基于Hadoop生態(tài)圈的數(shù)據(jù)倉(cāng)庫(kù)實(shí)踐 —— 環(huán)境搭建(三)
來源:程序員人生 發(fā)布時(shí)間:2016-07-01 13:30:49 閱讀次數(shù):4896次
3、建立數(shù)據(jù)倉(cāng)庫(kù)示例模型
Hadoop及其相干服務(wù)安裝配置好后,下面用1個(gè)小而完全的示例說明多維模型及其相干ETL技術(shù)在Hadoop上的具體實(shí)現(xiàn)。
1. 設(shè)計(jì)ERD
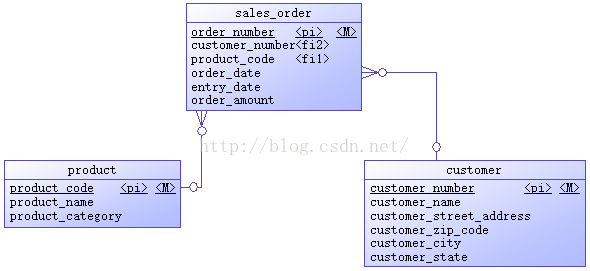
操作型系統(tǒng)是1個(gè)銷售定單系統(tǒng),初始時(shí)只有產(chǎn)品、客戶、定單3個(gè)表,ERD以下圖所示。
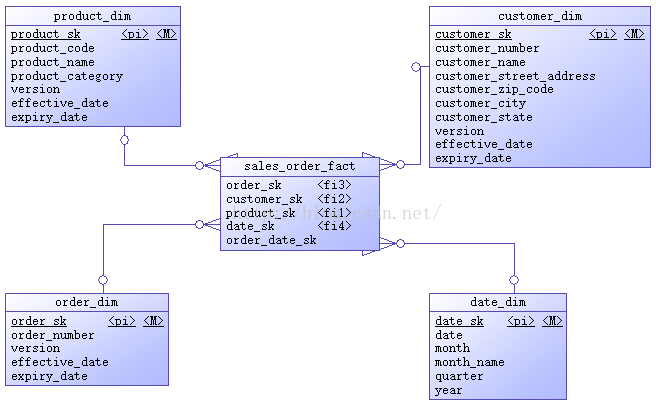
多維數(shù)據(jù)倉(cāng)庫(kù)包括有1個(gè)銷售定單事實(shí)表,產(chǎn)品、客戶、定單、日期4個(gè)維度表,ERD以下圖所示。
作為示例,上面這些ERD里的屬性都很簡(jiǎn)單,看屬性名字便知其含義。維度表除日期維度外,其它3個(gè)表都在源表的基礎(chǔ)上增加了代理鍵、版本號(hào)、生效日期、過期日期4個(gè)屬性,用來處理漸變維(SCD)。日期維度有其特殊性,該維度數(shù)據(jù)1旦生成績(jī)不會(huì)改變,所以不需要版本號(hào)、生效日期、過期日期。代理鍵是維度表的主鍵。事實(shí)表援用維度表的代理鍵作為自己的外鍵,銷售金額是當(dāng)前事實(shí)表中的唯1度量。
2. Hive相干配置
使用Hive作為多維數(shù)據(jù)倉(cāng)庫(kù)的主要挑戰(zhàn)是處理漸變維(SCD)和生成代理鍵。處理漸變維需要配置Hive支持行級(jí)更新,并在建表時(shí)選擇適當(dāng)?shù)奈募?#26684;式。生成代理鍵在關(guān)系
數(shù)據(jù)庫(kù)中1般都是用自增列或序列對(duì)象,但Hive中沒有這樣的機(jī)制,得用其它辦法實(shí)現(xiàn),在后面ETL部份再詳細(xì)討論。
(1)選擇文件格式
(本段摘譯自https://acadgild.com/blog/file-formats-in-apache-hive/)
Hive是Hadoop上的數(shù)據(jù)倉(cāng)庫(kù)組件,它便于查詢和管理散布式存儲(chǔ)上的大數(shù)據(jù)集。Hive提供了1種稱為HiveQL的語言,允許用戶進(jìn)行類似于SQL的查詢。和SQL1樣,HiveQL只處理結(jié)構(gòu)化數(shù)據(jù)。缺省時(shí)Hive使用內(nèi)建的derby
數(shù)據(jù)庫(kù)存儲(chǔ)元數(shù)據(jù),也能夠配置Hive使用MySQL
數(shù)據(jù)庫(kù)存儲(chǔ)元數(shù)據(jù)。Hive里的數(shù)據(jù)終究存儲(chǔ)在HDFS的文件中,它可以處理以下4種文件格式:
- TEXTFILE
- SEQUENCEFILE
- RCFILE
- ORCFILE
在深入各種類型的文件格式前,先看1下甚么是文件格式。
文件格式
所謂文件格式是1種信息被存儲(chǔ)或編碼成計(jì)算機(jī)文件的方式。在Hive中文件格式指的是記錄怎樣被存儲(chǔ)到文件中。當(dāng)我們處理結(jié)構(gòu)化數(shù)據(jù)時(shí),每條記錄都有自己的結(jié)構(gòu)。記錄在文件中是如何編碼的即定義了文件格式。
不同文件格式的主要區(qū)分在于它們的數(shù)據(jù)編碼、緊縮率、使用的空間和磁盤I/O。
Hive在導(dǎo)入數(shù)據(jù)時(shí)其實(shí)不驗(yàn)證數(shù)據(jù)與表模式是不是匹配,但是它會(huì)驗(yàn)證文件格式是不是和表定義的相匹配。
TEXTFILE
TEXTFILE是Hadoop里最經(jīng)常使用的輸入輸出格式,也是Hive的缺省文件格式。如果表定義為TEXTFILE,則可以向該表中導(dǎo)入以逗號(hào)、Tab或空格作為分隔符的數(shù)據(jù),也能夠?qū)隞SON數(shù)據(jù)。TEXTFILE格式缺省每行被認(rèn)為是1條記錄。
TEXTFILE格式的輸入輸出包是:
org.apache.hadoop.mapred.TextInputFormat
org.apache.hadoop.mapred.TextOutputFormat
示例:
-- 建立TEXTFILE格式的表
create table olympic(athelete STRING,age INT,country STRING,year STRING,closing STRING,sport STRING,gold INT,silver INT,bronze INT,total INT) row format delimited fields terminated by '\t' stored as textfile;
-- 向表中導(dǎo)入數(shù)據(jù)
load data local inpath '/home/kiran/Downloads/olympic_data.csv' into table olympic;
-- 查詢表
select athelete from olympic;
SEQUENCEFILE
我們知道Hadoop處理少許大文件比大量小文件的性能要好。如果文件小于Hadoop里定義的塊尺寸,可以認(rèn)為是小文件。如果有大量小文件,那末元數(shù)據(jù)的增長(zhǎng)將轉(zhuǎn)化為NameNode的開消。為了解決這個(gè)問題,Hadoop引入了sequence文件,將sequence作為存儲(chǔ)小文件的容器。
Sequence文件是由2進(jìn)制鍵值對(duì)組成的平面文件。Hive將查詢轉(zhuǎn)換成MapReduce作業(yè)時(shí),決定1個(gè)給定記錄的哪些鍵值對(duì)被使用。Sequence文件是可分割的2進(jìn)制格式,主要的用處是聯(lián)合兩個(gè)或多個(gè)小文件組成1個(gè)sequence文件。
SEQUENCEFILE格式的輸入輸出包是:
org.apache.hadoop.mapred.SequenceFileInputFormat
org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
示例:
-- 建立SEQUENCEFILE格式的表
create table olympic_sequencefile(athelete STRING,age INT,country STRING,year STRING,closing STRING,sport STRING,gold INT,silver INT,bronze INT,total INT) row format delimited fields terminated by '\t' stored as sequencefile;
-- 向表中導(dǎo)入數(shù)據(jù)
-- 與TEXTFILE有些不同,由于SEQUENCEFILE是2進(jìn)制格式,所以需要從其它表向SEQUENCEFILE表插入數(shù)據(jù)。
INSERT OVERWRITE TABLE olympic_sequencefile SELECT * FROM olympic;
-- 查詢表
select athelete from olympic_sequencefile;
RCFILE
RCFILE指的是Record Columnar File,1種高緊縮率的2進(jìn)制文件格式,被用于在1個(gè)時(shí)間點(diǎn)操作多行的場(chǎng)景。RCFILEs是由2進(jìn)制鍵值對(duì)組成的平面文件,這點(diǎn)與SEQUENCEFILE非常相似。RCFILE以記錄的情勢(shì)存儲(chǔ)表中的列,即列存儲(chǔ)方式。它先分割行做水平分區(qū),然后分割列做垂直分區(qū)。RCFILE把1行的元數(shù)據(jù)作為鍵,把行數(shù)據(jù)作為值。這類面向列的存儲(chǔ)在履行數(shù)據(jù)分析時(shí)更高效。
RCFILE格式的輸入輸出包是:
org.apache.hadoop.hive.ql.io.RCFileInputFormat
org.apache.hadoop.hive.ql.io.RCFileOutputFormat
示例:
-- 建立RCFILE格式的表
create table olympic_rcfile(athelete STRING,age INT,country STRING,year STRING,closing STRING,sport STRING,gold INT,silver INT,bronze INT,total INT) row format delimited fields terminated by '\t' stored as rcfile
-- 向表中導(dǎo)入數(shù)據(jù)
-- 不能直接向RCFILE表中導(dǎo)入數(shù)據(jù),需要從其它表向RCFILE表插入數(shù)據(jù)。
INSERT OVERWRITE TABLE olympic_rcfile SELECT * FROM olympic;
-- 查詢表
select athelete from olympic_rcfile;
ORCFILE
ORC指的是Optimized Row Columnar,就是說相對(duì)其它文件格式,它以更優(yōu)化的方式存儲(chǔ)數(shù)據(jù)。ORC能將原始數(shù)據(jù)的大小縮減75%,從而提升了數(shù)據(jù)處理的速度。OCR比Text、Sequence和RC文件格式有更好的性能。而且ORC是目前Hive中唯1支持事務(wù)的文件格式。
ORCFILE格式的輸入輸出包是:
org.apache.hadoop.hive.ql.io.orc
示例:
-- 建立ORCFILE格式的表
create table olympic_orcfile(athelete STRING,age INT,country STRING,year STRING,closing STRING,sport STRING,gold INT,silver INT,bronze INT,total INT) row format delimited fields terminated by '\t' stored as orcfile;
-- 向表中導(dǎo)入數(shù)據(jù)
-- 不能直接向ORCFILE表中導(dǎo)入數(shù)據(jù),需要從其它表向ORCFILE表插入數(shù)據(jù)。
INSERT OVERWRITE TABLE olympic_orcfile SELECT * FROM olympic;
-- 查詢表
select athelete from olympic_orcfile;
應(yīng)當(dāng)根據(jù)數(shù)據(jù)需求選擇適當(dāng)?shù)奈募?#26684;式,例如,
a)如果數(shù)據(jù)有參數(shù)化的分隔符,那末可以選擇TEXTFILE格式。
b)如果數(shù)據(jù)所在文件比塊尺寸小,可以選擇SEQUENCEFILE格式。
c)如果想履行數(shù)據(jù)分析,并高效地存儲(chǔ)數(shù)據(jù),可以選擇RCFILE格式。
d)如果希望減小數(shù)據(jù)所需的存儲(chǔ)空間并提升性能,可以選額ORCFILE格式。
對(duì)多維數(shù)據(jù)倉(cāng)庫(kù)來講,需要處理SCD,必定要用到行級(jí)更新,所以所有TDS(轉(zhuǎn)換后的數(shù)據(jù)存儲(chǔ))里的表,除日期維度表外,其它表都是用ORCFILE格式。日期維度表數(shù)據(jù)1旦生成績(jī)不會(huì)修改,所以使用TEXTFILE格式。RDS(原始數(shù)據(jù)存儲(chǔ))里的表使用缺省的TEXTFILE格式。
(2)支持行級(jí)更新
在1個(gè)典型的星型模式數(shù)據(jù)倉(cāng)庫(kù)中,維度表隨時(shí)間的變化很緩慢。例如,1個(gè)零售商開了1家新商店,需要將新店數(shù)據(jù)加到商店表,或1個(gè)已有商店的營(yíng)業(yè)面積或其它需要跟蹤的特性改變了。這些改變會(huì)致使插入或修改個(gè)別記錄。Hive從0.14版本開始支持事務(wù)和行級(jí)更新,但缺省是不支持的,需要1些附加的配置。
a)配置Hive支持事務(wù)
CDH 5.7.0包括的Hive版本是1.1.0,可以支持事務(wù)及行級(jí)更新,但此版本的中文支持問題較多。編輯hive-site.xml配置文件,添加支持事務(wù)的屬性。
vi /etc/hive/conf.cloudera.hive/hive-site.xml
<!-- 添加以下配置項(xiàng)以支持事務(wù) -->
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
b)添加Hive元數(shù)據(jù)
[root@cdh2~]#mysql -u root -p hive
INSERT INTO NEXT_LOCK_ID VALUES(1);
INSERT INTO NEXT_COMPACTION_QUEUE_ID VALUES(1);
INSERT INTO NEXT_TXN_ID VALUES(1);
COMMIT;
說明:如果這3個(gè)表沒有數(shù)據(jù),履行行級(jí)更新時(shí)會(huì)報(bào)以下毛病:org.apache.hadoop.hive.ql.lockmgr.DbTxnManager FAILED: Error in acquiring locks: Error communicating with the metastore
c)測(cè)試
重啟Hive,然后履行下面的HiveQL語句
[root@cdh2~]#beeline -u jdbc:hive2://
use test;
-- 建立測(cè)試表
create table t1(id int, name string)
clustered by (id) into 8 buckets
stored as orc TBLPROPERTIES ('transactional'='true');
說明:
- 必須存儲(chǔ)為ORC格式
- 建表語句必須帶有into buckets子句和stored as orc TBLPROPERTIES ('transactional'='true')子句,并且不能帶有sorted by子句。
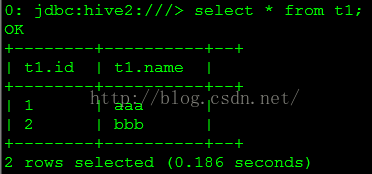
-- 測(cè)試insert
insert into t1 values (1,'aaa');
insert into t1 values (2,'bbb');
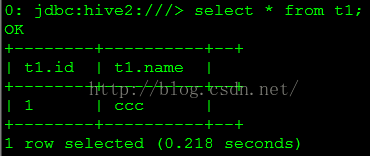
select* from t1;
查詢結(jié)果以下圖所示。
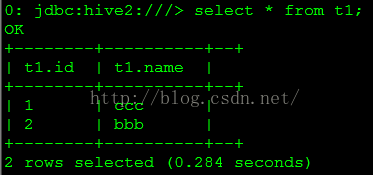
-- 測(cè)試update
update t1 set name='ccc' where id=1;
select* from t1;
查詢結(jié)果以下圖所示。
-- 測(cè)試delete
delete from t1 where id=2;
select* from t1;
查詢結(jié)果以下圖所示。
-- 對(duì)已有非ORC表的轉(zhuǎn)換
-- 在本地文件/root/a.txt中寫入以下4行數(shù)據(jù)
1,a,US,CA
2,b,US,CB
3,c,CA,BB
4,d,CA,BC
-- 建立非分區(qū)表并加載數(shù)據(jù)
use test;
CREATE TABLE t1 (id INT, name STRING, cty STRING, st STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
LOAD DATA LOCAL INPATH '/root/a.txt' INTO TABLE t1;
SELECT * FROM t1;
-- 建立外部份區(qū)事務(wù)表并加載數(shù)據(jù)
CREATE EXTERNAL TABLE t2 (id INT, name STRING) PARTITIONED BY (country STRING, state STRING)
CLUSTERED BY (id) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
INSERT INTO T2 PARTITION (country, state) SELECT * FROM T1;
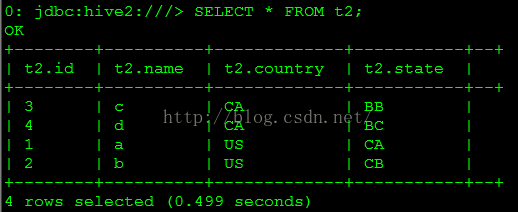
SELECT * FROM t2;
查詢結(jié)果以下圖所示。
-- 修改數(shù)據(jù)
INSERT INTO TABLE t2 PARTITION (country, state) VALUES (5,'e','DD','DD');
UPDATE t2 SET name='f' WHERE id=1;
DELETE FROM t2 WHERE name='b';
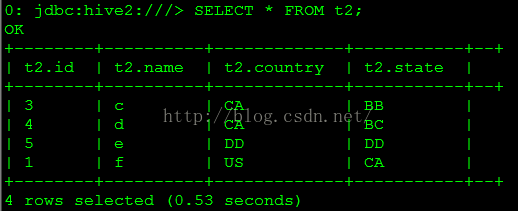
SELECT * FROM t2;
查詢結(jié)果以下圖所示。
說明:
- 不能修改bucket列的值,否則會(huì)報(bào)以下毛病:FAILED: SemanticException [Error 10302]: Updating values of bucketing columns is not supported. Column id.
- 對(duì)已有非ORC表的轉(zhuǎn)換,只能通過新建ORC表再向新表遷移數(shù)據(jù)的方式,直接修改原表的文件格式屬性是不行的(有興趣的可以試試,我是踩到過坑了)。
3. 建立數(shù)據(jù)庫(kù)表
在本示例中,源
數(shù)據(jù)庫(kù)表就是前面提到的操作型系統(tǒng)的摹擬。在CDH1上的MySQL中建立源
數(shù)據(jù)庫(kù)表。RDS存儲(chǔ)原始數(shù)據(jù),作為源數(shù)據(jù)到數(shù)據(jù)倉(cāng)庫(kù)的過渡,在CDH2上的Hive中建RDS庫(kù)表。TDS即為轉(zhuǎn)化后的多維數(shù)據(jù)倉(cāng)庫(kù),在CDH2上的Hive中建TDS庫(kù)表。
(1)建立源數(shù)據(jù)
數(shù)據(jù)庫(kù)表
建立源數(shù)據(jù)
數(shù)據(jù)庫(kù)表的SQL腳本以下:
-- 建立源
數(shù)據(jù)庫(kù)
DROP DATABASE IF EXISTS source;
CREATE DATABASE source;
-- 建立源庫(kù)表
USE source;
-- 建立客戶表
CREATE TABLE customer (
customer_number INT NOT NULL AUTO_INCREMENT PRIMARY KEY comment '客戶編號(hào),主鍵',
customer_name VARCHAR(50) comment '客戶名稱',
customer_street_address VARCHAR(50) comment '客戶住址',
customer_zip_code INT comment '郵編',
customer_city VARCHAR(30) comment '所在城市',
customer_state VARCHAR(2) comment '所在省分'
);
-- 建立產(chǎn)品表
CREATE TABLE product (
product_code INT NOT NULL AUTO_INCREMENT PRIMARY KEY comment '產(chǎn)品編碼,主鍵',
product_name VARCHAR(30) comment '產(chǎn)品名稱',
product_category VARCHAR(30) comment '產(chǎn)品類型'
);
-- 建立銷售定單表
CREATE TABLE sales_order (
order_number INT NOT NULL AUTO_INCREMENT PRIMARY KEY comment '定單號(hào),主鍵',
customer_number INT comment '客戶編號(hào)',
product_code INT comment '產(chǎn)品編碼',
order_date DATE comment '定單日期',
entry_date DATE comment '登記日期',
order_amount DECIMAL(10 , 2 ) comment '銷售金額',
foreign key (customer_number)
references customer (customer_number)
on delete cascade on update cascade,
foreign key (product_code)
references product (product_code)
on delete cascade on update cascade
);
(2)生成源庫(kù)測(cè)試數(shù)據(jù)
生成源庫(kù)測(cè)試數(shù)據(jù)的SQL腳本以下:
USE source;
-- 生成客戶表測(cè)試數(shù)據(jù)
INSERT INTO customer
(customer_name,
customer_street_address,
customer_zip_code,
customer_city,
customer_state)
VALUES
('Really Large Customers', '7500 Louise Dr.',17050, 'Mechanicsburg','PA'),
('Small Stores', '2500 Woodland St.',17055, 'Pittsburgh','PA'),
('Medium Retailers','1111 Ritter Rd.',17055,'Pittsburgh','PA'),
('Good Companies','9500 Scott St.',17050,'Mechanicsburg','PA'),
('Wonderful Shops','3333 Rossmoyne Rd.',17050,'Mechanicsburg','PA'),
('Loyal Clients','7070 Ritter Rd.',17055,'Pittsburgh','PA'),
('Distinguished Partners','9999 Scott St.',17050,'Mechanicsburg','PA');
-- 生成產(chǎn)品表測(cè)試數(shù)據(jù)
INSERT INTO product
(product_name,
product_category )
VALUES
('Hard Disk Drive', 'Storage'),
('Floppy Drive', 'Storage'),
('LCD Panel', 'Monitor');
-- 生成銷售定單表測(cè)試數(shù)據(jù)
INSERT INTO sales_order VALUES
(1, 1, 1, '2013-02-01', '2013-02-01', 1000)
, (2, 2, 2, '2013-02⑴0', '2013-02⑴0', 1000)
, (3, 3, 3, '2013-03-01', '2013-03-01', 4000)
, (4, 4, 1, '2013-04⑴5', '2013-04⑴5', 4000)
, (5, 5, 2, '2013-05⑵0', '2013-05⑵0', 6000)
, (6, 6, 3, '2013-07⑶0', '2013-07⑶0', 6000)
, (7, 7, 1, '2013-09-01', '2013-09-01', 8000)
, (8, 1, 2, '2013⑴1⑴0', '2013⑴1⑴0', 8000)
, (9, 2, 3, '2014-01-05', '2014-01-05', 1000)
, (10, 3, 1, '2014-02⑴0', '2014-02⑴0', 1000)
, (11, 4, 2, '2014-03⑴5', '2014-03⑴5', 2000)
, (12, 5, 3, '2014-04⑵0', '2014-04⑵0', 2500)
, (13, 6, 1, '2014-05⑶0', '2014-05⑶0', 3000)
, (14, 7, 2, '2014-06-01', '2014-06-01', 3500)
, (15, 1, 3, '2014-07⑴5', '2014-07⑴5', 4000)
, (16, 2, 1, '2014-08⑶0', '2014-08⑶0', 4500)
, (17, 3, 2, '2014-09-05', '2014-09-05', 1000)
, (18, 4, 3, '2014⑴0-05', '2014⑴0-05', 1000)
, (19, 5, 1, '2015-01⑴0', '2015-01⑴0', 4000)
, (20, 6, 2, '2015-02⑵0', '2015-02⑵0', 4000)
, (21, 7, 3, '2015-02⑵8', '2015-02⑵8', 4000);
COMMIT;
(3)建立RDS庫(kù)表
建立RDS庫(kù)表的HiveQL腳本以下:
-- 建立RDS
數(shù)據(jù)庫(kù)
DROP DATABASE IF EXISTS rds CASCADE;
CREATE DATABASE rds;
-- 建立RDS庫(kù)表
USE rds;
-- 建立客戶過渡表
CREATE TABLE customer (
customer_number INT comment 'number',
customer_name VARCHAR(30) comment 'name',
customer_street_address VARCHAR(30) comment 'address',
customer_zip_code INT comment 'zipcode',
customer_city VARCHAR(30) comment 'city',
customer_state VARCHAR(2) comment 'state'
);
-- 建立產(chǎn)品過渡表
CREATE TABLE product (
product_code INT comment 'code',
product_name VARCHAR(30) comment 'name',
product_category VARCHAR(30) comment 'category'
);
-- 建立銷售定單過渡表
CREATE TABLE sales_order (
order_number INT comment 'order number',
customer_number INT comment 'customer number',
product_code INT comment 'product code',
order_date DATE comment 'order date',
entry_date DATE comment 'entry date',
order_amount DECIMAL(10 , 2 ) comment 'order amount'
);
(4)建立TDS庫(kù)表
建立TDS庫(kù)表的HiveQL腳本以下:
-- 建立數(shù)據(jù)倉(cāng)庫(kù)
數(shù)據(jù)庫(kù)
DROP DATABASE IF EXISTS dw CASCADE;
CREATE DATABASE dw;
-- 建立數(shù)據(jù)倉(cāng)庫(kù)表
USE dw;
-- 建立客戶維度表
CREATE TABLE customer_dim (
customer_sk INT comment 'surrogate key',
customer_number INT comment 'number',
customer_name VARCHAR(50) comment 'name',
customer_street_address VARCHAR(50) comment 'address',
customer_zip_code INT comment 'zipcode',
customer_city VARCHAR(30) comment 'city',
customer_state VARCHAR(2) comment 'state',
version INT comment 'version',
effective_date DATE comment 'effective date',
expiry_date DATE comment 'expiry date'
)
CLUSTERED BY (customer_sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
-- 建立產(chǎn)品維度表
CREATE TABLE product_dim (
product_sk INT comment 'surrogate key',
product_code INT comment 'code',
product_name VARCHAR(30) comment 'name',
product_category VARCHAR(30) comment 'category',
version INT comment 'version',
effective_date DATE comment 'effective date',
expiry_date DATE comment 'expiry date'
)
CLUSTERED BY (product_sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
-- 建立定單維度表
CREATE TABLE order_dim (
order_sk INT comment 'surrogate key',
order_number INT comment 'number',
version INT comment 'version',
effective_date DATE comment 'effective date',
expiry_date DATE comment 'expiry date'
)
CLUSTERED BY (order_sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
-- 建立銷售定單事實(shí)表
CREATE TABLE sales_order_fact (
order_sk INT comment 'order surrogate key',
customer_sk INT comment 'customer surrogate key',
product_sk INT comment 'product surrogate key',
order_date_sk INT comment 'date surrogate key',
order_amount DECIMAL(10 , 2 ) comment 'order amount'
)
CLUSTERED BY (order_sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
(5)建立日期維度表并生成數(shù)據(jù)
使用下面的shell命令建立日期維度表并生成數(shù)據(jù):
./date_dim_generate.sh 2000-01-01 2020⑴2⑶1
date_dim_generate.sh shell腳本文件內(nèi)容以下:
#!/bin/bash
date1="$1"
date2="$2"
tempdate=`date -d "$date1" +%F`
tempdateSec=`date -d "$date1" +%s`
enddateSec=`date -d "$date2" +%s`
min=1
max=`expr \( $enddateSec - $tempdateSec \) / \( 24 \* 60 \* 60 \) + 1`
cat /dev/null > ./date_dim.csv
while [ $min -le $max ]
do
month=`date -d "$tempdate" +%m`
month_name=`date -d "$tempdate" +%B`
quarter=`echo $month | awk '{print int(($0⑴)/3)+1}'`
year=`date -d "$tempdate" +%Y`
echo ${min}","${tempdate}","${month}","${month_name}","${quarter}","${year} >> ./date_dim.csv
tempdate=`date -d "+$min day $date1" +%F`
tempdateSec=`date -d "+$min day $date1" +%s`
min=`expr $min + 1`
done
beeline -u jdbc:hive2://cdh2:10000/dw -f create_table_date_dim.sql --silent
hdfs dfs -put -f date_dim.csv /user/hive/warehouse/dw.db/date_dim/
create_table_date_dim.sql SQL腳本內(nèi)容以下:
drop table if exists date_dim;
create table date_dim (
date_sk int comment 'surrogate key',
date date comment 'date,yyyy-mm-dd',
month tinyint comment 'month',
month_name varchar(9) comment 'month name',
quarter tinyint comment 'quarter',
year smallint comment 'year'
)
comment 'date dimension table'
row format delimited fields terminated by ','
stored as textfile;
說明:
a)HiveQL腳本中的列注釋沒有使用中文,這是由于Hive 1.1.0中,中文注釋會(huì)在show create table命令中顯示亂碼,要解決這個(gè)問題需要重新編譯Hive的源碼,簡(jiǎn)單起見,這里都是用了英文列注釋。關(guān)于1.1.0中的這個(gè)bug,可參考https://issues.apache.org/jira/browse/HIVE⑴1837。示例數(shù)據(jù)中沒有中文,也是出于類似的緣由。
b)維度表雖然使用了代理鍵,但不能將它設(shè)置為主鍵,在數(shù)據(jù)庫(kù)級(jí)也不能確保其唯1性。Hive中并沒有主外鍵、唯1非空束縛這些關(guān)系數(shù)據(jù)庫(kù)的概念。
c)sales_order.entry_date表示定單登記的日期,1般情況下應(yīng)當(dāng)同等于定單日期(sales_order.order_date),但有時(shí)二者是不同的,等實(shí)驗(yàn)進(jìn)行到“遲到的事實(shí)”時(shí)會(huì)詳細(xì)說明。
d)關(guān)于日期維度數(shù)據(jù)裝載
日期維度在數(shù)據(jù)倉(cāng)庫(kù)中是1個(gè)特殊角色。日期維度包括時(shí)間概念,而時(shí)間是最重要的,由于數(shù)據(jù)倉(cāng)庫(kù)的主要功能之1就是存儲(chǔ)歷史數(shù)據(jù),所以每一個(gè)數(shù)據(jù)倉(cāng)庫(kù)里的數(shù)據(jù)都有1個(gè)時(shí)間特點(diǎn)。裝載日期數(shù)據(jù)有3個(gè)經(jīng)常使用方法:
- 預(yù)裝載
- 逐日裝載1天
- 從源數(shù)據(jù)裝載日期
在3種方法中,預(yù)裝載最容易,也是本實(shí)驗(yàn)所采取的方法。使用預(yù)裝載插入1個(gè)時(shí)間段里的所有日期。比如,本示例預(yù)裝載21年的日期維度數(shù)據(jù),從2000年1月1日到2020年12月31日。使用這個(gè)方法,在數(shù)據(jù)倉(cāng)庫(kù)生命周期中,只需要預(yù)裝載日期維度1次。預(yù)裝載的缺點(diǎn)是:
生活不易,碼農(nóng)辛苦
如果您覺得本網(wǎng)站對(duì)您的學(xué)習(xí)有所幫助,可以手機(jī)掃描二維碼進(jìn)行捐贈(zèng)