
原文地址: http://www.lanceyan.com/tech/arch/snscrawler.html
隨著B(niǎo)IG DATA大數(shù)據(jù)概念逐步升溫,如何搭建1個(gè)能夠收集海量數(shù)據(jù)的架構(gòu)體系擺在大家眼前。如何能夠做到所見(jiàn)即所得的無(wú)阻止式收集、如何快速把不規(guī)則頁(yè)面結(jié)構(gòu)化并存儲(chǔ)、如何滿足愈來(lái)愈多的數(shù)據(jù)收集還要在有限時(shí)間內(nèi)收集。這篇文章結(jié)合我們本身項(xiàng)目經(jīng)驗(yàn)談1下。
我們來(lái)看1下作為人是怎樣獲得網(wǎng)頁(yè)數(shù)據(jù)的呢?
1、打開(kāi)閱讀器,輸入網(wǎng)址url訪問(wèn)頁(yè)面內(nèi)容。
2、復(fù)制頁(yè)面內(nèi)容的標(biāo)題、作者、內(nèi)容。
3、存儲(chǔ)到文本文件或excel。
從技術(shù)角度來(lái)講全部進(jìn)程主要為 網(wǎng)絡(luò)訪問(wèn)、扣取結(jié)構(gòu)化數(shù)據(jù)、存儲(chǔ)。我們看1下用java程序如何來(lái)實(shí)現(xiàn)這1進(jìn)程。
通過(guò)這個(gè)例子,我們看到通過(guò)httpclient獲得數(shù)據(jù),通過(guò)字符串操作扣取標(biāo)題內(nèi)容,然后通過(guò)system.out輸出內(nèi)容。大家是否是感覺(jué)做1個(gè)爬蟲(chóng)也還是蠻簡(jiǎn)單呢。這是1個(gè)基本的入門例子,我們?cè)僭敿?xì)介紹怎樣1步1步構(gòu)建1個(gè)散布式的適用于海量數(shù)據(jù)收集的爬蟲(chóng)框架。
全部框架應(yīng)當(dāng)包括以下部份,資源管理、反監(jiān)控管理、抓取管理、監(jiān)控管理。看1下全部框架的架構(gòu)圖:
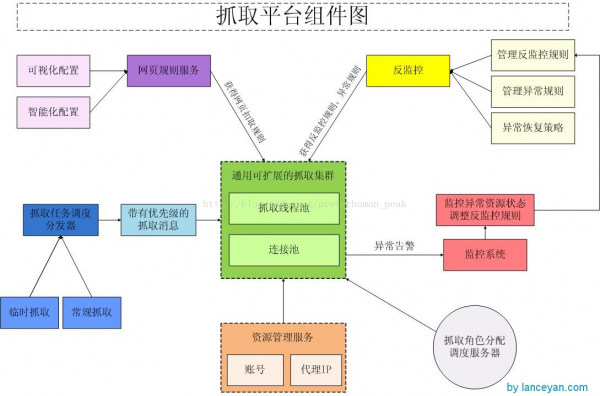
反監(jiān)控管理指被訪問(wèn)網(wǎng)站(特別是社會(huì)化媒體)會(huì)制止爬蟲(chóng)訪問(wèn),怎樣讓他們不能監(jiān)控到我們的訪問(wèn)時(shí)爬蟲(chóng)軟件,這就是反監(jiān)控機(jī)制了;
1個(gè)好的收集框架,不管我們的目標(biāo)數(shù)據(jù)在哪兒,只要用戶能夠看到都應(yīng)當(dāng)能收集到。所見(jiàn)即所得的無(wú)阻止式收集,不管是不是需要登錄的數(shù)據(jù)都能夠順利收集。現(xiàn)在大部份社交網(wǎng)站都需要登錄,為了應(yīng)對(duì)登錄的網(wǎng)站要有摹擬用戶登錄的爬蟲(chóng)系統(tǒng),才能正常獲得數(shù)據(jù)。不過(guò)社會(huì)化網(wǎng)站都希望自己構(gòu)成1個(gè)閉環(huán),不愿意把數(shù)據(jù)放到站外,這類系統(tǒng)也不會(huì)像新聞等內(nèi)容那末開(kāi)放的讓人獲得。這些社會(huì)化網(wǎng)站大部份會(huì)采取1些限制避免機(jī)器人爬蟲(chóng)系統(tǒng)爬取數(shù)據(jù),1般1個(gè)賬號(hào)爬取不了多久就會(huì)被檢測(cè)出來(lái)被制止訪問(wèn)了。那是否是我們就不能爬取這些網(wǎng)站的數(shù)據(jù)呢?肯定不是這樣的,只要社會(huì)化網(wǎng)站不關(guān)閉網(wǎng)頁(yè)訪問(wèn),正常人能夠訪問(wèn)的數(shù)據(jù),我們也能訪問(wèn)。說(shuō)到底就是摹擬人的正常行動(dòng)操作,專業(yè)1點(diǎn)叫“反監(jiān)控”。
那1般網(wǎng)站會(huì)有甚么限制呢?
1定時(shí)間內(nèi)單IP訪問(wèn)次數(shù),沒(méi)有哪一個(gè)人會(huì)在1段延續(xù)時(shí)間內(nèi)過(guò)快訪問(wèn),除非是隨便的點(diǎn)著玩,延續(xù)時(shí)間也不會(huì)太長(zhǎng)。可以采取大量不規(guī)則代理IP來(lái)摹擬。
1定時(shí)間內(nèi)單賬號(hào)訪問(wèn)次數(shù),這個(gè)同上,正常人不會(huì)這么操作。可以采取大量行動(dòng)正常的賬號(hào),行動(dòng)正常就是普通人怎樣在社交網(wǎng)站上操作,如果1個(gè)人1天24小時(shí)都在訪問(wèn)1個(gè)數(shù)據(jù)接口那就有多是機(jī)器人了。
如果能把賬號(hào)和IP的訪問(wèn)策略控制好了,基本可以解決這個(gè)問(wèn)題了。固然對(duì)方網(wǎng)站也會(huì)有運(yùn)維會(huì)調(diào)劑策略,說(shuō)到底這是1個(gè)戰(zhàn)爭(zhēng),躲在電腦屏幕后的敵我雙方,爬蟲(chóng)必須要能感知到對(duì)方的反監(jiān)控策略進(jìn)行了調(diào)劑,通知管理員及時(shí)處理。未來(lái)比較理想應(yīng)當(dāng)是通過(guò)機(jī)器學(xué)習(xí)算法自動(dòng)完成策略調(diào)劑,保證抓取不中斷。
抓取管理指通過(guò)url,結(jié)合資源、反監(jiān)控抓取數(shù)據(jù)并存儲(chǔ);我們現(xiàn)在大部份爬蟲(chóng)系統(tǒng),很多都需要自己設(shè)定正則表達(dá)式,或使用htmlparser、jsoup等軟件來(lái)硬編碼解決結(jié)構(gòu)化抓取的問(wèn)題。不過(guò)大家在做爬蟲(chóng)也會(huì)發(fā)現(xiàn),如果爬取1個(gè)網(wǎng)站就去開(kāi)發(fā)1個(gè)類,在范圍小的時(shí)候還可以接受,如果需要抓取的網(wǎng)站不計(jì)其數(shù),那我們不是要開(kāi)發(fā)成百上千的類。為此我們開(kāi)發(fā)了1個(gè)通用的抓取類,可以通過(guò)參數(shù)驅(qū)動(dòng)內(nèi)部邏輯調(diào)度。比如我們?cè)趨?shù)里指定抓取新浪微博,抓取機(jī)器就會(huì)調(diào)度新浪微博網(wǎng)頁(yè)扣取規(guī)則抓取節(jié)點(diǎn)數(shù)據(jù),調(diào)用存儲(chǔ)規(guī)則存儲(chǔ)數(shù)據(jù),不管甚么類型最后都調(diào)用同1個(gè)類來(lái)處理。對(duì)我們用戶只需要設(shè)置抓取規(guī)則,相應(yīng)的后續(xù)處理就交給抓取平臺(tái)了。
全部抓取使用了 xpath、正則表達(dá)式、消息中間件、多線程調(diào)度框架(參考)。xpath 是1種結(jié)構(gòu)化網(wǎng)頁(yè)元素選擇器,支持列表和單節(jié)點(diǎn)數(shù)據(jù)獲得,他的好處可以支持規(guī)整網(wǎng)頁(yè)數(shù)據(jù)抓取。我們使用的是google插件 XPath Helper,這個(gè)玩意可以支持在網(wǎng)頁(yè)點(diǎn)擊元素生成xpath,就省去了自己去查找xpath的工夫,也便于未來(lái)做到所點(diǎn)即所得的功能。正則表達(dá)式補(bǔ)充xpath抓取不到的數(shù)據(jù),還可以過(guò)濾1些特殊字符。消息中間件,起到抓取任務(wù)中間轉(zhuǎn)發(fā)的目的,避免抓取和各個(gè)需求方耦合。比如各個(gè)業(yè)務(wù)系統(tǒng)都可能抓取數(shù)據(jù),只需要向消息中間件發(fā)送1個(gè)抓取指令,抓取平臺(tái)抓完了會(huì)返回1條消息給消息中間件,業(yè)務(wù)系統(tǒng)在從消息中間件收到消息反饋,全部抓取完成。多線程調(diào)度框架之條件到過(guò),我們的抓取平臺(tái)不可能在同1時(shí)刻只抓1個(gè)消息的任務(wù);也不可能無(wú)窮制抓取,這樣資源會(huì)耗盡,致使惡性循環(huán)。這就需要使用多線程調(diào)度框架來(lái)調(diào)度多線程任務(wù)并行抓取,并且任務(wù)的數(shù)量,保證資源的消耗正常。
不管怎樣摹擬總還是會(huì)有異常的,這就需要有個(gè)異常處理模塊,有些網(wǎng)站訪問(wèn)1段時(shí)間需要輸入驗(yàn)證碼,如果不處理后續(xù)永久返回不了正確數(shù)據(jù)。我們需要有機(jī)制能夠處理像驗(yàn)證碼這類異常,簡(jiǎn)單就是有驗(yàn)證碼了人為去輸入,高級(jí)1些可以破解驗(yàn)證碼辨認(rèn)算法實(shí)現(xiàn)自動(dòng)輸入驗(yàn)證碼的目的。
擴(kuò)大1下 :所見(jiàn)即所得我們是否是真的做到?規(guī)則配置也是個(gè)重復(fù)的大任務(wù)?重復(fù)網(wǎng)頁(yè)如何不抓取?
1、有些網(wǎng)站利用js生成網(wǎng)頁(yè)內(nèi)容,直接查看源代碼是1堆js。 可使用mozilla、webkit等可以解析閱讀器的工具包解析js、ajax,不過(guò)速度會(huì)有點(diǎn)慢。
2、網(wǎng)頁(yè)里有1些css隱藏的文字。使用工具包把css隱藏文字去掉。
3、圖片flash信息。 如果是圖片中文字辨認(rèn),這個(gè)比較好處理,能夠使用ocr辨認(rèn)文字就行,如果是flash目前只能存儲(chǔ)全部url。
4、1個(gè)網(wǎng)頁(yè)有多個(gè)網(wǎng)頁(yè)結(jié)構(gòu)。如果只有1套抓取規(guī)則肯定不行的,需要多個(gè)規(guī)則配合抓取。
5、html不完全,不完全就不能依照正常模式去扣取。這個(gè)時(shí)候用xpath肯定解析不了,我們可以先用htmlcleaner清洗網(wǎng)頁(yè)后再解析。
6、 如果網(wǎng)站多起來(lái),規(guī)則配置這個(gè)工作量也會(huì)非常大。如何幫助系統(tǒng)快速生成規(guī)則呢?首先可以配置規(guī)則可以通過(guò)可視化配置,比如用戶在看到的網(wǎng)頁(yè)想對(duì)它抓取數(shù)據(jù),只需要拉開(kāi)插件點(diǎn)擊需要的地方,規(guī)則就自動(dòng)生成好了。另在量比較大的時(shí)候可視化還是不夠的,可以先將類型相同的網(wǎng)站歸類,再通過(guò)抓取的1些內(nèi)容聚類,可以統(tǒng)計(jì)學(xué)、可視化抓取把內(nèi)容扣取出幾個(gè)版本給用戶去糾正,最后確認(rèn)的規(guī)則就是新網(wǎng)站的規(guī)則。這些算法后續(xù)再講。這塊再補(bǔ)充1下(多謝zicjin建議):
背景:如果我們需要抓取的網(wǎng)站很多,那如果靠可視化配置需要耗費(fèi)大量的人力,這是個(gè)本錢。并且這個(gè)交給不懂html的業(yè)務(wù)去配置準(zhǔn)確性值得考量,所以最后還是需要技術(shù)做很多事情。那我們能否通過(guò)技術(shù)手段可以幫助生成規(guī)則減少人力本錢,或幫助不懂技術(shù)的業(yè)務(wù)準(zhǔn)確的把數(shù)據(jù)扣取下來(lái)并大量復(fù)制。
方案:先對(duì)網(wǎng)站分類,比如分為新聞、論壇、視頻等,這1類網(wǎng)站的網(wǎng)頁(yè)結(jié)構(gòu)是類似的。在業(yè)務(wù)打開(kāi)需要扣取的還沒(méi)有錄入我們規(guī)則庫(kù)的網(wǎng)頁(yè)時(shí),他先設(shè)定這個(gè)頁(yè)面的分類(固然這個(gè)也能夠機(jī)器預(yù)先判斷,他們來(lái)選擇,這1步必須要人判斷下),有了分類后,我們會(huì)通過(guò)“統(tǒng)計(jì)學(xué)、可視化判斷”辨認(rèn)這1分類的字段規(guī)則,但是這個(gè)是機(jī)器辨認(rèn)的規(guī)則,可能不準(zhǔn)確,機(jī)器辨認(rèn)完后,還需要人在判斷1下。判斷完成后,最后構(gòu)成規(guī)則才是新網(wǎng)站的規(guī)則
7、對(duì)付重復(fù)的網(wǎng)頁(yè),如果重復(fù)抓取會(huì)浪費(fèi)資源,如果不抓需要1個(gè)海量的去重判斷緩存。判斷抓不抓,抓了后存不存,并且這個(gè)緩存需要快速讀寫。常見(jiàn)的做法有bloomfilter、相似度聚合、分類海明距離判斷。
目前這樣的框架搭建起來(lái)基本可以解決大量的抓取需求了。通過(guò)界面可以管理資源、反監(jiān)控規(guī)則、網(wǎng)頁(yè)扣取規(guī)則、消息中間件狀態(tài)、數(shù)據(jù)監(jiān)控圖表,并且可以通過(guò)后臺(tái)調(diào)劑資源分配并能動(dòng)態(tài)更新保證抓取不斷電。不過(guò)如果1個(gè)任務(wù)的處理特別大,可能需要抓取24個(gè)小時(shí)或幾天。比如我們要抓取1條微博的轉(zhuǎn)發(fā),這個(gè)轉(zhuǎn)發(fā)是30w,那如果每頁(yè)線性去抓取耗時(shí)肯定是非常慢了,如果能把這30w拆分很多小任務(wù),那我們的并行計(jì)算能力就會(huì)提高很多。不能不提的就是把大型的抓取任務(wù)hadoop化,空話不說(shuō)直接上圖:


上一篇 RDIFramework.NET ━ .NET快速信息化系統(tǒng)開(kāi)發(fā)框架 V2.8 版本━新增企業(yè)通(內(nèi)部簡(jiǎn)易聊天工具)
下一篇 安徽科技學(xué)院2014-2015-1學(xué)期計(jì)算機(jī)14級(jí)12班《C語(yǔ)言程序設(shè)計(jì)I》期末考試
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


