1 數據庫索引(順序、B-+、散列)
MySQL官方對索引的定義為:索引(Index)是幫助MySQL高效獲得數據的數據結構。在數據以外,數據庫系統還保護著滿足特定查找算法的數據結構,這些數據結構以某種方式援用(指向)數據,這樣就能夠在這些數據結構上實現高級查找算法。這類數據結構,就是索引。
索引分為聚簇索引和非聚簇索引兩種,還有覆蓋索引,聚簇索引 是依照數據寄存的物理位置為順序的,而非聚簇索引就不1樣了;聚簇索引能提高多行檢索的速度,而非聚簇索引對單行的檢索很快。
為表設置索引要付出代價的:1是增加了數據庫的存儲空間,2是在插入和修改數據時要花費較多的時間(由于索引也要隨之變動)。
為何要創建索引
創建索引可以大大提高系統的性能。
第1,通過創建唯1性索引,可以保證數據庫表中每行數據的唯1性。
第2,可以大大加快數據的檢索速度,這也是創建索引的最主要的緣由。
第3,可以加速表和表之間的連接,特別是在實現數據的參考完全性方面特別成心義。
第4,在使用分組和排序子句進行數據檢索時,一樣可以顯著減少查詢中分組和排序的時間。
第5,通過使用索引,可以在查詢的進程中,使用優化隱藏器,提高系統的性能。
或許會有人要問:增加索引有如此多的優點,為何不對表中的每個列創建1個索引呢?由于,增加索引也有許多不利的方面。
第1,創建索引和保護索引要耗費時間,這類時間隨著數據量的增加而增加。
第2,索引需要占物理空間,除數據表占數據空間以外,每個索引還要占1定的物理空間,如果要建立聚簇索引,那末需要的空間就會更大。
第3,當對表中的數據進行增加、刪除和修改的時候,索引也要動態的保護,這樣就下降了數據的保護速度。
在哪建索引
索引是建立在數據庫表中的某些列的上面。在創建索引的時候,應當斟酌在哪些列上可以創建索引,在哪些列上不能創建索引。1般來講,應當在這些列上創建索引:
在常常需要搜索的列上,可以加快搜索的速度;
在作為主鍵的列上,強迫該列的唯1性和組織表中數據的排列結構;
在常常用在連接的列上,這些列主要是1些外鍵,可以加快連接的速度;在常常需要根據范圍進行搜索的列上創建索引,由于索引已排序,其指定的范圍是連續的;
在常常需要排序的列上創建索引,由于索引已排序,這樣查詢可以利用索引的排序,加快排序查詢時間;
在常常使用在WHERE子句中的列上面創建索引,加快條件的判斷速度。
一樣,對有些列不應當創建索引。1般來講,不應當創建索引的的這些列具有以下特點:
第1,對那些在查詢中很少使用或參考的列不應當創建索引。這是由于,既然這些列很少使用到,因此有索引或無索引,其實不能提高查詢速度。相反,由于增加了索引,反而下降了系統的保護速度和增大了空間需求。
第2,對那些只有很少數據值的列也不應當增加索引。這是由于,由于這些列的取值很少,例如人事表的性別列,在查詢的結果中,結果集的數據行占了表中數據行的很大比例,即需要在表中搜索的數據行的比例很大。增加索引,其實不能明顯加快檢索速度。
第3,對那些定義為text, image和bit數據類型的列不應當增加索引。這是由于,這些列的數據量要末相當大,要末取值很少,不利于使用索引。
第4,當修改性能遠遠大于檢索性能時,不應當創建索引。這是由于,修改性能和檢索性能是相互矛盾的。當增加索引時,會提高檢索性能,但是會下降修改性能。當減少索引時,會提高修改性能,下降檢索性能。因此,當修改操作遠遠多于檢索操作時,不應當創建索引。
2 數據庫事務的特點
數據庫事務是指作為單個邏輯工作單元履行的1系列操作,這些操作要末全做要末全不做,是1個不可分割的工作單位。
數據庫事務的4大特性(簡稱ACID)是:
(1) 原子性(Atomicity)
事務的原子性指的是,事務中包括的程序作為數據庫的邏輯工作單位,它所做的對數據修改操作要末全部履行,要末完全不履行。這類特性稱為原子性。
例如銀行取款事務分為2個步驟(1)存折減款(2)提取現金。不可能存折減款,卻沒有提取現金。2個步驟必須同時完成或都不完成。
(2)1致性(Consistency)
事務的1致性指的是在1個事務履行之前和履行以后數據庫都必須處于1致性狀態。這類特性稱為事務的1致性。假設數據庫的狀態滿足所有的完全性束縛,就說該數據庫是1致的。
例如完全性束縛a+b=10,1個事務改變了a,那末b也應隨之改變。
(3)分離性(亦稱獨立性Isolation)
分離性指并發的事務是相互隔離的。即1個事務內部的操作及正在操作的數據必須封閉起來,不被其它企圖進行修改的事務看到。假設并發交叉履行的事務沒有任何控制,操縱相同的同享對象的多個并發事務的履行可能引發異常情況。
(4)持久性(Durability)
持久性意味著當系統或介質產生故障時,確保已提交事務的更新不能丟失。即1旦1個事務提交,DBMS保證它對數據庫中數據的改變應當是永久性的,即對已提交事務的更新能恢復。持久性通過數據庫備份和恢復來保證。
3 數據庫優化(詳見http://blog.csdn.net/littlehorsebro/article/details/51546846)
單機:
(1)創建索引:在數據庫設計的時候,要能夠充分的利用索引帶來的性能提升?如何建立索引?建立甚么樣的索引?在哪些字段上建立索引?見以上“數據庫索引”
(2)sql語句:設計數據庫的原則就是盡量少的進行數據庫寫操作(插入,更新,刪除等),查詢越簡單越好(單表查詢 > inner join> 其他)。
(3)配置緩存:配置緩存可以有效的下降數據庫查詢讀取次數,從而減緩數據庫服務器壓力,到達優化的目的。可配置的緩存包括索引緩存(key_buffer),排序緩存(sort_buffer),查詢緩存(query_buffer),表描寫符緩存(table_cache),
(4)切表:分表包括兩種方式:橫向分表和縱向分表,其中,橫向分表比較有使意圖義,故名思議,橫向切表就是指把記錄分到不同的表中,而每條記錄仍舊是完全的(縱向切表后每條記錄是不完全的),例如原始表中有100條記錄,我要切成2個表,那末最簡單也是最經常使用的方法就是ID取摸切表法,本例中,就把ID為1,3,5,7。。。的記錄存在1個表中,ID為2,4,6,8,。。。的記錄存在另外一張表中。雖然橫向切表可以減少查詢強度,但是它也破壞了原始表的完全性,如果該表的統計操作比較多,那末就不合適橫向切表。橫向切表有個非常典型的用法,就是用戶數據:每一個用戶的用戶數據1般都比較龐大,但是每一個用戶數據之間的關系不大,因此這里很合適橫向切表。最后,要記住1句話就是:分表會造成查詢的負擔,因此在數據庫設計之初,要想好是不是真的合適切表的優化
(5)日志分析:通過分析日志(查詢吞吐量,數據量監控;慢查詢分析:索引、IO、CPU),可以找到系統性能的瓶頸,從而進1步尋覓優化方案
散布式數據庫集群:這類散布式集群的技術關鍵就是“同步復制”
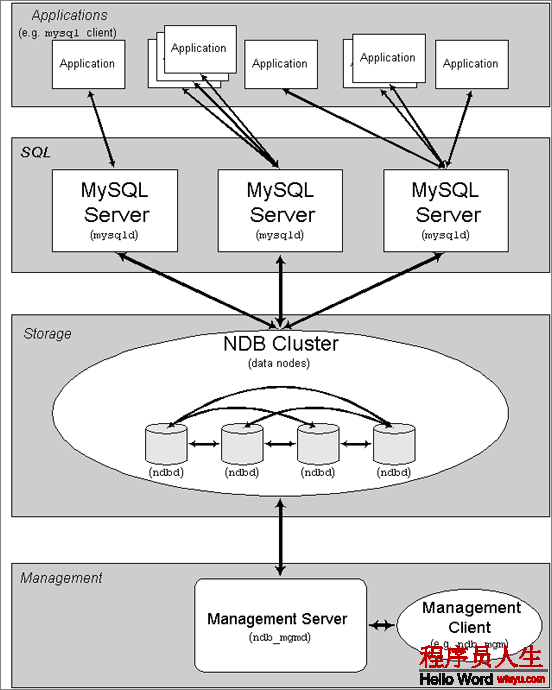
散布式數據庫結構
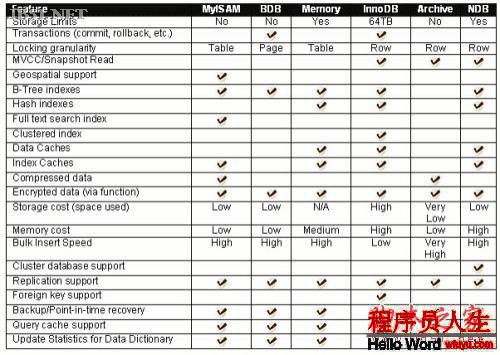
4 數據庫引擎
使用MySQL插件式存儲引擎體系結構,允許數據庫專 業人員為特定的利用需求選擇專門的存儲引擎,完全不需要管理任何特殊的利用編碼要求。采取MySQL服務器體系結構,由于在存儲級別上提供了1致和簡單的 利用模型和API,利用程序編程人員和DBA可不再斟酌所有的底層實行細節。因此,雖然不同的存儲引擎具有不同的能力,利用程序是與之分離的。
MySQL支持數個存儲引擎作為對不同表的類型的處理器。MySQL存儲引擎包括處理事務安全表的引擎和處理非事務安全表的引擎:
上一篇 Struts2入門詳解
下一篇 答大二學生:跟著自己的興趣定方向
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有