
(1)MySQL可以將數據以不同的技術存儲在文件(內存)中,這類技術就成為存儲引擎。
每種存數引擎使用不同的存儲機制、索引技能、鎖定水平,終究提供廣泛且不同的功能。
(2)使用不同的存儲引擎也能夠說不同類型的表
(3)MySQL支持的存儲引擎
查看數據表的創建語句:
SHOW CREATE TABLE 表名相干概念:
(1).并發控制:1個人讀數據,另外1個人在刪除這個數據。
當多個連接對記錄進行修改時保證數據的1致性和完全性。系統使用鎖系統來解決這個并發控制,這類鎖分為:
1).同享鎖(讀鎖)—在同1時間內,多個用戶可以讀取同1個資源,讀取進程中數據不會產生任何變化。
2).排他鎖(寫鎖)—在任什么時候候只能有1個用戶寫入資源,當進行寫鎖時會阻塞其他的讀鎖或寫鎖操作。
3.鎖的力度(也叫鎖的顆粒)
鎖顆粒(鎖定時的單位)
—表鎖,是1種開消最小的鎖策略。得到數據表的寫鎖
—行鎖,是1種開消最大的鎖策略。并行性最大
表鎖的開消最小,由于使用鎖的個數最小,行鎖的開消最大,由于可能使用鎖的個數比較多。
并發性
就是多個鏈接對同1份數據進行操作時,要保證數據的完全性和1致性。
事務的特性 —–》轉賬業務:從1個人減去 100,另外1個人加上100。
事務(包括1連串的操作,事務(Transaction)是1個對數據庫履行工作單元)是為了保護數據的完全性。幾個進程作為整體即事務 每一個進程出現毛病都恢復到原來的數據
1.原子性(Atomicity):確保工作單位內的所有操作都成功完成,否則,事務會在出現故障時終止,之前的操作也會回滾到之前的狀態。
2.1致性(Consistency):確保數據庫在成功提交的事務上正確地改變狀態。
3.隔離性(Isolation):使事務操作相互獨立和透明。
4.持久性(Durability):確保已提交事務的結果或效果在系統產生故障的情況下依然存在。
ACID;
外鍵和索引
1、外鍵:保證數據1致性的策略
2、索引:類似目錄,是對數據表中1列或多列的值進行排序的1種結構,方便快速查找到數據
索引:普通索引、唯1索引、全文索引、Btree索引、hash索引……
各種存儲引擎的特點
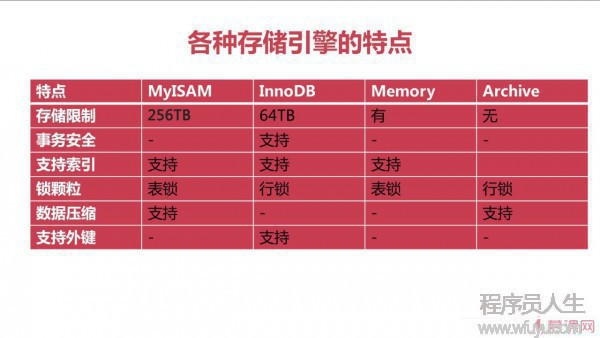
使用最多的:MyISAM,InnoDB。
MyISAM:適用于事務的處理不多的情況,支持數據緊縮,容量大;
InnoDB:適用于事務處理比較多,需要有外鍵支持的情況。
CSV存儲引擎:以逗號為分隔符,不支持索引;
BlackHole:黑洞引擎,寫入的數據都會消失,1般用于做數據復制的中繼;
存儲引擎:
MyISAM: 存儲限制可達256TB,支持索引,表級鎖定,數據緊縮
InnoDB: 存儲限制為64TB,支持事務和索引,鎖顆粒為行鎖。
設置存儲引擎
(1)通過修改MySQL配置文件實現
default-storage-engine = engine(2)通過創建數據表命令實現
CREATE TABLE table_name(\
...
) ENGINE = engine;例如:
CREATE TABLE tp1(
s1 VARCHAR(10)
) ENGINE = MyISAM;
SHOW CREATE TABLE tp1; // 查看數據表的結構(3)通過修改數據表命令實現
ALTER TABLE table_name ENGINE [=] engine_name; 例如:
ALTER TABLE tp1 ENGINE = InnoDB;1、數據字典的保護
保護數據字典:
1.第3方工具:針對不同的DBMS
2.利用數據庫本身的備注字段:對表和列增加備注字段,舉例如圖

3.導出數據字典(很通用)但是注意:更改表備注時,只需要更改表備注,其
他的1些列的屬性(列的長度、寬度、是不是非空)必須保持原樣
2、保護索引
建立索引的列:
2、定期保護索引碎片
3、(MySQL)SQL中不要使用強迫索引關鍵字
3、保護(修改)表結構
注意事項
1、MySQL5.5之前會鎖表,可以使用第3方工具;5.6以后本身支持在線表結構變更
2、同時保護數據字典
3、控制表的寬度和大小
合適的操作
1、批量操作(數據庫中)逐條操作(利用程序中)
2、盡可能少用”select * “查詢
3、控制使用用戶自定義函數(使用函數,索引不起作用)
4、不要使用全文索引(中文支持不好,需要另建索引文件)
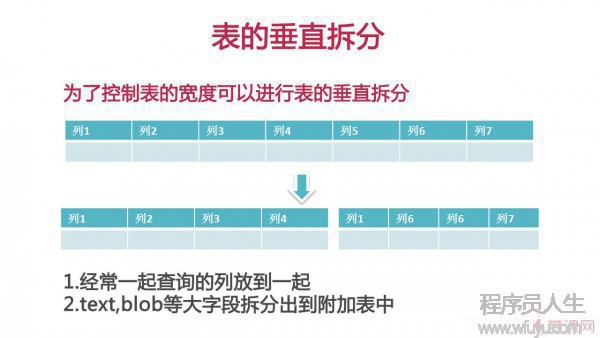
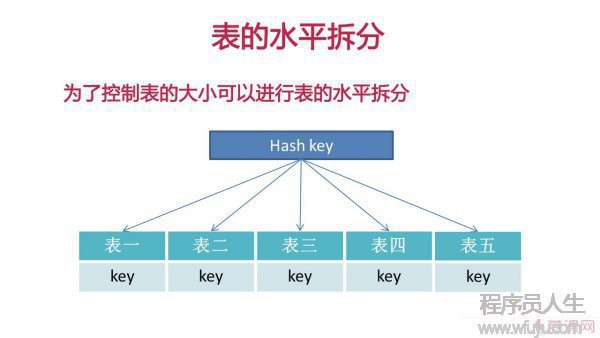
4、數據表的水平拆分和垂直拆分
垂直拆分:為了控制表的寬度
水平拆分:為了控制表的數據量
表示2維的是個平面,上面的情況是非常容易想一想的,問題的關鍵是要依托1定原則了!
目標是不變的:為了效力、為了可保護性、為了更快更省事!
explain分析sql的履行計劃,并找出sql需要優化的地方
explain select customer_id,first_name,last_name from customer;
+—-+————-+———-+——+—————+——+———+——+——+——-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+———-+——+—————+——+———+——+——+——-+
| 1 | SIMPLE | customer | ALL | NULL | NULL | NULL | NULL | 599 | NULL |
+—-+————-+———-+——+—————+——+———+——+——+——-+
Max()和Count()的優化
1.對max()查詢,可以為表創建索引,create index index_name on table_name(column_name 規定需要索引的列),這里就是以付款的日期為索引;,然后在進行查詢。
如果沒有索引,查詢的可能1直到最后1行。

2.count()對多個關鍵字進行查詢,比如在1條SQL中同時查出2006年和2007年電影的數量,語句:

select count(release_year='2006' or null) as '2006年電影數量',
count(release_year='2007' or null) as '2007年電影數量'
from film;count(*)時會包括null空這1列,而count(id)這類寫法將不包括null這1列.
3.子查詢的優化
把子查詢改成左連接查詢,但是如果兩張表里存在1對多的情況,左連接查詢結果會出現,所以要使用distinct去掉重復記錄
select * from table1 where table1.column1 in (select table2.column2 from table2);
select distinct table1.column1 from table1 join table2 on table1.column1=table2.column2;4.order by語句優化
group by可能會出現臨時表(Using temporary),文件排序(Using filesort)等,影響效力。
可以通過關聯的子查詢,來避免產生臨時表和文件排序,可以節省io
改寫前
select actor.first_name,actor.last_name,count(*)
from sakila.film_actor
inner join sakila.actor using(actor_id)
group by film_actor.actor_id;改寫后
select actor.first_name,actor.last_name,c.cnt
from sakila.actor inner join(
select actor_id,count(*) as cnt from sakila.film_actor group by
actor_id
)as c using(actor_id);5.limit 語句優化
limit經常使用于分頁處理,經常會伴隨order by從句使用,因此大多時候會使用Filesorts這樣會造成大量的io問題
1.使用有索引的列或主鍵進行order by操作
2.記錄上次返回的主鍵,在下次查詢時使用主鍵過濾
使用這類方式有1個限制,就是主鍵1定要順序排序和連續的,如果主鍵出現空缺可能會致使終究頁面上顯示的列表不足5條,解決辦法是附加1列,保證這1列是自增的并增加索引就能夠了
6.選擇適合的索引列
1.在where,group by,order by,on從句中出現的列
2.索引字段越小越好(由于數據庫的存儲單位是頁,1頁中能存下的數據越多越好 )
3.離散度大得列放在聯合索引前面
select count(distinct customer_id), count(distinct staff_id) from payment;查看離散度 通過統計不同的列值來實現 count越大 離散程度越高
過量的索引不但影響寫入,而且影響查詢,索引越多,分析越慢
如何找到重復和過剩的索引,主鍵已是索引了,所以primay key 的主鍵不用再設置unique唯1索引了
冗余索引,是指多個索引的前綴列相同,innodb會在每一個索引后面自動加上主鍵信息


冗余索引查詢工具
pt-duplicate-key-checker
由于業務變更有些原來使用的索引現在不使用了也是需要清除的,這也是索引優化的1個方面了!有些索引的使用的頻率很低,乃至沒用過。
注意:作者再次的強調SQL和索引的優化對數據庫的優化是相當重要的,這1層的優化如果做好了,其他的優化也能起到1些作用否則其他的優化所能起到的作用是微不足道的,這1層的優化也是本錢最低效果最好的1層了,所以對數據庫的優化最好重點放在這1層。
#重要,緩沖池的大小 推薦總內存量的75%,越大越好。
innodb_buffer_pool_size
#默許只有1個緩沖池,如果1個緩沖池中并發量過大,容易阻塞,此時可以分為多個緩沖池;
innodb_buffer_pool_instances
#log緩沖的大小,1般最常1s就會刷新1次,故不用太大;
innodb_log_buffer_size
#重要,對io效力影響較大。0:1s刷新1次到磁盤;1:每次提交都會刷新到磁盤;2:每次提交刷新到緩沖區,1s刷新到磁盤;默許為1。
innodb_flush_log_at_trx_commit
#讀寫的io進程數量,默許為4
innodb_read_io_threads
innodb_write_io_threads
#重要,控制每一個表使用獨立的表空間,默許為OFF,即所有表建立在1個同享的表空間中。
innodb_file_per_table
#mysql在甚么情況下會刷新表的統計信息,1般為OFF。
innodb_stats_on_metadata

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


