
task complexity包括step complexity(可以并行成幾個(gè)操作) & work complexity(總共有多少個(gè)工作要做)。
e.g. 下面的tree-structure圖中每一個(gè)節(jié)點(diǎn)表示1個(gè)操作數(shù),每條邊表示1個(gè)操作,同層edge表示相同操作,問該圖表示的task的step complexity & work complexity分別是多少。
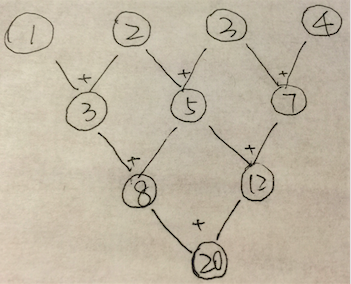
Ans:
step complexity: 3;
work complexity: 6。
下面會(huì)有更具體的例子。
__global__ void parallel_reduce_kernel(float *d_out, float* d_in){
int myID = threadIdx.x + blockIdx.x * blockDim.x;
int tid = threadIdx.x;
//divide threads into two parts according to threadID, and add the right part to the left one, lead to reducing half elements, called an iteration; iterate until left only one element
for(unsigned int s = blockDim.x / 2 ; s>0; s>>1){
if(tid<s){
d_in[myID] += d_in[myID + s];
}
__syncthreads(); //ensure all adds at one iteration are done
}
if (tid == 0){
d_out[blockIdx.x] = d_in[myId];
}
}__global__ void parallel_shared_reduce_kernel(float *d_out, float* d_in){
int myID = threadIdx.x + blockIdx.x * blockDim.x;
int tid = threadIdx.x;
extern __shared__ float sdata[];
sdata[tid] = d_in[myID];
__syncthreads();
//divide threads into two parts according to threadID, and add the right part to the left one, lead to reducing half elements, called an iteration; iterate until left only one element
for(unsigned int s = blockDim.x / 2 ; s>0; s>>1){
if(tid<s){
sdata[myID] += sdata[myID + s];
}
__syncthreads(); //ensure all adds at one iteration are done
}
if (tid == 0){
d_out[blockIdx.x] = sdata[myId];
}
}kernel<<<grid of blocks, block of threads, shmem>>>parallel_reduce_kernel<<<blocks, threads, threads*sizeof(float)>>>(data_out, data_in);parallel_reduce_kernel| Times | Read Ops | Write Ops |
| 1 | 1024 | 512 |
| 2 | 512 | 256 |
| 3 | 256 | 128 |
| … | ||
| n | 1 | 1 |
parallel_shared_reduce_kernel| Times | Read Ops | Write Ops |
| 1 | 1024 | 1 |
所以,parallel_reduce_kernel所需的帶寬是parallel_shared_reduce_kernel的3倍。
Example:
目的:解決難以并行的問題
拍拍腦袋想一想上面這個(gè)問題O(n)的1個(gè)解法是out[i] = out[i⑴] + in[i].下面我們來引入scan。
Inputs to scan:
| op | Identity |
| 加法 | 0 |
| 乘法 | 1 |
| 邏輯或|| | False |
| 邏輯與&& | True |
| I/O | content | ||||
|---|---|---|---|---|---|
| input | [ |
… | |||
| output | [ |
… |
其中
很簡(jiǎn)單:
int acc = identity;
for(i=0;i<elements.length();i++){
acc = acc op elements[i];
out[i] = acc;
}work complexity:
step complexity:
那末,對(duì)scan問題,我們?cè)鯓訉?duì)其進(jìn)行并行化呢?
斟酌scan的并行化,可以并行計(jì)算n個(gè)output,每一個(gè)output元素i相當(dāng)于
Q: 那末問題的work complexity和step complexity分別變成多少了呢?
Ans:
可見,step complexity降下來了,惋惜work complexity上去了,那末怎樣解決呢?這里有兩種Scan算法:
| more step efficiency | more work efficiency | |
| hillis + steele (1986) | √ | |
| blelloch (1990) | √ |
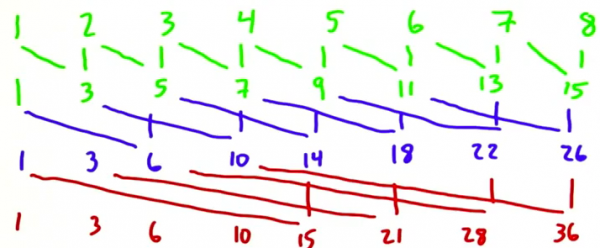
即streaming’s
step 0: out[i] = in[i] + in[i⑴];
step 1: out[i] = in[i] + in[i⑵];
step 2: out[i] = in[i] + in[i⑷];
如果元素不存在(向下越界)就記為0;可見step 2的output就是scan 加法的結(jié)果(想一想為何,我們1會(huì)再分析)。
那末問題來了。。。
Q: hillis + steele算法的work complexity 和 step complexity分別為多少?
| O(n^2) | |||||
| work complexity | √ | ||||
| step complexity | √ |
解釋:
為了無(wú)妨礙大家思路,我在表格中將答案設(shè)為了白色,選中表格可見答案。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


