Python2 爬蟲(六) -- 初嘗Scrapy框架
來源:程序員人生 發布時間:2016-06-24 13:46:33 閱讀次數:4864次
1、Scrapy簡介
Scrapy是1個為了爬取網站數據,提取結構性數據而編寫的利用框架。 可以利用在包括數據發掘,信息處理或存儲歷史數據等1系列的程序中。
其最初是為了 頁面抓取 (更確切來講, 網絡抓取 )所設計的, 也能夠利用在獲得API所返回的數據(例如 Amazon Associates Web Services ) 或通用的網絡爬蟲。
Scrapy官網文檔 -- 戳我
本來我是基于Python3.5學習爬蟲的,但是Python3.x不支持Scrapy框架。即使不支持,也不能就此放棄這個強大的框架,因而轉戰Ubuntu,搭建Python2.7環境,安裝Scrapy,開始學習~~~
2、環境搭建
【1】系統Ubuntu 15
【2】Python版本 -- 2.7 & 3.4 , 安裝pip工具
我的Ubuntu系統上安裝了Python2.7和Python3.4兩個版本,但是默許配置仍然是2.7。
【3】安裝Scrapy
使用命令(apt-get install python-scrapy)或(pip install scrapy)安裝:
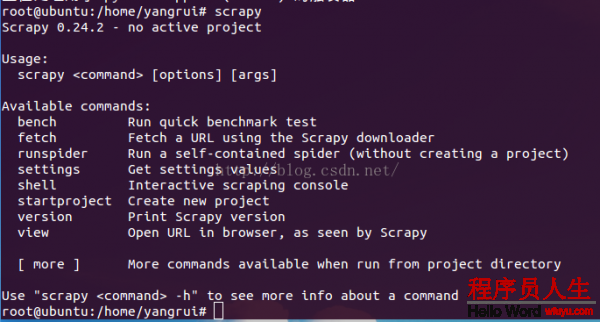
驗證安裝完成:
出現上圖內容,說明正確安裝Scrapy。其實Scrapy框架依賴setuptools,lxml,和OpenSSL軟件,但是Ubuntu中Python2.7已內置安裝,所以,1個簡單的命令便可完成Scrapy框架的配置,非常簡便。
至此,Scrapy已配置完成,下面開始我們的第1個Scrapy爬蟲項目吧。
3、第1個Scrapy爬蟲實例
此實例源于官網(Scrapy入門教程)。
3.1 開發步驟
接下來以 Open Directory Project(dmoz) (dmoz) 為例來說述爬取。
- 創建1個Scrapy項目
- 定義提取的Item
- 編寫爬取網站的 spider 并提取 Item
- 編寫 Item Pipeline 來存儲提取到的Item(即數據)
3.2 創建項目
在開始爬取之前,您必須創建1個新的Scrapy項目。 進入您打算存儲代碼的目錄中,運行以下命令:
scrapy startproject tutorial
該命令將會創建包括以下內容的 tutorial 目錄:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
這些文件分別是:
- scrapy.cfg: 項目的配置文件.
- tutorial/: 該項目的python模塊。以后您將在此加入代碼.
- tutorial/items.py: 項目中的item文件.
- tutorial/pipelines.py: 項目中的pipelines文件.
- tutorial/settings.py: 項目的設置文件.
- tutorial/spiders/: 放置spider代碼的目錄.
3.3 定義Item
Item 是保存爬取到的數據的容器;其使用方法和python字典類似, 并且提供了額外保護機制來避免拼寫毛病致使的未定義字段毛病。item可以用scrapy.item.Item類來創建,并且用scrapy.item.Field對象來定義屬性(可以理解成類似于ORM的映照關系)。
類似在ORM中做的1樣,您可以通過創建1個 scrapy.Item 類, 并且定義類型為 scrapy.Field 的類屬性來定義1個Item。
首先根據需要從dmoz.org獲得到的數據對item進行建模。 我們需要從dmoz中獲得名字,url,和網站的描寫。 對此,在item中定義相應的字段。編輯 tutorial 目錄中的 items.py 文件,添加類DmozItem:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
3.4 編寫第1個爬蟲
Spider是用戶編寫用于從單個網站(或1些網站)爬取數據的類。
其包括了1個用于下載的初始URL,如何跟進網頁中的鏈接和如何分析頁面中的內容, 提取生成 item 的方法。
為了創建1個Spider,您必須繼承 scrapy.Spider 類, 且定義以下3個屬性:
- name: 用于區分Spider。 該名字必須是唯1的,您不可以為不同的Spider設定相同的名字。
- start_urls: 包括了Spider在啟動時進行爬取的url列表。 因此,第1個被獲得到的頁面將是其中之1。 后續的URL則從初始的URL獲得到的數據中提取。
- parse() 是spider的1個方法。 被調用時,每一個初始URL完成下載后生成的 Response 對象將會作為唯1的參數傳遞給該函數。 該方法負責解析返回的數據(response data),提取數據(生成item)和生成需要進1步處理的URL的 Request 對象。
以下為我們的第1個Spider代碼,保存在 tutorial/spiders 目錄下的 dmoz_spider.py 文件中:
import scrapy
class DmozSpider(scrapy.spiders.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[⑵]
with open(filename, 'wb') as f:
f.write(response.body)
3.4.1 爬取
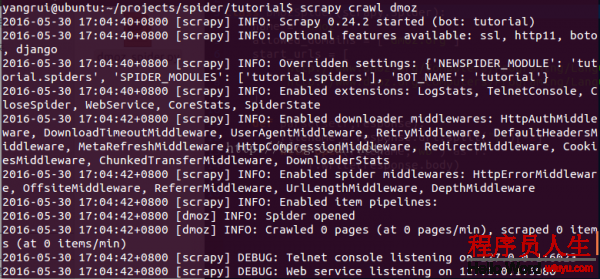
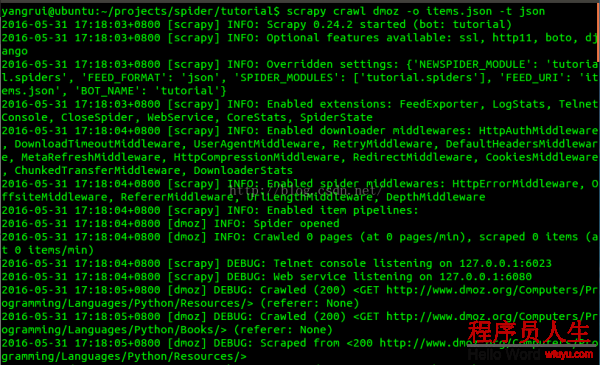
在項目的根目錄輸入命令(scrapy crawl dmoz)運行我們的爬蟲,得到結果:
...中間省略
最后1句INFO: Closing spider (finished)表明爬蟲已成功運行并且自行關閉了。
查看包括 [dmoz] 的輸出,可以看到輸出的log中包括定義在 start_urls 的初始URL,并且與spider中是逐一對應的。在log中可以看到其沒有指向其他頁面( (referer:None) )。
那末,剛才產生了甚么?
首先,Scrapy為Spider的 start_urls 屬性中的每一個URL創建了 scrapy.Request 對象,并將 parse 方法作為回調函數(callback)賦值給了Request。
然后,Request對象經過調度,履行生成 scrapy.http.Response 對象并送回給spider parse() 方法。
3.4.2 使用XPath
Selectors選擇器簡介:
從網頁中提取數據有很多方法。Scrapy使用了1種基于 XPath 和 CSS 表達式機制: Scrapy Selectors 。 關于selector和其他提取機制的信息請參考 Selector文檔 。
這里給出XPath表達式的例子及對應的含義:
- /html/head/title: 選擇HTML文檔中 <head> 標簽內的 <title> 元素
- /html/head/title/text(): 選擇上面提到的 <title> 元素的文字
- //td: 選擇所有的 <td> 元素
- //div[@class="mine"]: 選擇所有具有 class="mine" 屬性的 div 元素
為了配合XPath,Scrapy除提供了 Selector 以外,還提供了方法來避免每次從response中提取數據時生成selector的麻煩。
Selector有4個基本的方法:
- xpath(): 傳入xpath表達式,返回該表達式所對應的所有節點的selector list列表 。
- css(): 傳入CSS表達式,返回該表達式所對應的所有節點的selector list列表。
- extract(): 序列化該節點為unicode字符串并返回list。
- re(): 根據傳入的正則表達式對數據進行提取,返回unicode字符串list列表。
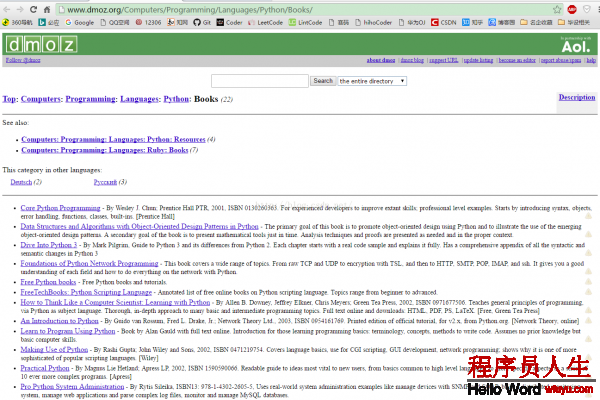
首先,先查看1下我們需要爬取的網頁http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
然后,在Shell中嘗試Selector選擇器
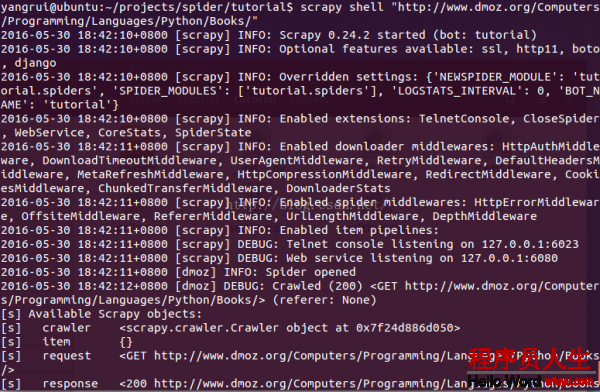
為了介紹Selector的使用方法,接下來我們將要使用內置的 Scrapy shell 。Scrapy Shell需要您預裝好IPython(1個擴大的Python終端)。進入項目的根目錄,履行以下命令來啟動shell:
scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"
當shell載入后,您將得到1個包括response數據的本地 response 變量。輸入 response.body 將輸出response的包體, 輸出 response.headers 可以看到response的包頭。
更加重要的是,當輸入 response.selector 時, 您將獲得到1個可以用于查詢返回數據的selector(選擇器), 和映照到 response.selector.xpath() 、 response.selector.css() 的 快捷方法(shortcut): response.xpath() 和 response.css() 。
同時,shell根據response提早初始化了變量 sel 。該selector根據response的類型自動選擇最適合的分析規則(XML vs HTML)。
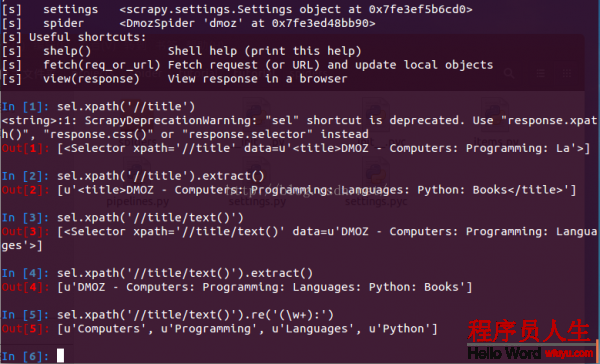
讓我們來試試:
xpath路徑表達式(說明):
表達式 描寫
nodename 選取此節點的所有子節點。
/ 從根節點選取。
// 從匹配選擇確當前節點選擇文檔中的節點,而不斟酌它們的位置。
. 選取當前節點。
.. 選取當前節點的父節點。
@ 選取屬性。
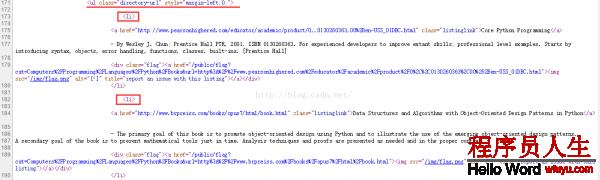
3.4.3 查看網頁源代碼,提取有用數據
在查看了網頁的源碼后,您會發現網站的信息是被包括在 第2個 <ul> 元素中。
我們可以通過這段代碼選擇該頁面中網站列表里所有 <li> 元素:
sel.xpath('//ul/li')
網站的描寫:
sel.xpath('//ul/li/text()').extract()
網站的標題:
sel.xpath('//ul/li/a/text()').extract()
和網站的鏈接:
sel.xpath('//ul/li/a/@href').extract()
之條件到過,每一個 .xpath() 調用返回selector組成的list,因此我們可以拼接更多的 .xpath() 來進1步獲得某個節點。我們將在下邊使用這樣的特性:
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title, link, desc
3.4.4 修改dmoz_spider.py中DmozSpider類的代碼:
# -*- coding: UTF⑻ -*-
import scrapy,sys
from scrapy.spider import Spider
from scrapy.selector import Selector
from tutorial.items import DmozItem
#設置編碼格式
reload(sys)
sys.setdefaultencoding('gbk')
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
"""
The lines below is a spider contract. For more info see:
http://doc.scrapy.org/en/latest/topics/contracts.html
@url http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/
@scrapes name
"""
sel = Selector(response)
sites = sel.xpath('//ul/li')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract()
disc = site.xpath('text()').extract()
print("title= "+str(title)+"\tlink= "+str(link)+"\tdisc= "+str(disc)+"\n")
說明:
- 代碼中的中文注釋,首句添加# -*- coding: UTF⑻ -*- 避免出現編碼毛病
- 若有寫文件操作添加代碼sys.setdefaultencoding('gbk'),設置編碼格式
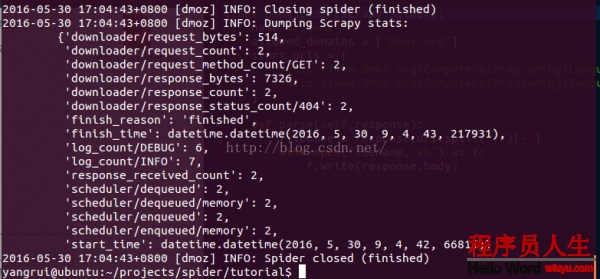
在項目的根目錄輸入命令(scrapy crawl dmoz)運行我們的爬蟲,得到結果:
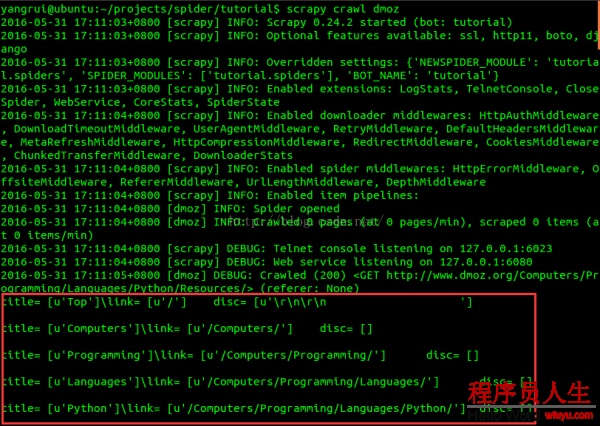
...省略
對照網站內容,我們發現網頁頂層的Top和Python部份也被抓取出來,我們把這部份過濾掉。根據網頁源代碼發現,我們所要提取的目標信息是從 <ul class="directory-url"...開始的。再次修改代碼:
sites = sel.xpath('//ul[@class="directory-url"]/li')
重新運行會發現此時已將Top和Python部份過濾掉了。
3.5 使用Item提取,并保存至dmoz.json
3.5.1 使用Item
Item 對象是自定義的python字典。 您可使用標準的字典語法來獲得到其每一個字段的值。(字段即是我們之前用Field賦值的屬性):
>>> item = DmozItem()
>>> item['title'] = 'Example title'
>>> item['title']
'Example title'
1般來講,Spider將會將爬取到的數據以 Item 對象返回。所以為了將爬取的數據返回,修改dmoz_spider.py中DmozSpider類的代碼:
# -*- coding: UTF⑻ -*-
import scrapy
from scrapy.spider import Spider
from scrapy.selector import Selector
from tutorial.items import DmozItem
#設置編碼格式
reload(sys)
sys.setdefaultencoding('gbk')
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
"""
The lines below is a spider contract. For more info see:
http://doc.scrapy.org/en/latest/topics/contracts.html
@url http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/
@scrapes name
"""
sel = Selector(response)
sites = sel.xpath('//ul[@class="directory-url"]/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.xpath('a/text()').extract()
item['link'] = site.xpath('a/@href').extract()
item['desc'] = site.xpath('text()').re('-\s[^\n]*\\r')
items.append(item)
return items
3.5.2 運行并保存為json文件
保存信息的最簡單的方法是通過Feed exports,主要有4種:JSON,JSON lines,CSV,XML。
我們將結果用最經常使用的JSON導出,命令以下:
scrapy crawl dmoz -o items.json -t json
-o 后面是導出文件名,-t 后面是導出類型。
運行結果:
查看items.json文件:
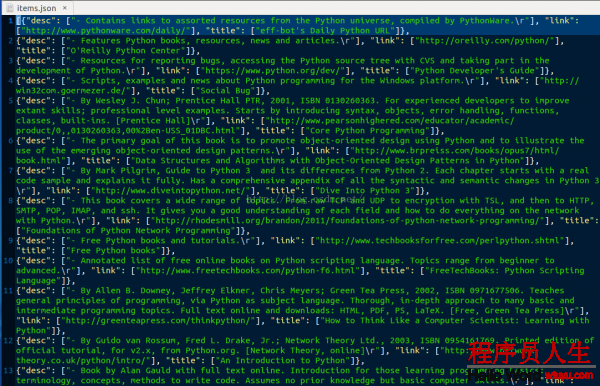
3.6 使用Pipeline輸出結果
打開tutuorial/tutorial/pipelines.py文件,添加自定義JsonWithEncodingTutorialPipeline類代碼:
# -*- coding: utf⑻ -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
from scrapy import signals
import json, codecs
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
class JsonWithEncodingTutorialPipeline(object):
def __init__(self):
self.file = codecs.open('dmoz.json','w',encoding='utf⑻')
def process_item(self,item,spider):
line = json.dumps(dict(item),ensure_ascii=False)+'\n\n'
self.file.write(line)
return item
def spider_closed(self,spider):
self.file.close()
打開tutuorial/tutorial/settings.py文件,在末尾追加部份代碼:
# -*- coding: utf⑻ -*-
# Scrapy settings for tutorial project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
#
BOT_NAME = 'tutorial'
SPIDER_MODULES = ['tutorial.spiders']
NEWSPIDER_MODULE = 'tutorial.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'tutorial (+http://www.yourdomain.com)'
ITEM_PIPELINES = {
'tutorial.pipelines.JsonWithEncodingTutorialPipeline': 300,
}
LOG_LEVEL = 'INFO'
重新運行scrapy crawl dmoz:
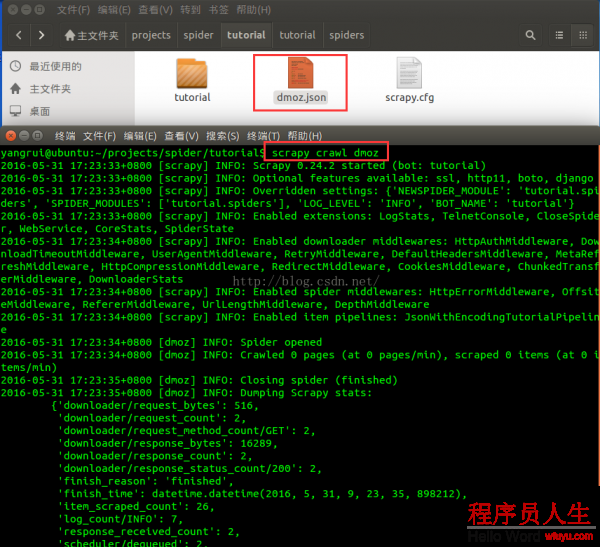
我們可以發現,在根目錄下多了1個dmoz.json文件,這就是我們利用pipeline管道自動生成的結果文件,可以查看其內容與上節的結果完全相同。
完全代碼見:GitHub代碼鏈接(請猛戳~~~)