
例如:
SQL履行的順利的標(biāo)識,SQL從大到小的履行.
例如:
mysql> explain select * from (select * from ( select * from t3 where id=3952602) a) b;
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | <derived3> | system | NULL | NULL | NULL | NULL | 1 | |
| 3 | DERIVED | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | | 1 | |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
很明顯這條SQL是從里向外的履行,就是從id=3 向上履行.
就是select類型,可以有以下幾種
SIMPLE
簡單SELECT(不使用UNION或子查詢等) 例如:
mysql> explain select * from t3 where id=3952602;
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | const | 1 | |
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
PRIMARY
我的理解是最外層的select.例如:
mysql> explain select * from (select * from t3 where id=3952602) a ;
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | | 1 | |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
UNION
UNION中的第2個或后面的SELECT語句.例如
mysql> explain select * from t3 where id=3952602 union all select * from t3 ;
+----+--------------+------------+-------+-------------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+------------+-------+-------------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | const | 1 | |
| 2 | UNION | t3 | ALL | NULL | NULL | NULL | NULL | 1000 | |
|NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | |
+----+--------------+------------+-------+-------------------+---------+---------+-------+------+-------+
DEPENDENT UNION
UNION中的第2個或后面的SELECT語句,取決于外面的查詢
mysql> explain select * from t3 where id in (select id from t3 where id=3952602 union all select id from t3) ;
+----+--------------------+------------+--------+-------------------+---------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+------------+--------+-------------------+---------+---------+-------+------+--------------------------+
| 1 | PRIMARY | t3 | ALL | NULL | NULL | NULL | NULL | 1000 | Using where |
| 2 | DEPENDENT SUBQUERY | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | const | 1 | Using index |
| 3 | DEPENDENT UNION | t3 | eq_ref | PRIMARY,idx_t3_id | PRIMARY | 4 | func | 1 | Using where; Using index |
|NULL | UNION RESULT | <union2,3> | ALL | NULL | NULL | NULL | NULL | NULL | |
+----+--------------------+------------+--------+-------------------+---------+---------+-------+------+--------------------------+
UNION RESULT
UNION的結(jié)果。
mysql> explain select * from t3 where id=3952602 union all select * from t3 ;
+----+--------------+------------+-------+-------------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+------------+-------+-------------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | const | 1 | |
| 2 | UNION | t3 | ALL | NULL | NULL | NULL | NULL | 1000 | |
|NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | |
+----+--------------+------------+-------+-------------------+---------+---------+-------+------+-------+
SUBQUERY
子查詢中的第1個SELECT.
mysql> explain select * from t3 where id = (select id from t3 where id=3952602 ) ;
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------------+
| 1 | PRIMARY | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | const | 1 | |
| 2 | SUBQUERY | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | | 1 | Using index |
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------------+
DEPENDENT SUBQUERY
子查詢中的第1個SELECT,取決于外面的查詢
mysql> explain select id from t3 where id in (select id from t3 where id=3952602 ) ;
+----+--------------------+-------+-------+-------------------+---------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+-------+-------+-------------------+---------+---------+-------+------+--------------------------+
| 1 | PRIMARY | t3 | index | NULL | PRIMARY | 4 | NULL | 1000 | Using where; Using index |
| 2 | DEPENDENT SUBQUERY | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | const | 1 | Using index |
+----+--------------------+-------+-------+-------------------+---------+---------+-------+------+--------------------------+
DERIVED
派生表的SELECT(FROM子句的子查詢)
mysql> explain select * from (select * from t3 where id=3952602) a ;
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | | 1 | |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
顯示這1行的數(shù)據(jù)是關(guān)于哪張表的.
有時不是真實的表名字,看到的是derivedx(x是個數(shù)字,我的理解是第幾步履行的結(jié)果)
mysql> explain select * from (select * from ( select * from t3 where id=3952602) a) b;
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | <derived3> | system | NULL | NULL | NULL | NULL | 1 | |
| 3 | DERIVED | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | | 1 | |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
這列很重要,顯示了連接使用了哪一種種別,有沒有使用索引.
從最好到最差的連接類型為const、eq_reg、ref、range、indexhe和ALL
system
這是const聯(lián)接類型的1個特例。表唯一1行滿足條件.以下(t3表上的id是primary key)
mysql> explain select * from (select * from t3 where id=3952602) a ;
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | | 1 | |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
const
表最多有1個匹配行,它將在查詢開始時被讀取。由于唯一1行,在這行的列值可被優(yōu)化器剩余部份認(rèn)為是常數(shù)。const表很快,由于它們只讀取1次!
const用于用常數(shù)值比較PRIMARY KEY或UNIQUE索引的所有部份時。在下面的查詢中,tbl_name可以用于const表:
SELECT * from tbl_name WHERE primary_key=1;
SELECT * from tbl_name WHERE primary_key_part1=1和primary_key_part2=2;
例如:
mysql> explain select * from t3 where id=3952602;
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | t3 | const | PRIMARY,idx_t3_id | PRIMARY | 4 | const | 1 | |
+----+-------------+-------+-------+-------------------+---------+---------+-------+------+-------+
eq_ref
對每一個來自于前面的表的行組合,從該表中讀取1行。這多是最好的聯(lián)接類型,除const類型。它用在1個索引的所有部份被聯(lián)接使用并且索引是UNIQUE或PRIMARY KEY。
eq_ref可以用于使用= 操作符比較的帶索引的列。比較值可以為常量或1個使用在該表前面所讀取的表的列的表達(dá)式。
在下面的例子中,MySQL可使用eq_ref聯(lián)接來處理ref_tables:
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
例如
mysql> create unique index idx_t3_id on t3(id) ;
Query OK, 1000 rows affected (0.03 sec)
Records: 1000 Duplicates: 0 Warnings: 0
mysql> explain select * from t3,t4 where t3.id=t4.accountid;
+----+-------------+-------+--------+-------------------+-----------+---------+----------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+-------------------+-----------+---------+----------------------+------+-------+
| 1 | SIMPLE | t4 | ALL | NULL | NULL | NULL | NULL | 1000 | |
| 1 | SIMPLE | t3 | eq_ref | PRIMARY,idx_t3_id | idx_t3_id | 4 | dbatest.t4.accountid | 1 | |
+----+-------------+-------+--------+-------------------+-----------+---------+----------------------+------+-------+
ref
對每一個來自于前面的表的行組合,所有有匹配索引值的即將從這張表中讀取。如果聯(lián)接只使用鍵的最左側(cè)的前綴,或如果鍵不是UNIQUE或PRIMARY KEY(換句話說,如果聯(lián)接不能基于關(guān)鍵字選擇單個行的話),則使用ref。如果使用的鍵僅僅匹配少許行,該聯(lián)接類型是不錯的。
ref可以用于使用=或<=>操作符的帶索引的列。
在下面的例子中,MySQL可使用ref聯(lián)接來處理ref_tables:
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
例如:
mysql> drop index idx_t3_id on t3;
Query OK, 1000 rows affected (0.03 sec)
Records: 1000 Duplicates: 0 Warnings: 0
mysql> create index idx_t3_id on t3(id) ;
Query OK, 1000 rows affected (0.04 sec)
Records: 1000 Duplicates: 0 Warnings: 0
mysql> explain select * from t3,t4 where t3.id=t4.accountid;
+----+-------------+-------+------+-------------------+-----------+---------+----------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-------------------+-----------+---------+----------------------+------+-------+
| 1 | SIMPLE | t4 | ALL | NULL | NULL | NULL | NULL | 1000 | |
| 1 | SIMPLE | t3 | ref | PRIMARY,idx_t3_id | idx_t3_id | 4 | dbatest.t4.accountid | 1 | |
+----+-------------+-------+------+-------------------+-----------+---------+----------------------+------+-------+
2 rows in set (0.00 sec)
ref_or_null
該聯(lián)接類型猶如ref,但是添加了MySQL可以專門搜索包括NULL值的行。在解決子查詢中常常使用該聯(lián)接類型的優(yōu)化。
在下面的例子中,MySQL可使用ref_or_null聯(lián)接來處理ref_tables:
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
index_merge
該聯(lián)接類型表示使用了索引合并優(yōu)化方法。在這類情況下,key列包括了使用的索引的清單,key_len包括了使用的索引的最長的關(guān)鍵元素。
例如:
mysql> explain select * from t4 where id=3952602 or accountid=31754306 ;
+----+-------------+-------+-------------+----------------------------+----------------------------+---------+------+------+------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------------+----------------------------+----------------------------+---------+------+------+------------------------------------------------------+
| 1 | SIMPLE | t4 | index_merge | idx_t4_id,idx_t4_accountid | idx_t4_id,idx_t4_accountid | 4,4 | NULL | 2 | Using union(idx_t4_id,idx_t4_accountid); Using where |
+----+-------------+-------+-------------+----------------------------+----------------------------+---------+------+------+------------------------------------------------------+
1 row in set (0.00 sec)
unique_subquery
該類型替換了下面情勢的IN子查詢的ref:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
unique_subquery是1個索引查找函數(shù),可以完全替換子查詢,效力更高。
index_subquery
該聯(lián)接類型類似于unique_subquery。可以替換IN子查詢,但只合適以下情勢的子查詢中的非唯1索引:
value IN (SELECT key_column FROM single_table WHERE some_expr)
range
只檢索給定范圍的行,使用1個索引來選擇行。key列顯示使用了哪一個索引。key_len包括所使用索引的最長關(guān)鍵元素。在該類型中ref列為NULL。
當(dāng)使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或IN操作符,用常量比較關(guān)鍵字列時,可使用range
mysql> explain select * from t3 where id=3952602 or id=3952603 ;
+----+-------------+-------+-------+-------------------+-----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+-------------------+-----------+---------+------+------+-------------+
| 1 | SIMPLE | t3 | range | PRIMARY,idx_t3_id | idx_t3_id | 4 | NULL | 2 | Using where |
+----+-------------+-------+-------+-------------------+-----------+---------+------+------+-------------+
1 row in set (0.02 sec)
index
該聯(lián)接類型與ALL相同,除只有索引樹被掃描。這通常比ALL快,由于索引文件通常比數(shù)據(jù)文件小。
當(dāng)查詢只使用作為單索引1部份的列時,MySQL可使用該聯(lián)接類型。
ALL
對每一個來自于先前的表的行組合,進(jìn)行完全的表掃描。如果表是第1個沒標(biāo)記const的表,這通常不好,并且通常在它情況下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常數(shù)值或列值被檢索出。
possible_keys列指出MySQL能使用哪一個索引在該表中找到行。注意,該列完全獨立于EXPLAIN輸出所示的表的次序。這意味著在possible_keys中的某些鍵實際上不能按生成的表次序使用。
如果該列是NULL,則沒有相干的索引。在這類情況下,可以通過檢查WHERE子句看是不是它援用某些列或合適索引的列來提高你的查詢性能。如果是這樣,創(chuàng)造1個適當(dāng)?shù)乃饕⑶以俅斡肊XPLAIN檢查查詢。
key列顯示MySQL實際決定使用的鍵(索引)。如果沒有選擇索引,鍵是NULL。要想強(qiáng)迫MySQL使用或忽視possible_keys列中的索引,在查詢中使用FORCE INDEX、USE INDEX或IGNORE INDEX。
key_len列顯示MySQL決定使用的鍵長度。如果鍵是NULL,則長度為NULL。
使用的索引的長度。在不損失精確性的情況下,長度越短越好
ref列顯示使用哪一個列或常數(shù)與key1起從表當(dāng)選擇行。
rows列顯示MySQL認(rèn)為它履行查詢時必須檢查的行數(shù)。
該列包括MySQL解決查詢的詳細(xì)信息,下面詳細(xì).
Distinct
1旦MYSQL找到了與行相聯(lián)合匹配的行,就不再搜索了
Not exists
MYSQL優(yōu)化了LEFT JOIN,1旦它找到了匹配LEFT JOIN標(biāo)準(zhǔn)的行,
就不再搜索了
Range checked for each
Using filesort
看到這個的時候,查詢就需要優(yōu)化了。MYSQL需要進(jìn)行額外的步驟來發(fā)現(xiàn)如何對返回的行排序。它根據(jù)連接類型和存儲排序鍵值和匹配條件的全部行的行指針來排序全部行
Using index
列數(shù)據(jù)是從僅僅使用了索引中的信息而沒有讀取實際的行動的表返回的,這產(chǎn)生在對表的全部的要求列都是同1個索引的部份的時候
Using temporary
看到這個的時候,查詢需要優(yōu)化了。這里,MYSQL需要創(chuàng)建1個臨時表來存儲結(jié)果,這通常產(chǎn)生在對不同的列集進(jìn)行ORDER BY上,而不是GROUP BY上
Using where
使用了WHERE從句來限制哪些即將與下1張表匹配或是返回給用戶。如果不想返回表中的全部行,并且連接類型ALL或index,這就會產(chǎn)生,或是查詢有問題
大型網(wǎng)站為了減緩大量的并發(fā)訪問,除在網(wǎng)站實現(xiàn)散布式負(fù)載均衡,遠(yuǎn)遠(yuǎn)不夠。到了數(shù)據(jù)業(yè)務(wù)層、數(shù)據(jù)訪問層,如果還是傳統(tǒng)的數(shù)據(jù)結(jié)構(gòu),或只是單單靠1臺服務(wù)器扛,如此多的數(shù)據(jù)庫連接操作,數(shù)據(jù)庫必定會崩潰,數(shù)據(jù)丟失的話,后果更是 不堪假想。這時候候,我們會斟酌如何減少數(shù)據(jù)庫的聯(lián)接,1方面采取優(yōu)秀的代碼框架,進(jìn)行代碼的優(yōu)化,采取優(yōu)秀的數(shù)據(jù)緩存技術(shù)如:memcached,如果資金豐富的話,必定會想到架設(shè)服務(wù)器群,來分擔(dān)主數(shù)據(jù)庫的壓力。利用MySQL主從配置,實現(xiàn)讀寫分離,減輕數(shù)據(jù)庫壓力。這類方式,在如今很多網(wǎng)站里都有使用,也不是甚么新鮮事情,在這邊總結(jié)1下也方便大家學(xué)習(xí)參考1下。
搭設(shè)1臺Master服務(wù)器(centos6.6系統(tǒng),ip:192.168.0.101),搭設(shè)兩臺Slave服務(wù)器(虛擬機(jī)centos 6.6系統(tǒng) ip:192.168.0.102, ip:192.168.0.103)
原理:主服務(wù)器(Master)負(fù)責(zé)網(wǎng)站NonQuery操作,從服務(wù)器負(fù)責(zé)Query操作,用戶可以根據(jù)網(wǎng)站功能模特性塊固定訪問Slave服務(wù)器,或自己寫個池或隊列,自由為要求分配從服務(wù)器連接。主從服務(wù)器利用MySQL的2進(jìn)制日志文件,實現(xiàn)數(shù)據(jù)同步。2進(jìn)制日志由主服務(wù)器產(chǎn)生,從服務(wù)器響應(yīng)獲得同步數(shù)據(jù)庫。
在Master MySQL上創(chuàng)建1個用戶‘repl’,并允許其他Slave服務(wù)器可以通過遠(yuǎn)程訪問Master,通過該用戶讀取2進(jìn)制日志,實現(xiàn)數(shù)據(jù)同步。
找到mySQL安裝文件夾修改my.Ini文件。mySQL中有好幾種日志方式,這不是今天的重點。我們只要啟動2進(jìn)制日志log-bin就ok。
在[mysqld]下面增加下面幾行代碼
mysql> SHOW MASTER STATUS;
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000001 | 1285 | | |
+-------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
修改my.cnf文件
關(guān)鍵在于下面幾行
登錄myaster mysql
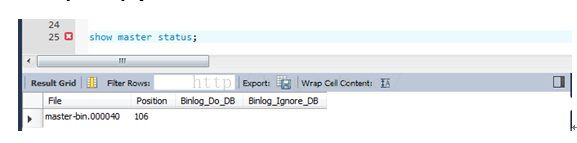
記下這兩個值
先暫停slave的mySQL Service,使用命令:
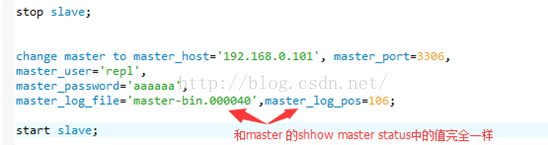
以上這步 log_file和 master_log_pos必須和當(dāng)前master上的show master status命令所顯示的值完全1模1樣,比如説我們現(xiàn)在加了1個slave,再加1個slave,再加第2個slave。都是如此操作。
啟動 slave的mySQL Service使用
在master上查看,有1張表叫user_info。然后在slave上查看,也有1張一樣的表
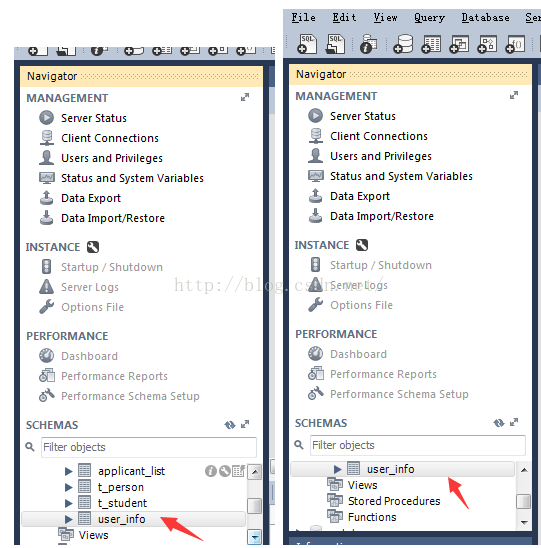
刪除master上的user_info表,視察slave上,該表也自動被刪除。
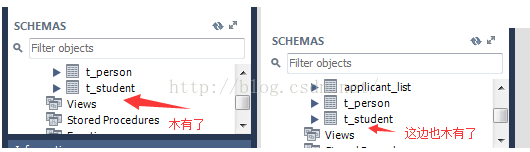
因此,你在master上做的任何操作,都會被自動同步至slave上。
1、從slave(slave1)大眾當(dāng)選定1個slave,準(zhǔn)備錢換成master;
2、檢查slave1的復(fù)制狀態(tài):
mysql> SHOW PROCESSLIST ;
+—-+————-+———–+——+———+————+———————————————————————–+——————+
| Id | User | Host | db | Command | Time | State | Info |
+—-+————-+———–+——+———+————+———————————————————————–+——————+
| 1 | system user | | NULL | Connect | 54733 | Waiting for master to send event | NULL |
| 2 | system user | | NULL | Connect | 4294965772 |Has read all relay log; waiting for the slave I/O thread to update it | NULL |
| 8 | root | localhost | NULL | Query | 0 | NULL | SHOW PROCESSLIST |
+—-+————-+———–+——+———+————+———————————————————————–+——————+
注:
這里主要是檢測Slave1是不是已利用完從Master讀取過來的在relay log中的操作,如果未利用完不能stop slave,否則數(shù)據(jù)肯定會有丟失。
3、停止slave1的slave進(jìn)程,并reset稱master:
mysql> STOP SLAVE ;
Query OK, 0 rows affected (0.00 sec)
mysql> RESET MASTER;
Query OK, 0 rows affected, 8 warnings (0.02 sec)
4、將slave 群中的其他slave(slave2)的Master切換成新的master(由原slave1 reset成的):
1) 停slave進(jìn)程:
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec)
2) 更換master:
mysql> CHANGE MASTER TO
MASTER_HOST=’10.0.65.106′,
MASTER_USER=’repl’,
MASTER_PASSWORD=’slavepass’
;
Query OK, 0 rows affected (0.00 sec)
3) 開啟slave:
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
5、檢查slave的狀態(tài):
mysql> show slave status;
1、必須使要被降級的master變成只讀狀態(tài)。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


