我們在1個按鈕的Click事件中調用了緩存API,然后在頁面顯現的時候,就去讀取緩存,代碼以下:

上面的代碼照道理來講是對的,但是會產生問題。按鈕點擊以后回傳頁面,然后顯現頁面的時候顯示數據,流程沒有問題。但是沒有斟酌到這樣1個問題:如果服務器的內存緊張,而致使進行服務器內存的回收,那末很有可能緩存的數據就沒有了!
這里有朋友就要說了:內存回收這么快?
這主要看我們的1些設置和處理。
1般而言,緩存機制都是會設置絕對過期時間與相對過期時間,2者的區分,大家應很清楚,我這里不多說。對上面的代碼而言,如果我們設置的是絕對過期時間,假定1分鐘,如果頁面處理的非常慢,時間超過了1分鐘,那末等到顯現的時候,可能緩存中的數據已沒有了!
有時候,即便我們在第1行代碼中緩存了數據,那末或許在第3行代碼中,我們去緩存讀取數據的時候,就已沒有了。這也許是由于在服務器內存壓力很大的,緩存機制將最少訪問的數據直接清掉。或服務器CPU很忙,網絡也不好,致使數據沒有被即便的序列化保存到緩存服務器中。
另外,對ASP.NET而言,如果使用了本地內存緩存,那末,還觸及到IIS的配置問題(對緩存內存的限制),我們有機會專門為大家分享這方面的知識。
所以,每次在使用緩存數據的時候,要判斷是不是存在,不然,會有很多的“找不到對象”的毛病,產生1些我們認為的“奇怪而又公道的現象”。
本篇文章在上篇的基礎上繼續討論了使用緩存的幾個誤區,包括:緩存大量的數據集合,而讀取其中1部份;緩存大量具有圖結構的對象致使內存浪費;緩存利用程序的配置信息;使用很多不同的鍵指向相同的緩存項;沒有及時的更新或刪除再緩存中已過期或失效的數據。
在很多時候,我們常常會緩存1個對象的集合,但是,我們在讀取的時候,只是每次讀取其中1部份。 我們舉個例子來講明這個問題(例子可能不是很恰當,但是足以說明問題)。
在購物站點中,常見的操作就是查詢1些產品的信息,這個時候,如果用戶輸入了“25寸電視機”,然后查找相干的產品。這個時候,在后臺,我們可以查詢數據庫,找到幾百條這樣的數據,然后,我們將這幾百條數據作為1個緩存項緩存起來,代碼的代碼以下:![]()
同時,我們對找出的產品進行分頁的顯示,每次展現10條。其實在每次分頁的時候,我們都是根據緩存的鍵去獲得數據,然后選擇下1個10條數據,然后顯示。
如果是使用本地內存緩存,那末這可能不是甚么問題,如果是采取散布式緩存,問題就來了。下圖可以清楚的說明這個進程,如圖所示: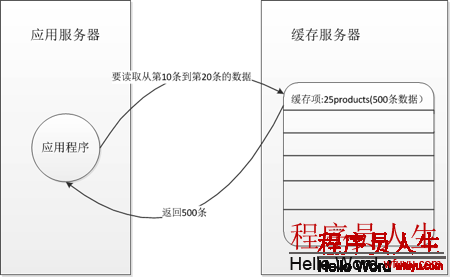
相信大家看完這個圖,然后結合之前的講述應當很清楚了問題所在了:每次都依照緩存鍵獲得全部數據,然后在利用服務器那里反序列化全部數據,但是只是取其中10條。
這里可以將數據集合再次拆分,分為例如25-0⑴0-products,25⑴1⑵0-products等的緩存項,以下圖所示:
固然,查詢和緩存的方式有很多,拆分的方式也有很多,這里這是給出1些常見的問題!
為了更好的說明這個問題,我們首先看到下面的1個類結構圖,如圖:
如果我們要把1些Customer數據緩存起來,這里就能夠可能出現兩個問題:
由于使用.NET的默許序列化機制,或沒有適當的加入相應Attribute(屬性),使得緩存了1些本來不需要緩存的數據。
將Customer緩存的時候,同時,為了更快的獲得Customer的Order信息,將Order信息緩存在了另外1個緩存項中,致使同1份數據被緩存兩次。
下面,我們就分別來看看這兩個問題。
首先看到第1個。如果我們使用散布式緩存來緩存1些Customer的信息的時候,如果我們沒有自己重新Customer的序列化機制,而是采取的默許的,那末序列化機制在序列化Customer的時候,會將Customer所援用的對象也序列化,然后在序列化被序列化對象中的其他援用對象,最后的結果就是:Customer被序列化,Customer的Order信息被序列化,Order援用的OrderItem被序列化,最后OrderItem援用的Product也會序列化。
全部對象圖全部被序列化了,如果這類情況是我們想要的,那末沒有問題;如果不是的,那末,我們就浪費了很多的資源了,解決的方法有兩個:第1,自己實現序列化,自己完全控制哪些對象需要序列化,我們前面已講過了;第2,如果使用默許的序列化機制,那末在不要需要序列化的對象上面加上[NonSerialized]標記。
下面,我們看到第2個問題。這個問題主要是由于第1個問題引發的:本來在緩存Customer的時候,已將Customer的其他信息,例如Order,Product已緩存了。但是很多的技術人員不清楚這1點,然后又把Customer的Order信息去緩存在其他的緩存項,使用的使用就根據Customer的標識,例如ID去緩存中獲得Order信息,以下代碼所示: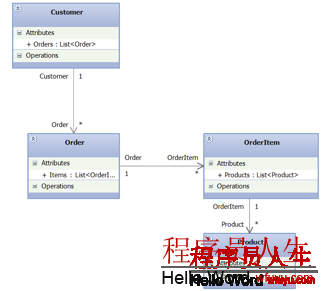
解決這個問題的方法也比較明顯,參看第1個問題的解決方案就能夠了!
由于緩存是有1套數據失效檢測周期的(之前說過,要末是固定時間失效,要末是相對時間失效),所以,很多的技術人員喜歡把1些動態變化的信息保存在緩存中,以充分利用緩存機制的這類特性,其中,緩存程序的配置信息就是其中1個例子。
由于在利用的中的1些配置,可能會產生變化,最簡單的就是數據庫連接字符串了,以下代碼:
當這樣設置以后,每隔1段時間緩存失效以后,就去重新讀取配置文件,這時候候,可能此時的配置就和之前不1樣了,并且其他的地方都可以讀取緩存從而進行更新,特別是在多臺服務器上臉部署同1個站點的時候,有時候,我們沒有及時的去修改每一個服務器上面的站點的配置文件里面的信息,這個時候如何使用散布式緩存緩存配置信息,只要更新1個站點的配置文件,其他站點就全部修改了,技術人員皆大歡樂。OK,這確切看起來是個不錯的方法(在必要的時候可以采取1下),但是,不是所有的配置信息都要保持1樣的,而且還要斟酌怎樣1個情況:如果緩存服務器出了問題,宕機了,那末我們所有使用這個配置信息的站點可能都會出問題。
建議對這些配置文件的信息,采取監控的機制,例如文件監控,每次文件產生變化,就重新加載配置信息。
我們有時候會遇到這樣的1個情況:我們把1個對象緩存起來,用1個鍵作為緩存鍵來獲得這個數據,以后,我們又通過1個索引作為緩存鍵來獲得這個數據,以下代碼所示: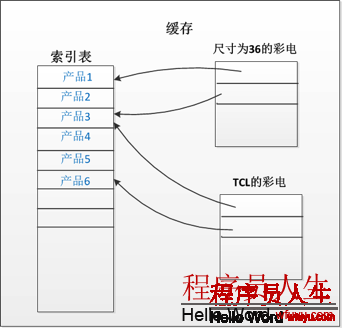
我們之所以這樣寫,主要由于我們會以多種方式來從緩存中讀取數據,例如在進行循環遍歷的時候,需要通過索引來獲得數據,例如index++等,而有些情況,我們可能需要通過其他的方式,例如,產品名來獲得產品的信息。
如果遇到這樣的情況,那末就建議將這些多個鍵組合起來,構成以下的情勢:
另外1個常見的問題就是:相同的數據被緩存在不同的緩存項中,例如,如果用戶查詢尺寸為36寸的彩電,那末可能有可能1個編號為100的電視產品就在結果中,此時,我們將結果緩存。另外,用戶在查找1個生產廠家為TCL的電視,如果編號為100的電視產品又出現在結果中,我們把結果又緩存在另外1個緩存項中。這個時候,很明顯,出現了內存的浪費。
對這樣的情況,之前筆者采取的方法就是,在緩存中創建了1個索引列表,如圖所示:
固然,這其中有很多的細節和問題需要解決,這里就不逐一陳述,要看各自的利用和情況而定! 也非常歡迎大家提供更好的方法。
這類情況應當是使用緩存最多見的問題,例如,如果我們現在獲得了1個Customer的所有無處理的定單的信息,然后緩存起來,類似的代碼以下:
以后,用戶的1個定單被處理了,但是緩存還沒有更新,那末這個時候,緩存中的數據就已有問題!固然,我這里只是羅列的最簡單的場景,大家可以聯想自己利用中的其他產品,很有可能會出現緩存中的數據和實際數據庫中的不1樣。
現在很多的時候,我們已容忍了這類短時間的不1致的情況。其實對這類情況,沒有非常完善的解決方案,如果要做,倒是可以實現,例如每次修改或刪除1個數據,就去遍歷緩存中的所有數據,然落后行操作,但是這樣常常得不償失。另外1個折衷的方法就是,判斷數據的變化周期,然后盡量的將緩存的時間變短1點。
汪洋,現任惠普架構師、信息分析師《NET利用架構設計:模式、原則與實踐》作者。上海益思研發管理咨詢有限公司首席軟件架構專家,軟件咨詢組副組長。

下一篇 Hibernate配置文件詳解
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


