
對任何DBMS,索引都是進(jìn)行優(yōu)化的最主要的因素。對少許的數(shù)據(jù),沒有適合的索引影響不是很大,但是,當(dāng)隨著數(shù)據(jù)量的增加,性能會急劇降落。
如果對多列進(jìn)行索引(組合索引),列的順序非常重要,MySQL僅能對索引最左側(cè)的前綴進(jìn)行有效的查找。例如:
假定存在組合索引(c1,c2),查詢語句select * from t1 where c1=1 and c2=2能夠使用該索引。查詢語句select * from t1 where c1=1也能夠使用該索引。但是,查詢語句select * from t1 where c2=2不能夠使用該索引,由于沒有組合索引的引導(dǎo)列,即,要想使用c2列進(jìn)行查找,必須出現(xiàn)c1等于某值。
舉例說明:
創(chuàng)建兩張表book(圖書表)和bookclass(圖書分類表)
select b.ISBN FROM book b where b.CATEGORY_ID = 1;
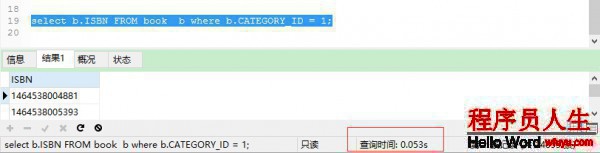
履行時間為:0.053s
使用explain來分析1下該SQL:
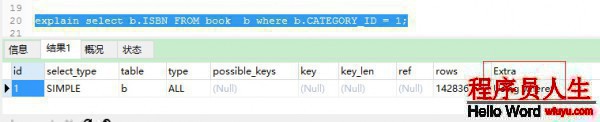
type = ALL Extra=Using where,全表查詢沒有使用索引。
explain顯示了mysql如何使用索引來處理select語句和連接表。可以幫助選擇更好的索引和寫出更優(yōu)化的查詢語句。
ALL 對每一個來自于先前的表的行組合,進(jìn)行完全的表掃描。如果表是第1個沒標(biāo)記const的表,這通常不好,并且通常在它情況下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常數(shù)值或列值被檢索出。
創(chuàng)建組合索引:
create index index_isbn on book (CATEGORY_ID,ISBN) ;
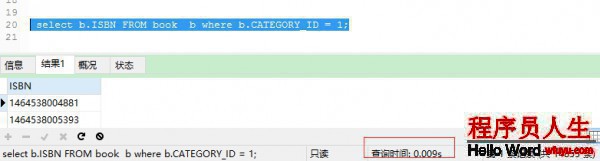
再次履行SQL,發(fā)現(xiàn)時間縮短到0.009s
使用explain來分析1下該SQL:
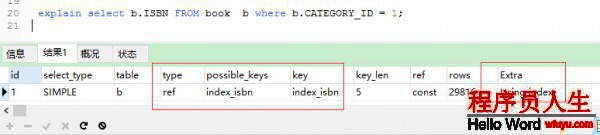
type = ref,Extra = Using index 使用了索引查詢。
ref 對每一個來自于前面的表的行組合,所有有匹配索引值的即將從這張表中讀取。如果聯(lián)接只使用鍵的最左側(cè)的前綴,或如果鍵不是UNIQUE或PRIMARY KEY(換句話說,如果聯(lián)接不能基于關(guān)鍵字選擇單個行的話),則使用ref。如果使用的鍵僅僅匹配少許行,該聯(lián)接類型是不錯的。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


