
上1篇文章主要論述了HDFS Cache緩存方面的知識(shí),本文繼續(xù)帶領(lǐng)大家了解HDFS內(nèi)存存儲(chǔ)相干的內(nèi)容.在HDFS中,CacheAdmin設(shè)置的目標(biāo)文件緩存是會(huì)寄存于DataNode的內(nèi)存中,但是另外1種情況也能夠?qū)?shù)據(jù)寄存在DataNode的內(nèi)存里.就是之前HDFS異構(gòu)存儲(chǔ)中提到的內(nèi)存存儲(chǔ)策略,LAZY_PERSIST.換句話說(shuō),本文也是對(duì)HDFS內(nèi)存存儲(chǔ)策略的1個(gè)更細(xì)致的分析.斟酌到LAZY_PERSIST內(nèi)存存儲(chǔ)與其他存儲(chǔ)策略類(lèi)型的不同的地方,做這樣的1個(gè)分析還是比較成心義的.
對(duì)內(nèi)存存儲(chǔ),可能很多人會(huì)存有這么幾種看法,
仔細(xì)來(lái)看以上這2種觀點(diǎn),其實(shí)都有不小的瑕疵.
首先第1個(gè)觀點(diǎn),服務(wù)1旦停止,內(nèi)存數(shù)據(jù)全丟,這個(gè)是沒(méi)法接受的,我們可以忍耐內(nèi)存中少許的數(shù)據(jù)丟失,但是全丟就不是特別好的處理方式了.而且這個(gè)也有點(diǎn)不公道,內(nèi)存的存儲(chǔ)空間是有限的,如果不及時(shí)存儲(chǔ)1部份數(shù)據(jù),內(nèi)存空間早晚會(huì)耗盡.
然后是第2個(gè)觀點(diǎn),第2個(gè)方案種是在服務(wù)停止退出的時(shí)候做持久化操作,但是他一樣會(huì)面臨上面提到的內(nèi)存空間的限制問(wèn)題.而且假定機(jī)器的內(nèi)存是足夠大的,那末最后寫(xiě)入磁盤(pán)的那個(gè)階段想必也不會(huì)那末快,由于數(shù)據(jù)可能會(huì)很多.
所以1般的通用的比較好的做法是異步的做持久化,甚么意思呢
內(nèi)存存儲(chǔ)新數(shù)據(jù)的同時(shí),持久化距離當(dāng)前時(shí)刻最遠(yuǎn)(存儲(chǔ)時(shí)間最早)的數(shù)據(jù)換1個(gè)通俗的解釋,好比我有個(gè)內(nèi)存數(shù)據(jù)塊隊(duì)列,在隊(duì)列頭部不斷有新增的數(shù)據(jù)塊插入,就是待存儲(chǔ)的塊,由于資源有限 ,我要把隊(duì)列尾部的塊,也就是早些時(shí)間點(diǎn)的塊持久化到磁盤(pán)中,然后才有空間騰出來(lái)存新的塊.然后構(gòu)成這樣的1個(gè)循環(huán),新的塊加入,老的塊移除,保證了整體數(shù)據(jù)的更新.
HDFS的LAZY_PERSIST內(nèi)存存儲(chǔ)策略用的就是這套方法.下面是1張?jiān)韴D:
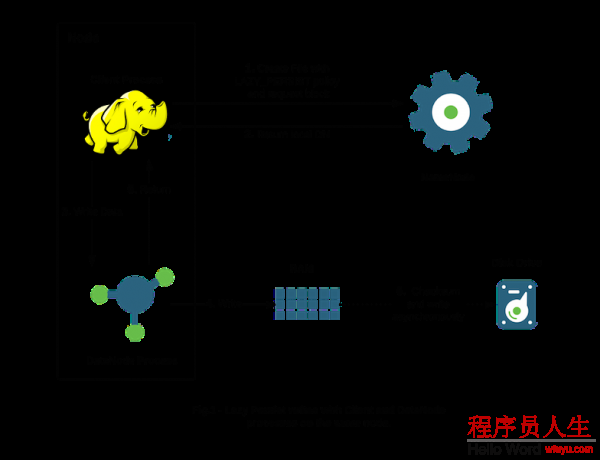
上文描寫(xiě)的原理在圖中的表示實(shí)際上是4,6,的步驟.寫(xiě)數(shù)據(jù)的RAM,然后異步的寫(xiě)到Disk.前面幾個(gè)步驟是如何設(shè)置StorageType的操作,這個(gè)在下文種會(huì)具體提到.所以上圖所示的大體步驟可以歸納為以下:
內(nèi)存的異步持久化存儲(chǔ),就是明顯不同于其他介質(zhì)存儲(chǔ)數(shù)據(jù)的地方.這應(yīng)當(dāng)也是LAZY_PERSIST的名稱(chēng)的源由吧,數(shù)據(jù)不是馬上落盤(pán),而是”lazy persisit”怠惰的方式,延時(shí)的處理.
這里需要了解1個(gè)額外的知識(shí)點(diǎn),Linux 虛擬內(nèi)存盤(pán).之前我也是1直有個(gè)疑惑,內(nèi)存也能夠當(dāng)作1個(gè)塊盤(pán)使用?內(nèi)存不就是臨時(shí)存數(shù)據(jù)用的嗎?因而在學(xué)習(xí)此模塊知識(shí)之前,特地查了相干的資料.其實(shí)在Linux中,可以用將內(nèi)存摹擬為1個(gè)塊盤(pán)的技術(shù),叫RAM disk.這是1種摹擬的盤(pán),實(shí)質(zhì)數(shù)據(jù)都是寄存在內(nèi)存中的.RAM disk虛擬內(nèi)存盤(pán)可以在某些特定的內(nèi)存式存儲(chǔ)文件系統(tǒng)下結(jié)合使用,比如tmpfs,ramfs.關(guān)于tmpfsd百度百科鏈接點(diǎn)此.通過(guò)此項(xiàng)技術(shù),我們就能夠?qū)C(jī)器內(nèi)存利用起來(lái),作為1個(gè)獨(dú)立的虛擬盤(pán)供DataNode使用了.
下面論述的將是本文的核心內(nèi)容,就是HDFS內(nèi)存存儲(chǔ)的主要進(jìn)程操作.不要小視這僅僅是1個(gè)單1的StoragePolicy,里面的進(jìn)程可其實(shí)不簡(jiǎn)單,在下面的進(jìn)程種,我會(huì)給出比較多的進(jìn)程圖的展現(xiàn),幫助大家理解.
要想讓文件數(shù)據(jù)存儲(chǔ)到內(nèi)存中,1開(kāi)始你要做的操作就是設(shè)置此文件的存儲(chǔ)策略,就是上面提到的LAZY_PERSIST,而不是使用默許的StoragePolicy.DEFAULT,默許策略的存儲(chǔ)介質(zhì)是DISK類(lèi)型的.設(shè)置存儲(chǔ)策略的方法目前有2種:
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST方便,快速.
FSDataOutputStream fos =
fs.create(
path,
FsPermission.getFileDefault(),
EnumSet.of(CreateFlag.CREATE, CreateFlag.LAZY_PERSIST),
bufferLength,
replicationFactor,
blockSize,
null);上述方式終究調(diào)用的是DFSClient的create同名方法,以下:
/**
* Call {@link #create(String, FsPermission, EnumSet, boolean, short,
* long, Progressable, int, ChecksumOpt)} with <code>createParent</code>
* set to true.
*/
public DFSOutputStream create(String src, FsPermission permission,
EnumSet<CreateFlag> flag, short replication, long blockSize,
Progressable progress, int buffersize, ChecksumOpt checksumOpt)
throws IOException {
return create(src, permission, flag, true,
replication, blockSize, progress, buffersize, checksumOpt, null);
}方法經(jīng)過(guò)RPC層層調(diào)用,經(jīng)過(guò)FSNamesystem,終究會(huì)到FSDirWriteFileOp的startFile方法,在此方法內(nèi)部,會(huì)有設(shè)置的動(dòng)作
static HdfsFileStatus startFile(
FSNamesystem fsn, FSPermissionChecker pc, String src,
PermissionStatus permissions, String holder, String clientMachine,
EnumSet<CreateFlag> flag, boolean createParent,
short replication, long blockSize,
EncryptionKeyInfo ezInfo, INode.BlocksMapUpdateInfo toRemoveBlocks,
boolean logRetryEntry)
throws IOException {
assert fsn.hasWriteLock();
boolean create = flag.contains(CreateFlag.CREATE);
boolean overwrite = flag.contains(CreateFlag.OVERWRITE);
// 判斷CreateFlag是不是帶有LAZY_PERSIST標(biāo)識(shí),來(lái)判斷是不是是內(nèi)存存儲(chǔ)策略的
boolean isLazyPersist = flag.contains(CreateFlag.LAZY_PERSIST);
...
// 然后在此設(shè)置策略
setNewINodeStoragePolicy(fsd.getBlockManager(), newNode, iip,
isLazyPersist);
fsd.getEditLog().logOpenFile(src, newNode, overwrite, logRetryEntry);
if (NameNode.stateChangeLog.isDebugEnabled()) {
NameNode.stateChangeLog.debug("DIR* NameSystem.startFile: added " +
src + " inode " + newNode.getId() + " " + holder);
}
return FSDirStatAndListingOp.getFileInfo(fsd, src, false, isRawPath);
}所以這部份的進(jìn)程調(diào)用圖以下:

OK,以上就是前期存儲(chǔ)策略的設(shè)置進(jìn)程了,這1部份還是非常的直接明了的.
這里直接跳到DataNode如何進(jìn)行內(nèi)存式存儲(chǔ),當(dāng)我們?cè)O(shè)置了文件為L(zhǎng)AZY_PERSIST的存儲(chǔ)方式以后.我在下面會(huì)進(jìn)行分模塊,分角色的介紹.
在之前的篇幅中已提到過(guò),數(shù)據(jù)存儲(chǔ)的同時(shí)會(huì)有另外1批數(shù)據(jù)會(huì)被異步的持久化,所以這里1定會(huì)觸及到多個(gè)服務(wù)對(duì)象的合作.這些服務(wù)對(duì)象的指揮者是FsDatasetImpl.他是1個(gè)掌管DataNode所有磁盤(pán)讀寫(xiě)數(shù)據(jù)的管家.
在FsDatasetImpl中,與內(nèi)存存儲(chǔ)相干的服務(wù)對(duì)象有以下的3個(gè).
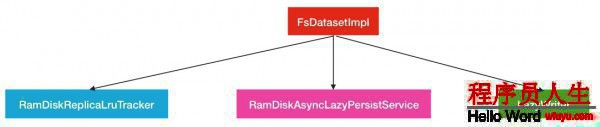
下面來(lái)1個(gè)個(gè)介紹:
LazyWriter:lazyWriter是1個(gè)線程服務(wù),此線程會(huì)不斷的循環(huán)著從數(shù)據(jù)塊列表中取出數(shù)據(jù)塊,加入到異步持久化線程池RamDiskAsyncLazyPersistService中去履行.
RamDiskAsyncLazyPersistService:此對(duì)象就是異步持久化線程服務(wù),里面針對(duì)每個(gè)磁盤(pán)塊設(shè)置1個(gè)對(duì)應(yīng)的線程池,然后需要持久化到給定的磁盤(pán)塊的數(shù)據(jù)塊會(huì)被提交到對(duì)應(yīng)的線程池中去.每一個(gè)線程池的最大線程數(shù)為1.
RamDiskReplicaLruTracker:副本塊跟蹤類(lèi),此類(lèi)種保護(hù)了所有已持久化,未持久化的副本和總副本數(shù)據(jù)信息.所以當(dāng)1個(gè)副本被終究存儲(chǔ)到內(nèi)存種后,相應(yīng)的會(huì)有副本所屬隊(duì)列信息的變更.其次當(dāng)節(jié)點(diǎn)內(nèi)存不足的時(shí)候,部份距離最近最久沒(méi)有被訪問(wèn)的副本塊會(huì)在此類(lèi)中被移除.
綜合了以上3者的緊密合作,終究實(shí)現(xiàn)了HDFS的內(nèi)存存儲(chǔ).下面是具體的角色介紹.
在以上3者中,RamDiskReplicaLruTracker的角色起到了1個(gè)中間人的角色.由于他內(nèi)部保護(hù)了多個(gè)關(guān)系的數(shù)據(jù)塊信息.主要的就是以下3類(lèi).
public class RamDiskReplicaLruTracker extends RamDiskReplicaTracker {
...
/**
* Map of blockpool ID to <map of blockID to ReplicaInfo>.
*/
Map<String, Map<Long, RamDiskReplicaLru>> replicaMaps;
/**
* Queue of replicas that need to be written to disk.
* Stale entries are GC'd by dequeueNextReplicaToPersist.
*/
Queue<RamDiskReplicaLru> replicasNotPersisted;
/**
* Map of persisted replicas ordered by their last use times.
*/
TreeMultimap<Long, RamDiskReplicaLru> replicasPersisted;
...這里的Queue就是待內(nèi)存存儲(chǔ)隊(duì)列.以上3個(gè)變量之間的關(guān)系圖以下
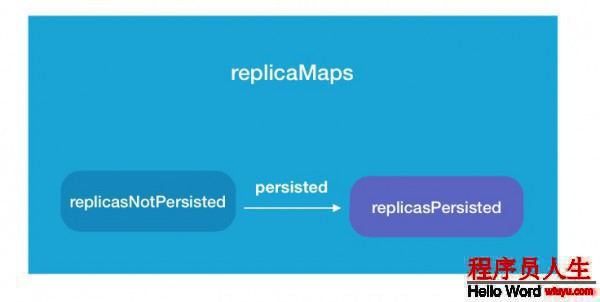
RamDiskReplicaLruTracker中的方法操作絕大多數(shù)與這3個(gè)變量的增刪改動(dòng)相干,所以邏輯其實(shí)不復(fù)雜,我們只需要了解這些方法有甚么作用便可.我對(duì)此分成了2類(lèi):
第1類(lèi),異步持久化操作相干方法.如圖:
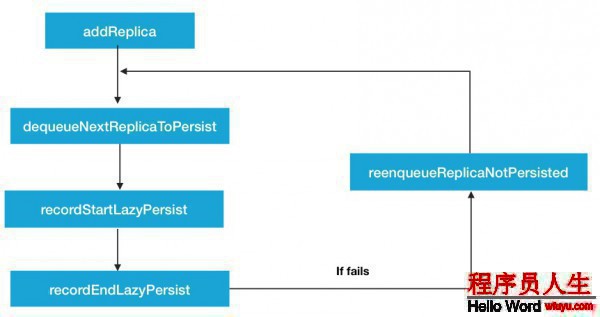
當(dāng)節(jié)點(diǎn)重啟或有新的文件被設(shè)置了LAZY_PERSIST策略后,就會(huì)有新的副本塊被存儲(chǔ)到內(nèi)存中,同時(shí)會(huì)加入到replicaNotPersisted隊(duì)列中.然后經(jīng)過(guò)中間的dequeueNextReplicaToPersist取出下1個(gè)將被持久化的副本塊,進(jìn)行寫(xiě)磁盤(pán)的操作.recordStartLazyPersist,recordEndLazyPersist這2個(gè)方法會(huì)在持久化的進(jìn)程中被調(diào)用,標(biāo)志著持久化狀態(tài)的變更.
另外一類(lèi),異步持久化操作無(wú)直接關(guān)聯(lián)方法.如圖:

有下面3個(gè)方法:
這里反復(fù)提到1個(gè)名詞,LRU,他的全稱(chēng)是Least Recently Used,意為最近最少使用算法,相干鏈接點(diǎn)此,getNextCandidateForEviction采取此算法的好處是保證了現(xiàn)有副本塊的1個(gè)活躍度,把最近很久沒(méi)有訪問(wèn)過(guò)的給移除掉.對(duì)這個(gè)操作,我們有必要了解其中的細(xì)節(jié).
先是touch會(huì)更新最近訪問(wèn)的時(shí)間
synchronized void touch(final String bpid,
final long blockId) {
Map<Long, RamDiskReplicaLru> map = replicaMaps.get(bpid);
RamDiskReplicaLru ramDiskReplicaLru = map.get(blockId);
...
// Reinsert the replica with its new timestamp.
// 更新最近訪問(wèn)時(shí)間戳,并重新插入數(shù)據(jù)
if (replicasPersisted.remove(ramDiskReplicaLru.lastUsedTime, ramDiskReplicaLru)) {
ramDiskReplicaLru.lastUsedTime = Time.monotonicNow();
replicasPersisted.put(ramDiskReplicaLru.lastUsedTime, ramDiskReplicaLru);
}
}然后是第2步獲得候選移除塊
synchronized RamDiskReplicaLru getNextCandidateForEviction() {
// 獲得replicasPersisted迭代器進(jìn)行遍歷
final Iterator<RamDiskReplicaLru> it = replicasPersisted.values().iterator();
while (it.hasNext()) {
// 由于replicasPersisted已根據(jù)時(shí)間排好序了,所以取出當(dāng)前的塊進(jìn)行移除便可
final RamDiskReplicaLru ramDiskReplicaLru = it.next();
it.remove();
Map<Long, RamDiskReplicaLru> replicaMap =
replicaMaps.get(ramDiskReplicaLru.getBlockPoolId());
if (replicaMap != null && replicaMap.get(ramDiskReplicaLru.getBlockId()) != null) {
return ramDiskReplicaLru;
}
// The replica no longer exists, look for the next one.
}
return null;
}這里比較成心思的是,根據(jù)已持久化的塊的訪問(wèn)時(shí)間來(lái)進(jìn)行挑選移除,而不是直接是內(nèi)存中的塊.最后是在內(nèi)存中移除與候選塊屬于同1副本信息的塊并釋放內(nèi)存空間.
/**
* Attempt to evict one or more transient block replicas until we
* have at least bytesNeeded bytes free.
*/
public void evictBlocks(long bytesNeeded) throws IOException {
int iterations = 0;
final long cacheCapacity = cacheManager.getCacheCapacity();
// 當(dāng)檢測(cè)到內(nèi)存空間不滿足外界需要的大小時(shí)
while (iterations++ < MAX_BLOCK_EVICTIONS_PER_ITERATION &&
(cacheCapacity - cacheManager.getCacheUsed()) < bytesNeeded) {
// 獲得待移除副本信息
RamDiskReplica replicaState = ramDiskReplicaTracker.getNextCandidateForEviction();
if (replicaState == null) {
break;
}
if (LOG.isDebugEnabled()) {
LOG.debug("Evicting block " + replicaState);
}
...
// 移除內(nèi)存中的相干塊并釋放空間
// Delete the block+meta files from RAM disk and release locked
// memory.
removeOldReplica(replicaInfo, newReplicaInfo, blockFile, metaFile,
blockFileUsed, metaFileUsed, bpid);
}
}
}LazyWriter是1個(gè)線程服務(wù),他是1個(gè)發(fā)動(dòng)機(jī),循環(huán)不斷的從隊(duì)列中取出待持久化的數(shù)據(jù)塊,提交到異步持久化服務(wù)中去.直接來(lái)看主要的run方法.
public void run() {
int numSuccessiveFailures = 0;
while (fsRunning && shouldRun) {
try {
// 取出新的副本塊并提交到異步服務(wù)中,返回是不是提交成功布爾值
numSuccessiveFailures = saveNextReplica() ? 0 : (numSuccessiveFailures + 1);
// Sleep if we have no more work to do or if it looks like we are not
// making any forward progress. This is to ensure that if all persist
// operations are failing we don't keep retrying them in a tight loop.
if (numSuccessiveFailures >= ramDiskReplicaTracker.numReplicasNotPersisted()) {
Thread.sleep(checkpointerInterval * 1000);
numSuccessiveFailures = 0;
}
} catch (InterruptedException e) {
LOG.info("LazyWriter was interrupted, exiting");
break;
} catch (Exception e) {
LOG.warn("Ignoring exception in LazyWriter:", e);
}
}
}進(jìn)入saveNextReplica方法的處理
private boolean saveNextReplica() {
RamDiskReplica block = null;
FsVolumeReference targetReference;
FsVolumeImpl targetVolume;
ReplicaInfo replicaInfo;
boolean succeeded = false;
try {
// 從隊(duì)列種取出新的待持久化的塊
block = ramDiskReplicaTracker.dequeueNextReplicaToPersist();
if (block != null) {
synchronized (FsDatasetImpl.this) {
...
// 提交到異步服務(wù)中去
asyncLazyPersistService.submitLazyPersistTask(
block.getBlockPoolId(), block.getBlockId(),
replicaInfo.getGenerationStamp(), block.getCreationTime(),
replicaInfo.getMetaFile(), replicaInfo.getBlockFile(),
targetReference);
}
}
}
succeeded = true;
} catch(IOException ioe) {
LOG.warn("Exception saving replica " + block, ioe);
} finally {
if (!succeeded && block != null) {
LOG.warn("Failed to save replica " + block + ". re-enqueueing it.");
onFailLazyPersist(block.getBlockPoolId(), block.getBlockId());
}
}
return succeeded;
}所以LazyWriter線程服務(wù)的流程圖可以歸納為以下所示:
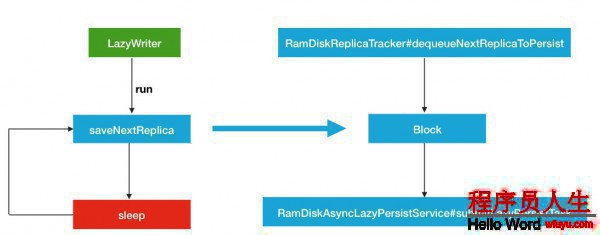
然后我們結(jié)合LazyWriter和RamDiskReplicaTracker跟蹤服務(wù),就能夠得到下面1個(gè)完全的流程(暫且不斟酌RamDiskAsyncLazyPersistService的內(nèi)部履行邏輯).
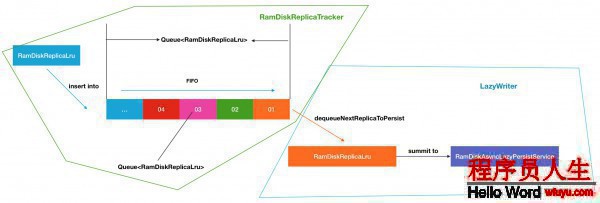
最后1部份的異步服務(wù)的內(nèi)容相對(duì)就比較簡(jiǎn)單1些了,主要圍繞著Volume磁盤(pán)和Executor線程池這2部份的內(nèi)容.秉承著下面1個(gè)原則
1個(gè)磁盤(pán)服務(wù)對(duì)應(yīng)1個(gè)線程池,并且1個(gè)線程池的最大線程數(shù)也只有1個(gè).線程池列表定義以下
class RamDiskAsyncLazyPersistService {
...
private Map<File, ThreadPoolExecutor> executors
= new HashMap<File, ThreadPoolExecutor>();
...這里的File代表的是1個(gè)獨(dú)立的磁盤(pán)所在目錄,個(gè)人認(rèn)為這里完全可以用String字符串替換.既可以減少存儲(chǔ)空間,又直觀明了.所以在這里就能夠看出是1對(duì)1的關(guān)系了.
當(dāng)服務(wù)啟動(dòng)的時(shí)候,就會(huì)有新的磁盤(pán)目錄加入.
synchronized void addVolume(File volume) {
if (executors == null) {
throw new RuntimeException("AsyncLazyPersistService is already shutdown");
}
ThreadPoolExecutor executor = executors.get(volume);
// 如果當(dāng)前已存在此磁盤(pán)目錄對(duì)應(yīng)的線程池,則跑異常
if (executor != null) {
throw new RuntimeException("Volume " + volume + " is already existed.");
}
// 否則進(jìn)行添加
addExecutorForVolume(volume);
}進(jìn)入addExecutorForVolume方法
private void addExecutorForVolume(final File volume) {
...
// 新建線程池,最大線程履行數(shù)為
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_THREADS_PER_VOLUME, MAXIMUM_THREADS_PER_VOLUME,
THREADS_KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(), threadFactory);
// This can reduce the number of running threads
executor.allowCoreThreadTimeOut(true);
// 加入到executors中,以為volume作為key
executors.put(volume, executor);
}還有1個(gè)需要注意的是提交履行方法submitLazyPersistTask.
void submitLazyPersistTask(String bpId, long blockId,
long genStamp, long creationTime,
File metaFile, File blockFile,
FsVolumeReference target) throws IOException {
if (LOG.isDebugEnabled()) {
LOG.debug("LazyWriter schedule async task to persist RamDisk block pool id: "
+ bpId + " block id: " + blockId);
}
// 獲得需要持久化到目標(biāo)磁盤(pán)實(shí)例
FsVolumeImpl volume = (FsVolumeImpl)target.getVolume();
File lazyPersistDir = volume.getLazyPersistDir(bpId);
if (!lazyPersistDir.exists() && !lazyPersistDir.mkdirs()) {
FsDatasetImpl.LOG.warn("LazyWriter failed to create " + lazyPersistDir);
throw new IOException("LazyWriter fail to find or create lazy persist dir: "
+ lazyPersistDir.toString());
}
// 新建此服務(wù)Task
ReplicaLazyPersistTask lazyPersistTask = new ReplicaLazyPersistTask(
bpId, blockId, genStamp, creationTime, blockFile, metaFile,
target, lazyPersistDir);
// 提交到對(duì)應(yīng)volume的線程池中履行
execute(volume.getCurrentDir(), lazyPersistTask);
}如果在上述履行的進(jìn)程中產(chǎn)生失敗,會(huì)調(diào)用失敗處理的方法,并會(huì)重新將此副本塊插入到replicateNotPersisted隊(duì)列等待下1次的持久化.
public void onFailLazyPersist(String bpId, long blockId) {
RamDiskReplica block = null;
block = ramDiskReplicaTracker.getReplica(bpId, blockId);
if (block != null) {
LOG.warn("Failed to save replica " + block + ". re-enqueueing it.");
// 重新插入隊(duì)列操作
ramDiskReplicaTracker.reenqueueReplicaNotPersisted(block);
}
}其他的removeVolume等方法實(shí)現(xiàn)比較簡(jiǎn)單,這里不做過(guò)量的介紹.下面是RamDiskAsyncLazyPersistService總的結(jié)構(gòu)圖:
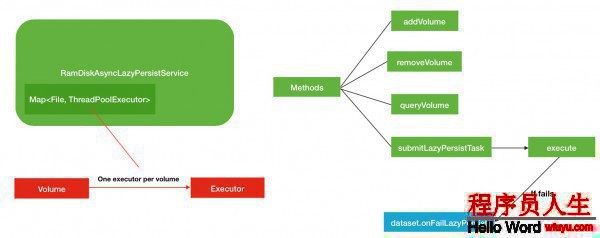
綜合以上3部份的內(nèi)容論述,主要描寫(xiě)了LAZT_PERSIST下的FIFO先進(jìn)先出的隊(duì)列式內(nèi)存數(shù)據(jù)塊持久化的順序,異步持久化服務(wù)的內(nèi)部運(yùn)行邏輯和LRU算法移除數(shù)據(jù)副本塊來(lái)預(yù)留內(nèi)存空間.
介紹完以上原理部份的內(nèi)容以后,最后補(bǔ)充具體的配置使用了.
首先要使用LAZY_PERSIST內(nèi)存存儲(chǔ)策略,需要有對(duì)應(yīng)的存儲(chǔ)介質(zhì),內(nèi)存存儲(chǔ)介質(zhì)對(duì)應(yīng)的類(lèi)型是RAM_DISK.
所以第1步,需要將機(jī)器中已完成好的RAM disk虛擬內(nèi)存盤(pán)配置到配置項(xiàng)dfs.datanode.data.dir中,其次還要帶上,RAM_DISK的標(biāo)簽.以下:
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>注意,這個(gè)標(biāo)簽是必須要打上的,否則HDFS都默許的是DISK.
第2步就是設(shè)置具體的文件的策略類(lèi)型了,上文中已提到過(guò)了.
然后附帶2個(gè)注意事項(xiàng):
1.http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/MemoryStorage.html
2.百度百科.tmpfs
3.百度百科.RAM disk
4.百度百科.LRU算法

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


