
看完JavaScript高級程序設計,整理了1下里面的DOM這1塊的知識點,比較多,比較碎!DOM在全部頁面的地位如圖:
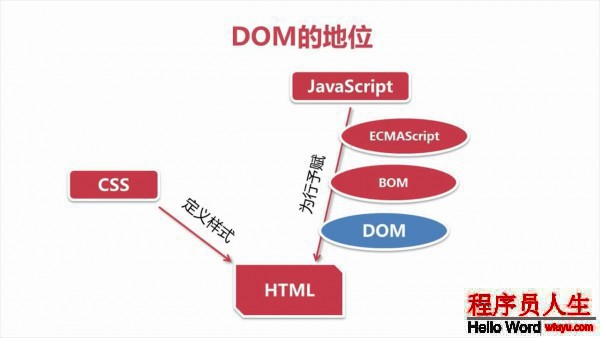
DOM(文檔對象模型)是針對HTML 和XML 文檔的1個API(利用程序編程接口)。DOM描,繪了1個層次化的節點樹,允許開發人員添加、移除和修改頁面的某1部份.
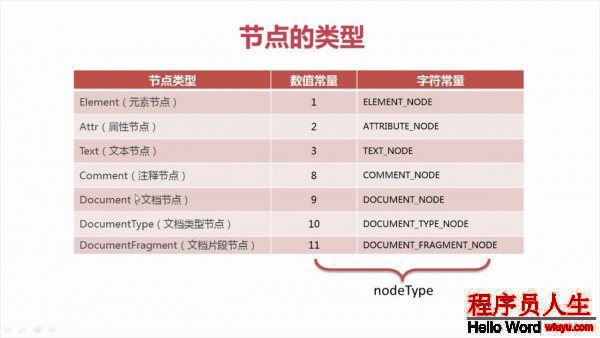
DOM 可以將任何HTML 或XML 文檔描繪成1個由多層節點構成的結構。節點分為幾種不同的類型,每種類型分別表示文檔中不同的信息及(或)標記。每一個節點都具有各自的特點、數據和方法,另外也與其他節點存在某種關系。節點類型如圖:
1、節點的公共屬和方法
nodeType ——節點的類型,9代表Document節點,1代表Element節點,3代表Text節點,8代表Comment節點,11代表DocumentFragment節點
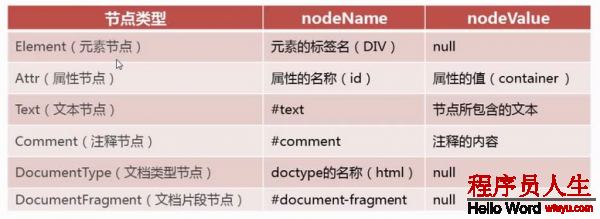
nodeName ——元素的標簽名(如P,SPAN,#text(文本節點),DIV),以大寫情勢表示
nodeVlue ——Text節點或Comment節點的文本內容
childNodes—–獲得子節點
var firstChild = someNode.childNodes[0];
var secondChild = someNode.childNodes.item(1);
var count = someNode.childNodes.length;parentNode——獲得父節點
firstNode——獲得第1個子節點
lastNode——獲得最后1個子節點
nextSibling——獲得下1個兄弟節點
previousSibling——獲得上1個兄弟節點
ownerDocument——獲得文檔節點
hasChildNodes()——判斷是不是有子節點
appendChild()——添加子節點,接收1個參數表示要添加的節點,返回添加的節點.
var returnedNode = someNode.appendChild(newNode);
alert(returnedNode == newNode); //true
alert(someNode.lastChild == newNode); //true//插入后成為第1個子節點
var returnedNode = someNode.insertBefore(newNode, someNode.firstChild);
alert(returnedNode == newNode); //true//替換第1個子節點
var returnedNode = someNode.replaceChild(newNode, someNode.firstChild);//移除第1個子節點
var formerFirstChild = someNode.removeChild(someNode.firstChild);
<ul>
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
</ul>
var deepList = myList.cloneNode(true);
alert(deepList.childNodes.length); //3(IE < 9)或7(其他閱讀器)
var shallowList = myList.cloneNode(false);
alert(shallowList.childNodes.length); //0deepList.childNodes.length 中的差異主要是由于IE8 及更早版本與其他閱讀器處理空白字符的方式不1樣。IE9 之前的版本不會為空白符創建節點。
cloneNode()方法不會復制添加到DOM 節點中的JavaScript 屬性,例如事件處理程序等。這個方法只復制特性、(在明確指定的情況下也復制)子節點,其他1切都不會復制。IE 在此存在1個bug,即它會復制事件處理程序,所以我們建議在復制之前最好先移除事件處理程序。
上述節點的nodeName 和 nodeValue對應下圖:
JavaScript 通過Document 類型表示文檔。在閱讀器中,document 對象是HTMLDocument(繼承自Document 類型)的1個實例,表示全部HTML 頁面。而且,document 對象是window 對象的1個屬性,因此可以將其作為全局對象來訪問
1、document對象的屬性和方法
var html = document.documentElement; //獲得對<html>的援用
alert(html === document.childNodes[0]); //true
alert(html === document.firstChild); //truebody——獲得body節點元素
title——獲得title文字節點元素
//獲得文檔標題
var originalTitle = document.title;
//設置文檔標題
document.title = "New page title";URL——獲得完全的URL
domain——獲得域名
referrer——獲得來源頁面的URL
//獲得完全的URL
var url = document.URL;
//獲得域名
var domain = document.domain;
//獲得來源頁面的URL
var referrer = document.referrer;document.anchors——包括文檔中所有帶name 特性的元素
document.forms——包括文檔中所有的元素,與document.getElementsByTagName(“form”)得到的結果相同
document.images——包括文檔中所有的元素,與document.getElementsByTagName(“img”)得到的結果相同;
document.links——包括文檔中所有帶href 特性的元素。
2、DOM的操作
getElementById()——通過id屬性獲得元素
getElementsByTagName()——通過元素名獲得元素
var div = document.getElementById("myDiv"); //獲得id='myDiv'元素的援用
var images = document.getElementsByTagName("img"); //獲得img元素的援用
var allElements = document.getElementsByTagName("*"); //獲得文檔中所有的元素IE7及較低版本還為此方法添加了1個成心思的“怪癖”:name特性與給定ID匹配的表單元素也會被該方法返回
3、DOM1致性檢測
由于 DOM 分為多個級別,也包括多個部份,因此檢測閱讀器實現了DOM的哪些部份就10分必要了。document.implementation 屬性就是為此提供相應信息和功能的對象,與閱讀器對DOM的實現直接對應。DOM1 級只為document.implementation 規定了1個方法,即hasFeature()。這個方法接受兩個參數:要檢測的DOM功能的名稱及版本號。如果閱讀器支持給定名稱和版本的功能,則該方法返回true。
var hasXmlDom = document.implementation.hasFeature("XML", "1.0");以下為列出了可以檢測的不同的值及版本號
1、HTML元素
所有 HTML 元素都由HTMLElement 類型表示,不是直接通過這個類型,也是通過它的子類型來表示。HTMLElement 類型直接繼承自Element 并添加了1些屬性。添加的這些屬性分別對應于每一個HTML元素中都存在的以下標準特性。
id ——元素在文檔中的唯1標識符。
title ——有關元素的附加說明信息,1般通過工具提示條顯示出來。
lang ——元素內容的語言代碼,很少使用。
dir ——語言的方向,值為”ltr”(left-to-right,從左至右)或”rtl”(right-to-left,從右至左),也很少使用。
className ——與元素的class 特性對應,即為元素指定的CSS類。未將這個屬性命名為class,是由于class 是ECMAScript 的保存字
<div id="myDiv" class="bd" title="Body text" lang="en" dir="ltr"></div>
var div = document.getElementById("myDiv");
alert(div.id); //"myDiv""
alert(div.className); //"bd"
alert(div.title); //"Body text"
alert(div.lang); //"en"
alert(div.dir); //"ltr"
div.id = "someOtherId";
div.className = "ft";
div.title = "Some other text";
div.lang = "fr";
div.dir ="rtl";2、特性操作
有3個方法可以操作元素的特性
getAttribute() setAttribute() removeAttribute()var div = document.getElementById("myDiv");
alert(div.getAttribute("id")); //"myDiv"
alert(div.getAttribute("class")); //"bd"
div.setAttribute("id", "someOtherId");
div.setAttribute("class", "ft");
div.setAttribute("title", "Some other text");
div.removeAttribute("class");有兩類特殊的特性,它們雖然有對應的屬性名,但屬性的值與通過getAttribute()返回的值其實不相同。第1類特性就是style,用于通過CSS 為元素指定樣式。在通過getAttribute()訪問時,返回的style 特性值中包括的是CSS 文本,而通過屬性來訪問它則會返回1個對象。
第2類與眾不同的特性是onclick 這樣的事件處理程序。當在元素上使用時,onclick 特性中包括的是JavaScript 代碼,如果通過getAttribute()訪問,則會返回相應代碼的字符串. IE6 及之前版本不支持removeAttribute()。
3、attributes 屬性
Element類型是使用attributes屬性的唯逐一個DOM節點類型,attributes屬性是NamedNodeMap類型的對象,它有以下幾個方法
var id = element.attributes.getNamedItem("id").nodeValue;
var id = element.attributes["id"].nodeValue;
element.attributes["id"].nodeValue = "someOtherId";由于attributes的方法不夠方便,因此開發人員更多的會使用getAttribute()、removeAttribute()和setAttribute()方法。
4、創建元素
document.createElement() ——方法可以創建新元素。這個方法只接受1個參數,即要創建元素的標簽名。var div = document.createElement('div');
div.id = 'myDiv';
div.className = 'box';在 IE 中可以以另外一種方式使用createElement(),即為這個方法傳入完全的元素標簽,也能夠包括屬性,以下面的例子所示。
var div = document.createElement("<div id=\"myNewDiv\" class=\"box\"></div >");這類方式有助于避開在IE7 及更早版本中動態創建元素的某些問題。
文本節點由 Text 類型表示,包括的是可以照字面解釋的純文本內容。純文本中可以包括轉義后的HTML 字符,但不能包括HTML代碼。
使用以下方法可以操作節點中的文本
appendData(text):將text 添加到節點的末尾。
deleteData(offset, count):從offset 指定的位置開始刪除count 個字符。
insertData(offset, text):在offset 指定的位置插入text。
replaceData(offset, count, text):用text 替換從offset 指定的位置開始到offset+count為止處的文本
splitText(offset):從offset 指定的位置將當前文本節點分成兩個文本節點
substringData(offset, count):提取從offset 指定的位置開始到offset+count 為止處的字符串創建文本節點
createTextNode()——可以創建文本節點.
var textNode = document.createTextNode("<strong>Hello</strong> world!");下面展現如何將1個文本節點添加到文檔中
var element = document.createElement("div");
element.className = "message";
var textNode = document.createTextNode("Hello world!");
element.appendChild(textNode);
document.body.appendChild(element);合并文本節點
1個元素可能會存在多個文本節點,但是文本節點之間也沒有空格,因此沒法辨別哪一個節點對應的是哪一個文本,通過下面的方法可以將element元素的文本節點合并.
var newNode = element.firstChild.splitText(5);從位置5 開始。位置5是"Hello"和"world!"之間的空格
alert(element.firstChild.nodeValue); //"Hello"
alert(newNode.nodeValue); //" world!"
alert(element.childNodes.length); //2注意提示:
1、innerText、textContent innerText與textContent的區分,當文本為空時,innerText是”“,而textContent是undefined
2、innerHTML與innerText的區分,就是對HTML代碼的輸出方式Text不會輸出HTML代碼.
1、選擇符API
Selectors API Level 1 的核心是兩個方法:
- querySelector()
- querySelectorAll()。
在兼容的閱讀器中,可以通過Document 及Element 類型的實例調用它們。目前已完全支持Selectors API Level 1的閱讀器有IE 8+、Firefox 3.5+、Safari 3.1+、Chrome 和Opera 10+。
querySelector()方法
//獲得body 元素
var body = document.querySelector("body");
//獲得ID 為"myDiv"的元素
var myDiv = document.querySelector("#myDiv");
//獲得類為"selected"的第1個元素
var selected = document.querySelector(".selected");
//獲得類為"button"的第1個圖象元素
var img = document.body.querySelector("img.button");querySelectorAll()方法
//獲得某<div>中的所有<em>元素(類似于getElementsByTagName("em"))
var ems = document.getElementById("myDiv").querySelectorAll("em");
//獲得類為"selected"的所有元素
var selecteds = document.querySelectorAll(".selected");
//獲得所有<p>元素中的所有<strong>元素
var strongs = document.querySelectorAll("p strong");2、HTML5與類相干的擴充
//獲得所有類中包括"username"和"current"的元素,類名的前后順序無所謂
var allCurrentUsernames = document.getElementsByClassName("username current");支持 getElementsByClassName()方法的閱讀器有IE 9+、Firefox 3+、Safari 3.1+、Chrome 和
Opera 9.5+。
這個屬性指向的是當前取得焦點的元素,使用focus()可讓元素取得焦點
var button = document.getElementById("myButton");
button.focus();
alert(document.activeElement === button); //true
document.hasFocus()這個方法用于肯定文檔是不是取得了焦點
var button = document.getElementById("myButton");
button.focus();
alert(document.hasFocus()); //true實現了這兩個屬性的閱讀器的包括IE 4+、Firefox 3+、Safari 4+、Chrome 和Opera 8+。
HTMLDocument的變化
document.readyState表示文檔的加載進度,它有兩個值分別為’loading’和’complete’.
if(document.readyState == 'complete'){
//履行操作
}支持 readyState 屬性的閱讀器有IE4+、Firefox 3.6+、Safari、Chrome 和Opera 9+。
document.compatMode屬性告知開發人員閱讀器采取了哪一種渲染模式。在標準模式下,document.compatMode 的值等于”CSS1Compat”,而在混雜模式下document.compatMode 的值等于”BackCompat”。
if (document.compatMode == "CSS1Compat"){
alert("Standards mode");
} else {
alert("Quirks mode");
}兼容性:IE、Firefox、Safari 3.1+、Opera 和Chrome
字符編碼——document.charset
當前文檔的字符編碼
document.defaultCharset——當前文檔的默許字符編碼
3、自定義數據屬性
HTML5 規定可以為元素添加非標準的屬性,但要添加前綴data-,目的是為元素提供與渲染無關的信息,或提供語義信息。
<div id="myDiv" data-appId="12345" data-myname="Nicholas"></div>
var div = document.getElementById("myDiv");
//獲得自定義屬性的值
var appId = div.dataset.appId;
var myName = div.dataset.myname;
//設置值
div.dataset.appId = 23456;
div.dataset.myname = "Michael";
if (div.dataset.myname){
alert("Hello, " + div.dataset.myname);
}支持自定義數據屬性的閱讀器有Firefox 6+和Chrome
插入標記
在讀模式下,innerHTML 屬性返回與調用元素的所有子節點(包括元素、注釋和文本節點)對應
的HTML 標記。在寫模式下,innerHTML 會根據指定的值創建新的DOM樹,然后用這個DOM樹完全
替換調用元素本來的所有子節點
在讀模式下,outerHTML 返回調用它的元素及所有子節點的HTML 標簽。在寫模式下,outerHTML
會根據指定的HTML 字符串創建新的DOM 子樹,然后用這個DOM子樹完全替換調用元素。
4、內存與性能問題
使用本節介紹的方法替換子節點可能會致使閱讀器的內存占用問題,特別是在IE 中,問題更加明顯。在刪除帶有事件處理程序或援用了其他JavaScript 對象子樹時,就有可能致使內存占用問題。假定某個元素有1個事件處理程序(或援用了1個JavaScript 對象作為屬性),在使用前述某個屬性將該元素從文檔樹中刪除后,元素與事件處理程序(或JavaScript 對象)之間的綁定關系在內存中并沒有1并刪除。如果這類情況頻繁出現,頁面占用的內存數量就會明顯增加。因此,在使用innerHTML、outerHTML 屬性方法時,最好先手工刪除要被替換的元素的所有事件處理程序和JavaScript 對象屬性
//讓元素可見
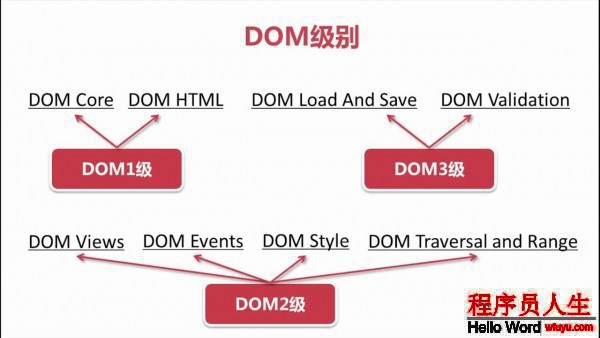
document.forms[0].scrollIntoView();DOM2 和DOM3級分為許多模塊(模塊之間具有某種關聯),分別描寫了DOM 的某個非常具體的子集。這些模塊以下
在 HTML 中定義樣式的方式有3 種:通過<link/>元素包括外部樣式表文件、使用<style/>元素定義嵌入式樣式,和使用style 特性定義針對特定元素的樣式。“DOM2 級樣式”模塊圍繞這3 種利用樣式的機制提供了1套API。要肯定閱讀器是不是支持DOM2 級定義的CSS 能力,可使用以下代碼
var supportsDOM2CSS = document.implementation.hasFeature("CSS", "2.0");
var supportsDOM2CSS2 = document.implementation.hasFeature("CSS2", "2.0");1、訪問元素的樣式
任何支持 style 特性的HTML 元素在JavaScript 中都有1個對應的style 屬性。訪問和設置元素的css屬性可以這樣操作:
var div = document.getElementById('myDiv');
console.log(div.style.color); //獲得color值
div.style.color = 'red'; //設置color值
div.style.fontSize = '20px';//設置font-size的值(這里會將有短橫線的值轉化為駝峰命名來獲得或設置) 注:IE6+,chrome,firfox支持這類獲得或設置css的方式.這里有1個特例,由于float是保存關鍵字,所以通過cssFloat來訪問和設置,而IE中則通過styleFloat來設置或訪問.
元素的style對象除有css的樣式屬性外,也包括了自己的1些屬性,具體以下:
//設置style對象的cssText屬性
myDiv.style.cssText = "width: 25px; height: 100px; background-color: green";
alert(myDiv.style.cssText);2、操作樣式表
CSSStyleSheet 類型表示的是樣式表,包括通過<link>元素包括的樣式表和在<style>元素中定義的樣式表,使用下面的代碼可以肯定閱讀器是不是支持DOM2 級樣式表:
var supportsDOM2StyleSheets =document.implementation.hasFeature("StyleSheets", "2.0");CSSStyleSheet 繼承自StyleSheet,后者可以作為1個基礎接口來定義非CSS 樣式表。從StyleSheet 接口繼承而來的屬性以下:
<link>包括的,則是樣式表的URL;否則,是null。media:當前樣式表支持的所有媒體類型的集合。與所有DOM 集合1樣,這個集合也有1個length 屬性和1個item()方法。也能夠使用方括號語法獲得集合中特定的項。如果集合是空列表,表示樣式表適用于所有媒體。在IE 中,media 是1個反應<link>和<style>元素media特性值的字符串。
ownerNode:指向具有當前樣式表的節點的指針,樣式表多是在HTML 中通過<link>或<style/>引入的(在XML 中多是通過處理指令引入的)。如果當前樣式表是其他樣式表通過@import 導入的,則這個屬性值為null。IE 不支持這個屬性。
parentStyleSheet:在當前樣式表是通過@import 導入的情況下,這個屬性是1個指向導入它的樣式表的指針。
除 disabled 屬性以外,其他屬性都是只讀的。在支持以上所有這些屬性的基礎上,CSSStyleSheet 類型還支持以下屬性和方法:
利用于文檔的所有樣式表是通過 document.styleSheets 集合來表示的。也能夠直接通過<link>或<style>元素獲得CSSStyleSheet 對象。DOM 規定了1個包括CSSStyleSheet 對象的屬性,名叫sheet;除IE,其他閱讀器都支持這個屬性。IE 支持的是styleSheet屬性
3、元素大小
客戶區大小
有關客戶區大小的屬性有兩個:clientWidth 和clientHeight。其中,clientWidth 屬性是元素內容區寬度加上左右內邊距寬度;clientHeight 屬性是元素內容區高度加上上下內邊距高度
轉動大小
IE、Firefox 3+、Safari 4+、Opera 9.5 及Chrome 為每一個元素都提供了1個getBoundingClientRect()方法。這個方法返回會1個矩形對象,包括4 個屬性:left、top、right 和bottom。這些屬性給出了元素在頁面中相對視口的位置。但是,閱讀器的實現稍有不同。IE8 及更早版本認為文檔的左上角坐標是(2, 2),而其他閱讀器包括IE9 則將傳統的(0,0)作為出發點坐標。因此,就需要在1開始檢查1下位于(0,0)處的元素的位置,在IE8 及更早版本中,會返回(2,2),而在其他閱讀器中會返回(0,0).
遍歷
DOM2 級遍歷和范圍”模塊定義了兩個用于輔助完成順序遍歷DOM 結構的類型:NodeIterator和TreeWalker。這兩個類型能夠基于給定的出發點對DOM 結構履行深度優先(depth-first)的遍歷操作。
在與DOM 兼容的閱讀器中(Firefox 1 及更高版本、Safari 1.3 及更高版本、Opera 7.6 及更高版本、Chrome0.2 及更高版本),都可以訪問到這些類型的對象。IE 不支持DOM 遍歷。使用以下代碼可以檢測閱讀器
對DOM2 級遍歷能力的支持情況。
var supportsTraversals = document.implementation.hasFeature("Traversal", "2.0");
var supportsNodeIterator = (typeof document.createNodeIterator == "function");
var supportsTreeWalker = (typeof document.createTreeWalker == "function");范圍
為了讓開發人員更方便地控制頁面,“DOM2 級遍歷和范圍”模塊定義了“范圍”(range)接口。通過范圍可以選擇文檔中的1個區域,而沒必要斟酌節點的界限(選擇在后臺完成,對用戶是不可見的)。在常規的DOM 操作不能更有效地修改文檔時,使用范圍常常可以到達目的。Firefox、Opera、Safari 和Chrome 都支持DOM 范圍。IE 以專有方式實現了自己的范圍特性。
參考:
- JavaScript高級程序設計
- javascript之DOM操作

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


