
在具體介紹本文內容之前,先給大家看1下Hadoop業務的整體開發流程:
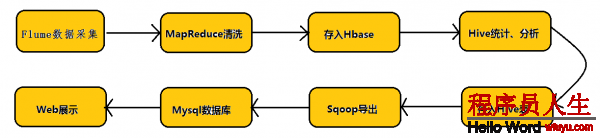
從Hadoop的業務開發流程圖中可以看出,在大數據的業務處理進程中,對數據的收集是10分重要的1步,也是不可避免的1步,從而引出我們本文的主角—Flume。本文將圍繞Flume的架構、Flume的利用(日志收集)進行詳細的介紹。
(1)Flume架構介紹
1、Flume的概念
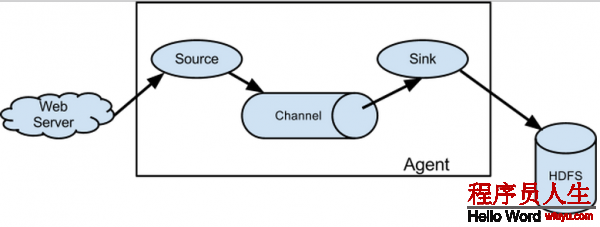
flume是散布式的日志搜集系統,它將各個服務器中的數據搜集起來并送到指定的地方去,比如說送到圖中的HDFS,簡單來講flume就是搜集日志的。
2、Event的概念
在這里有必要先介紹1下flume中event的相干概念:flume的核心是把數據從數據源(source)搜集過來,在將搜集到的數據送到指定的目的地(sink)。為了保證輸送的進程1定成功,在送到目的地(sink)之前,會先緩存數據(channel),待數據真正到達目的地(sink)后,flume在刪除自己緩存的數據。
在全部數據的傳輸的進程中,活動的是event,即事務保證是在event級別進行的。那末甚么是event呢?—–event將傳輸的數據進行封裝,是flume傳輸數據的基本單位,如果是文本文件,通常是1行記錄,event也是事務的基本單位。event從source,流向channel,再到sink,本身為1個字節數組,并可攜帶headers(頭信息)信息。event代表著1個數據的最小完全單元,從外部數據源來,向外部的目的地去。
為了方便大家理解,給出1張event的數據流向圖:
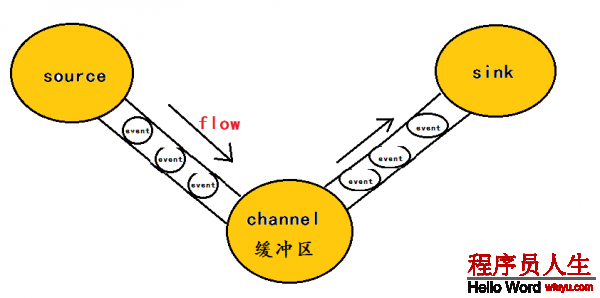
1個完全的event包括:event headers、event body、event信息(即文本文件中的單行記錄),以下所以:

其中event信息就是flume搜集到的日記記錄。
3、flume架構介紹
flume之所以這么奇異,是源于它本身的1個設計,這個設計就是agent,agent本身是1個java進程,運行在日志搜集節點—所謂日志搜集節點就是服務器節點。
agent里面包括3個核心的組件:source—->channel—–>sink,類似生產者、倉庫、消費者的架構。
source:source組件是專門用來搜集數據的,可以處理各種類型、各種格式的日志數據,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定義。
channel:source組件把數據搜集來以后,臨時寄存在channel中,即channel組件在agent中是專門用來寄存臨時數據的——對收集到的數據進行簡單的緩存,可以寄存在memory、jdbc、file等等。
sink:sink組件是用于把數據發送到目的地的組件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定義。
4、flume的運行機制
flume的核心就是1個agent,這個agent對外有兩個進行交互的地方,1個是接受數據的輸入——source,1個是數據的輸出sink,sink負責將數據發送到外部指定的目的地。source接收到數據以后,將數據發送給channel,chanel作為1個數據緩沖區會臨時寄存這些數據,隨后sink會將channel中的數據發送到指定的地方—-例如HDFS等,注意:只有在sink將channel中的數據成功發送出去以后,channel才會將臨時數據進行刪除,這類機制保證了數據傳輸的可靠性與安全性。
5、flume的廣義用法
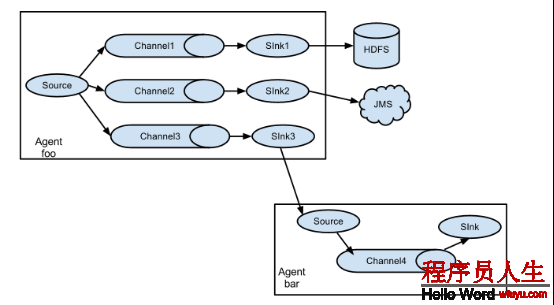
flume之所以這么奇異—-其緣由也在于flume可以支持多級flume的agent,即flume可之前后相繼,例如sink可以將數據寫到下1個agent的source中,這樣的話就能夠連成串了,可以整體處理了。flume還支持扇入(fan-in)、扇出(fan-out)。所謂扇入就是source可以接受多個輸入,所謂扇出就是sink可以將數據輸出多個目的地destination中。
(2)flume利用—日志收集
對flume的原理其實很容易理解,我們更應當掌握flume的具體使用方法,flume提供了大量內置的Source、Channel和Sink類型。而且不同類型的Source、Channel和Sink可以自由組合—–組合方式基于用戶設置的配置文件,非常靈活。比如:Channel可以把事件暫存在內存里,也能夠持久化到本地硬盤上。Sink可以把日志寫入HDFS, HBase,乃至是另外1個Source等等。下面我將用具體的案例詳述flume的具體用法。
其實flume的用法很簡單—-書寫1個配置文件,在配置文件當中描寫source、channel與sink的具體實現,而后運行1個agent實例,在運行agent實例的進程中會讀取配置文件的內容,這樣flume就會收集到數據。
配置文件的編寫原則:
1>從整體上描寫代理agent中sources、sinks、channels所觸及到的組件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c12>詳細描寫agent中每個source、sink與channel的具體實現:即在描寫source的時候,需要
指定source究竟是甚么類型的,即這個source是接受文件的、還是接受http的、還是接受thrift
的;對sink也是同理,需要指定結果是輸出到HDFS中,還是Hbase中啊等等;對channel
需要指定是內存啊,還是數據庫啊,還是文件啊等等。
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1003>通過channel將source與sink連接起來
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1啟動agent的shell操作:
flume-ng agent -n a1 -c ../conf -f ../conf/example.file
-Dflume.root.logger=DEBUG,console 參數說明: -n 指定agent名稱(與配置文件中代理的名字相同)
-c 指定flume中配置文件的目錄
-f 指定配置文件
-Dflume.root.logger=DEBUG,console 設置日志等級
具體案例:
案例1: NetCat Source:監聽1個指定的網絡端口,即只要利用程序向這個端口里面寫數據,這個source組件就能夠獲得到信息。 其中 Sink:logger Channel:memory
flume官網中NetCat Source描寫:
Property Name Default Description
channels –
type – The component type name, needs to be netcat
bind – 日志需要發送到的主機名或Ip地址,該主機運行著netcat類型的source在監聽
port – 日志需要發送到的端口號,該端口號要有netcat類型的source在監聽 a) 編寫配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.80.80
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1b) 啟動flume agent a1 服務端
flume-ng agent -n a1 -c ../conf -f ../conf/netcat.conf -Dflume.root.logger=DEBUG,consolec) 使用telnet發送數據
telnet 192.168.80.80 44444 big data world!(windows中運行的)d) 在控制臺上查看flume搜集到的日志數據:

案例2:NetCat Source:監聽1個指定的網絡端口,即只要利用程序向這個端口里面寫數據,這個source組件就能夠獲得到信息。 其中 Sink:hdfs Channel:file (相比于案例1的兩個變化)
flume官網中HDFS Sink的描寫:
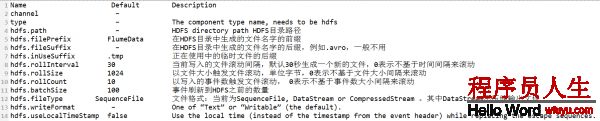
a) 編寫配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.80.80
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop80:9000/dataoutput
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/flume/checkpoint
a1.channels.c1.dataDirs = /usr/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1b) 啟動flume agent a1 服務端
flume-ng agent -n a1 -c ../conf -f ../conf/netcat.conf -Dflume.root.logger=DEBUG,consolec) 使用telnet發送數據
telnet 192.168.80.80 44444 big data world!(windows中運行的)d) 在HDFS中查看flume搜集到的日志數據:
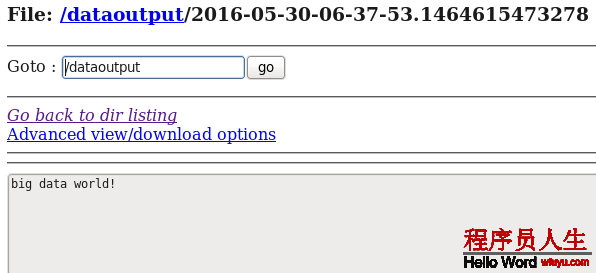
案例3:Spooling Directory Source:監聽1個指定的目錄,即只要利用程序向這個指定的目錄中添加新的文件,source組件就能夠獲得到該信息,并解析該文件的內容,然后寫入到channle。寫入完成后,標記該文件已完成或刪除該文件。其中 Sink:logger Channel:memory
flume官網中Spooling Directory Source描寫:
Property Name Default Description
channels –
type – The component type name, needs to be spooldir.
spoolDir – Spooling Directory Source監聽的目錄
fileSuffix .COMPLETED 文件內容寫入到channel以后,標記該文件
deletePolicy never 文件內容寫入到channel以后的刪除策略: never or immediate
fileHeader false Whether to add a header storing the absolute path filename.
ignorePattern ^$ Regular expression specifying which files to ignore (skip)
interceptors – 指定傳輸中event的head(頭信息),經常使用timestampSpooling Directory Source的兩個注意事項:
①If a file is written to after being placed into the spooling directory, Flume will print an error to its log file and stop processing.
即:拷貝到spool目錄下的文件不可以再打開編輯
②If a file name is reused at a later time, Flume will print an error to its log file and stop processing.
即:不能將具有相同文件名字的文件拷貝到這個目錄下a) 編寫配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/datainput
a1.sources.r1.fileHeader = true
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1b) 啟動flume agent a1 服務端
flume-ng agent -n a1 -c ../conf -f ../conf/spool.conf -Dflume.root.logger=DEBUG,consolec) 使用cp命令向Spooling Directory 中發送數據
cp datafile /usr/local/datainput (注:datafile中的內容為:big data world!)d) 在控制臺上查看flume搜集到的日志數據:

從控制臺顯示的結果可以看出event的頭信息中包括了時間戳信息。
同時我們查看1下Spooling Directory中的datafile信息—-文件內容寫入到channel以后,該文件被標記了:
[root@hadoop80 datainput]# ls
datafile.COMPLETED案例4:Spooling Directory Source:監聽1個指定的目錄,即只要利用程序向這個指定的目錄中添加新的文件,source組件就能夠獲得到該信息,并解析該文件的內容,然后寫入到channle。寫入完成后,標記該文件已完成或刪除該文件。 其中 Sink:hdfs Channel:file (相比于案例3的兩個變化)
a) 編寫配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/datainput
a1.sources.r1.fileHeader = true
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
# Describe the sink
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop80:9000/dataoutput
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/flume/checkpoint
a1.channels.c1.dataDirs = /usr/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1b) 啟動flume agent a1 服務端
flume-ng agent -n a1 -c ../conf -f ../conf/spool.conf -Dflume.root.logger=DEBUG,consolec) 使用cp命令向Spooling Directory 中發送數據
cp datafile /usr/local/datainput (注:datafile中的內容為:big data world!)d) 在控制臺上可以參看sink的運行進度日志:

d) 在HDFS中查看flume搜集到的日志數據:

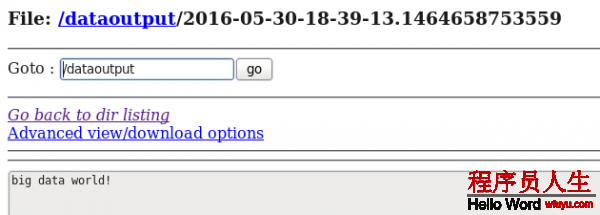
從案例1與案例2、案例3與案例4的對照中我們可以發現:flume的配置文件在編寫的進程中是非常靈活的。
案例5:Exec Source:監聽1個指定的命令,獲得1條命令的結果作為它的數據源
經常使用的是tail -F file指令,即只要利用程序向日志(文件)里面寫數據,source組件就能夠獲得到日志(文件)中最新的內容 。 其中 Sink:hdfs Channel:file
這個案列為了方便顯示Exec Source的運行效果,結合Hive中的external table進行來講明。
a) 編寫配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /usr/local/log.file
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop80:9000/dataoutput
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/flume/checkpoint
a1.channels.c1.dataDirs = /usr/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1b)在hive中建立外部表—–hdfs://hadoop80:9000/dataoutput的目錄,方便查看日志捕獲內容
hive> create external table t1(infor string)
> row format delimited
> fields terminated by '\t'
> location '/dataoutput/';
OK
Time taken: 0.284 secondsc) 啟動flume agent a1 服務端
flume-ng agent -n a1 -c ../conf -f ../conf/exec.conf -Dflume.root.logger=DEBUG,consoled) 使用echo命令向/usr/local/datainput 中發送數據
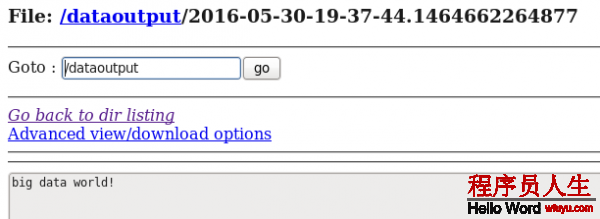
echo big data > log.filed) 在HDFS和Hive分別中查看flume搜集到的日志數據:
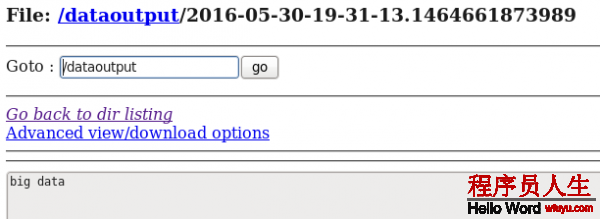
hive> select * from t1;
OK
big data
Time taken: 0.086 secondse)使用echo命令向/usr/local/datainput 中在追加1條數據
echo big data world! >> log.filed) 在HDFS和Hive再次分別中查看flume搜集到的日志數據:
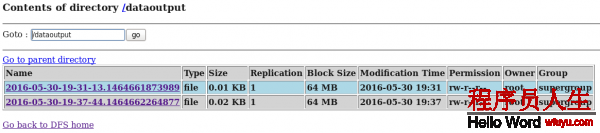
hive> select * from t1;
OK
big data
big data world!
Time taken: 0.511 seconds總結Exec source:Exec source和Spooling Directory Source是兩種經常使用的日志收集的方式,其中Exec source可以實現對日志的實時收集,Spooling Directory Source在對日志的實時收集上稍有欠缺,雖然Exec source可以實現對日志的實時收集,但是當Flume不運行或指令履行出錯時,Exec source將沒法搜集到日志數據,日志會出現丟失,從而沒法保證搜集日志的完全性。
案例6:Avro Source:監聽1個指定的Avro 端口,通過Avro 端口可以獲得到Avro client發送過來的文件 。即只要利用程序通過Avro 端口發送文件,source組件就能夠獲得到該文件中的內容。 其中 Sink:hdfs Channel:file
(注:Avro和Thrift都是1些序列化的網絡端口–通過這些網絡端口可以接受或發送信息,Avro可以發送1個給定的文件給Flume,Avro 源使用AVRO RPC機制)
Avro Source運行原理以下圖:
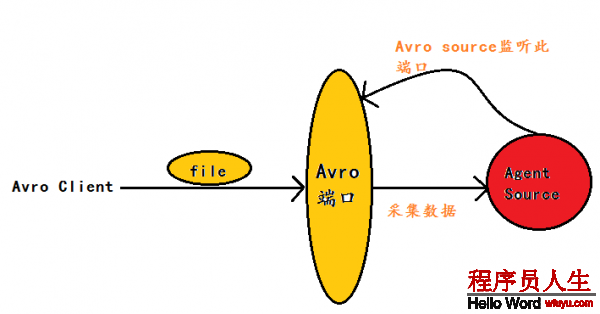
flume官網中Avro Source的描寫:
Property Name Default Description
channels –
type – The component type name, needs to be avro
bind – 日志需要發送到的主機名或ip,該主機運行著ARVO類型的source
port – 日志需要發送到的端口號,該端口要有ARVO類型的source在監聽1)編寫配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.80.80
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop80:9000/dataoutput
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/flume/checkpoint
a1.channels.c1.dataDirs = /usr/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1b) 啟動flume agent a1 服務端
flume-ng agent -n a1 -c ../conf -f ../conf/avro.conf -Dflume.root.logger=DEBUG,consolec)使用avro-client發送文件
flume-ng avro-client -c ../conf -H 192.168.80.80 -p 4141 -F /usr/local/log.file注:log.file文件中的內容為:
[root@hadoop80 local]# more log.file
big data
big data world!d) 在HDFS中查看flume搜集到的日志數據:
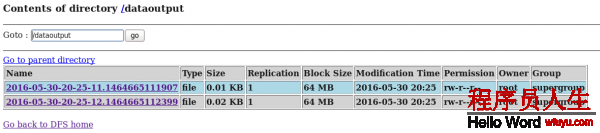
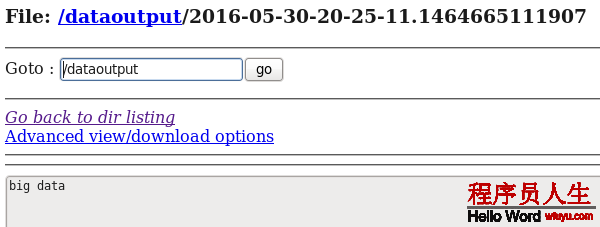
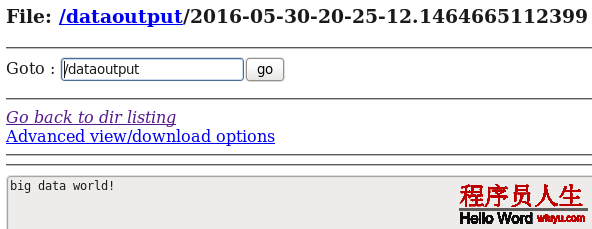
通過上面的幾個案例,我們可以發現:flume配置文件的書寫是相當靈活的—-不同類型的Source、Channel和Sink可以自由組合!
最后對上面用的幾個flume source進行適當總結:
① NetCat Source:監聽1個指定的網絡端口,即只要利用程序向這個端口里面寫數據,這個source組件
就能夠獲得到信息。
②Spooling Directory Source:監聽1個指定的目錄,即只要利用程序向這個指定的目錄中添加新的文
件,source組件就能夠獲得到該信息,并解析該文件的內容,然后寫入到channle。寫入完成后,標記
該文件已完成或刪除該文件。
③Exec Source:監聽1個指定的命令,獲得1條命令的結果作為它的數據源
經常使用的是tail -F file指令,即只要利用程序向日志(文件)里面寫數據,source組件就能夠獲得到日志(文件)中最新的內容 。
④Avro Source:監聽1個指定的Avro 端口,通過Avro 端口可以獲得到Avro client發送過來的文件 。即只要利用程序通過Avro 端口發送文件,source組件就能夠獲得到該文件中的內容。
如有問題,歡迎留言指正!

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


