初識Dubbo 系列之8-Dubbo 集群容錯
來源:程序員人生 發布時間:2015-08-14 09:08:09 閱讀次數:4663次
集群容錯
(+) (#)
 |
在集群調用失敗時,Dubbo提供了多種容錯方案,缺省為failover重試。 |
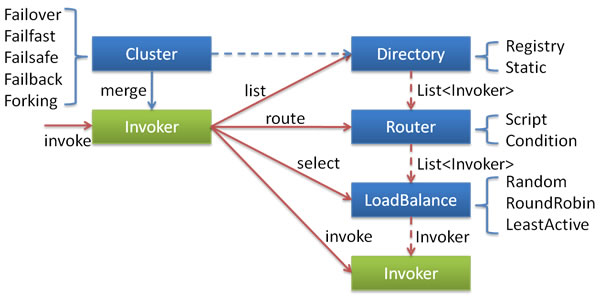
各節點關系:
- 這里的Invoker是Provider的1個可調用Service的抽象,Invoker封裝了Provider地址及Service接口信息。
- Directory代表多個Invoker,可以把它看成List<Invoker>,但與List不同的是,它的值多是動態變化的,比如注冊中心推送變更。
- Cluster將Directory中的多個Invoker假裝成1個Invoker,對上層透明,假裝進程包括了容錯邏輯,調用失敗后,重試另外一個。
- Router負責從多個Invoker中按路由規則選出子集,比如讀寫分離,利用隔離等。
- LoadBalance負責從多個Invoker當選出具體的1個用于本次調用,選的進程包括了負載均衡算法,調用失敗后,需要重選。
集群容錯模式:
可以自行擴大集群容錯策略,參見:集群擴大
Failover Cluster
- 失敗自動切換,當出現失敗,重試其它服務器。(缺省)
- 通經常使用于讀操作,但重試會帶來更長延遲。
- 可通過retries="2"來設置重試次數(不含第1次)。
Failfast Cluster
- 快速失敗,只發起1次調用,失敗立即報錯。
- 通經常使用于非冪等性的寫操作,比如新增記錄。
Failsafe Cluster
- 失敗安全,出現異常時,直接疏忽。
- 通經常使用于寫入審計日志等操作。
Failback Cluster
- 失敗自動恢復,后臺記錄失敗要求,定時重發。
- 通經常使用于消息通知操作。
Forking Cluster
- 并行調用多個服務器,只要1個成功即返回。
- 通經常使用于實時性要求較高的讀操作,但需要浪費更多服務資源。
- 可通過forks="2"來設置最大并行數。
Broadcast Cluster
- 廣播調用所有提供者,逐一調用,任意1臺報錯則報錯。(2.1.0開始支持)
- 通經常使用于通知所有提供者更新緩存或日志等本地資源信息。
重試次數配置如:(failover集群模式生效)
<dubbo:service
retries="2"
/>
|
或:
<dubbo:reference
retries="2"
/>
|
或:
<dubbo:reference>
<dubbo:method
name="findFoo"
retries="2"
/>
</dubbo:reference>
|
集群模式配置如:
<dubbo:service
cluster="failsafe"
/>
|
或:
<dubbo:reference
cluster="failsafe"
/>
|
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈

------分隔線----------------------------
------分隔線----------------------------



