
從今天開始,開始研究學習Hadoop Common相干的源碼結(jié)構(gòu)。Hadoop Common在Hadoop1.0中是在core包下面的。此包下面的內(nèi)容供HDFS和MapReduce公用,所以作用還是非常大的。Hadoop Common模塊下的內(nèi)容是比較多的。本人打算在后面的學習中挑選部份模塊進行分析學習,比如他的序列化框架的實現(xiàn),RPC的實現(xiàn)等等。我對此模塊截出了1些圖:
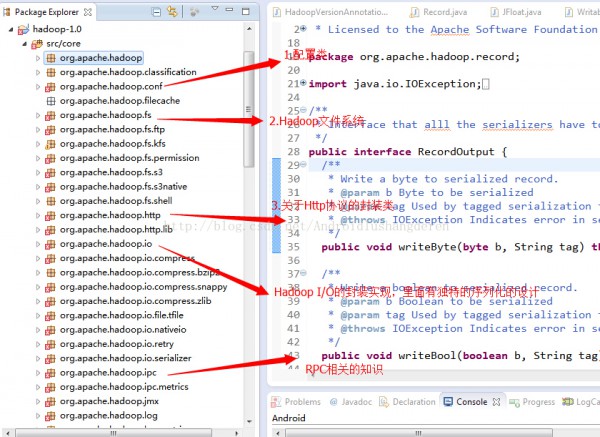
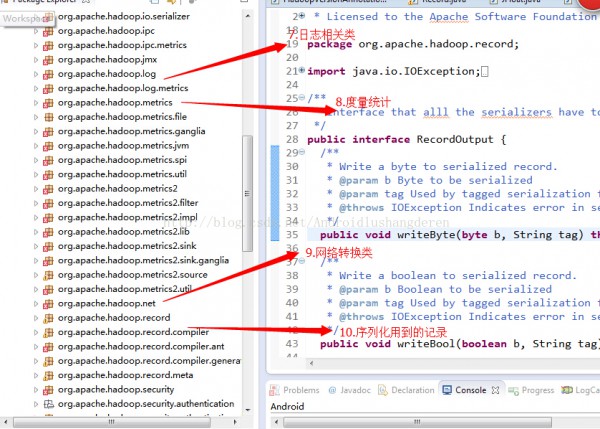
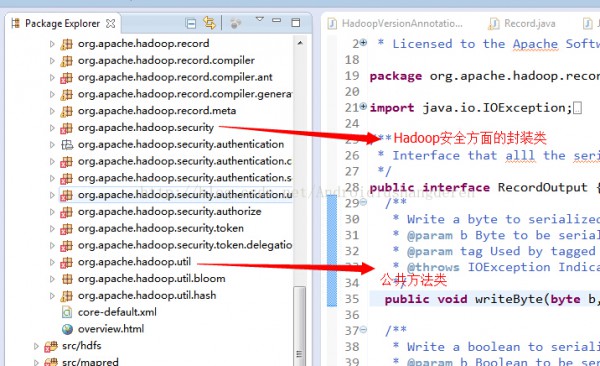
程序包下的主要模塊關(guān)系圖:
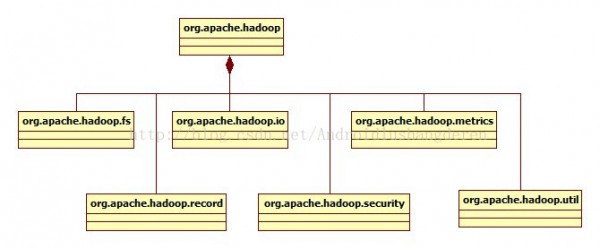
下面分模塊,做1下簡短的概述
1.org.apache.hadoop.conf,配置相干類,配置類在Hadoop中1直都是1個比較基本類,很多配置設(shè)置的數(shù)據(jù)都需要從配置文件中去讀取。Hadoop中配置文件還挺多的,HDFS和MapReduce各1個,還會用用戶自定義的配置文件。系統(tǒng)開放了許多的get/set方法來獲得和設(shè)置其中的屬性。
2.org.apache.hadoop.fs,Hadoop文件系統(tǒng),從Hadoop的文件系統(tǒng)中,或許你會看到Linux文件系統(tǒng)的影子,里面包括了很多文件File的各種基本操作,還有很多在文件中特殊的操作實現(xiàn),比如權(quán)限控制,目錄,文件通過甚么來組織,Hadoop文件系統(tǒng)弄了1個和VFS虛擬文件系統(tǒng)非常像的1個抽象文件系統(tǒng),基于這個Hadoop抽象文件系統(tǒng),派生了很多具體具有各個功能的文件子系統(tǒng),比如內(nèi)存文件系統(tǒng),校驗和系統(tǒng)。
3.org.apache.hadoop.io,Hadoop I/O系統(tǒng),輸入輸出系統(tǒng)在任何1個系統(tǒng)都是非常重要的設(shè)計,一樣在Hadoop中,在此上面實現(xiàn)了1個獨有的序列化系統(tǒng),不同于java自帶的序列化實現(xiàn),Hadoop的序列化機制具有快速,緊湊的特點,非常合適于Hadoop的使用處景。還有1個就是Hadoop的在I/O中的解緊縮的設(shè)計,里面還可以通過JNI的情勢調(diào)用第3方的比較優(yōu)秀的緊縮算法,比如Google的Snappy框架。
4.org.apache.hadoop.ipc,Hadoop遠程進程調(diào)用的實現(xiàn),這個模塊的設(shè)計是有很多值得學習的好地方,java的RPC最直接的體現(xiàn)就是RMI的實現(xiàn),RMI的實現(xiàn)就是1個簡陋版本的遠程進程調(diào)用,但是由于JMI的不可定制性,所以Hadoop根據(jù)自己系統(tǒng)特點,重新設(shè)計了1套獨有的RPC體系,在java NIO的基礎(chǔ)上,用了java動態(tài)代理的思想,RPC的服務端和客戶端都是通過代理取得方式獲得。
其他包的1些內(nèi)容我簡單的描寫,org.apache.hadoop.log,日志幫助類,實現(xiàn)估值的檢測和恢復,org.apache.hadoop.metrics,用于度量統(tǒng)計用的,主要用于分析的,至于具體怎樣做的,本人也不是特別了解,org.apache.hadoop.http和org.apache.hadoop.net是Hadoop對網(wǎng)絡層次相干的封裝,最后要提到的就是org.apache.hadoop.util就是在Common中的公共方法類,checkSum校驗和的驗證方法就包括于此。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學習,原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


